

In the era of big data, data science encompasses the entire cycle of extracting insights from data, including key stages such as data collection, processing, modeling, and prediction. Given the complex nature of data science projects and their deep reliance on human expert knowledge, automation holds significant potential for transforming the data science paradigm. With the rise of generative pre-trained language models, it has become increasingly important for large language model agents to handle complex tasks.
Traditional data processing and analysis largely depend on specialized data scientists, which is time-consuming and labor-intensive. If we could enable large language model agents to take on the role of data scientists, they could not only provide us with more efficient insights and analyses but also unlock unprecedented industrial models and research paradigms.
This way, as long as the data task requirements are specified, data science agents can autonomously handle vast amounts of data, discovering hidden patterns and trends behind the data. More broadly, they can provide clear strategies and code for model building, call machines for model deployment inference, and finally utilize data visualization to make complex data relationships clear.
Recently, a collaborative team from Jilin University, Shanghai Jiao Tong University, and University College London led by Wang Jun proposed DS-Agent, an agent positioned as a data scientist, aimed at handling complex machine learning modeling tasks in automated data science. Technically, the team adopted a classic artificial intelligence strategy—Case-Based Reasoning (CBR)—which endows the agent with the ability to “reference” successful past experiences to solve new problems.

-
Paper link: https://arxiv.org/pdf/2402.17453.pdf
-
Code link: https://github.com/guosyjlu/DS-Agent
-
Paper title: DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning
Research Background
In the open decision-making scenario of automated data science, current large model agents (e.g., AutoGPT, LangChain, ResearchAgent, etc.) struggle to guarantee a high success rate even when paired with GPT-4. The main challenge lies in the inability of large model agents to consistently generate reliable machine learning solutions, coupled with the issue of hallucination outputs. Of course, fine-tuning large models for the specific context of data science seems like a feasible strategy, but it introduces two new problems: (1) generating effective feedback signals requires training based on machine learning models, a process that takes a significant amount of time to accumulate adequate fine-tuning data; (2) the fine-tuning process requires executing backpropagation algorithms, which not only increases computational overhead but also significantly raises the demand for computational resources.
In this situation, the team decided to utilize Kaggle as a critical resource. As the world’s largest data science competition platform, it hosts a wealth of technical reports and code contributed by a community of experienced data scientists. To enable large model agents to efficiently leverage this expert knowledge, the team adopted a classic artificial intelligence problem-solving paradigm—Case-Based Reasoning.
The core mechanism of Case-Based Reasoning is to maintain a case library that continuously stores past experiences. When a new problem arises, CBR retrieves similar past cases from the library and attempts to reuse their solutions to address the new problem. Subsequently, CBR evaluates the effectiveness of the solutions and revises them based on feedback, with successful solutions being added to the case library for future reuse.
Based on this, the team proposed DS-Agent, which utilizes CBR to enable large model agents to analyze, extract, and reuse human expert insights from Kaggle, iterating and revising solutions based on actual execution feedback, thus achieving continuous performance improvement for data science tasks.
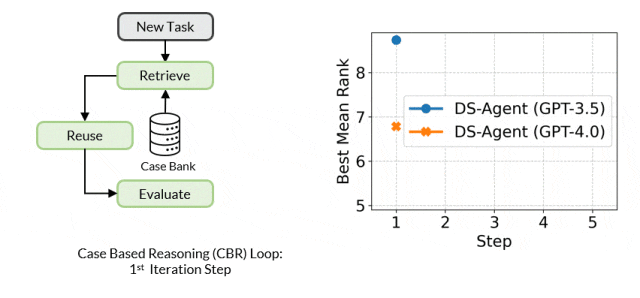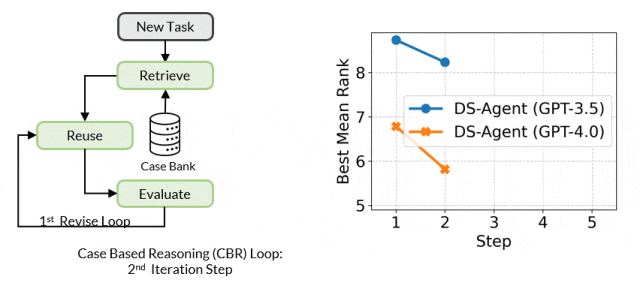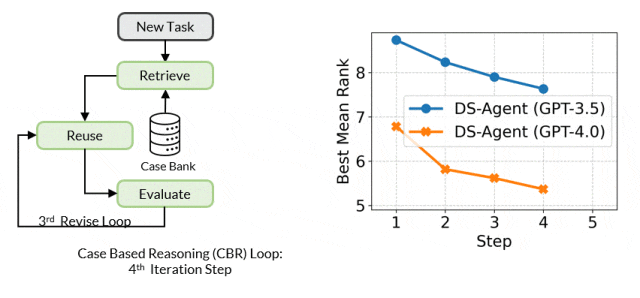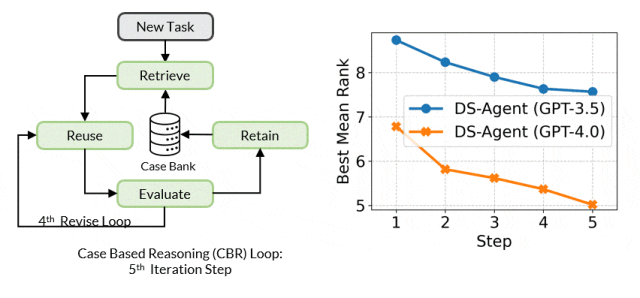
Framework Details
Overall, DS-Agent implements two modes to adapt to different application stages and resource requirements.
-
Standard Mode (Development Stage): DS-Agent employs CBR to build an automated iterative process that simulates the continuous exploration process of data scientists when building and adjusting machine learning models, striving for optimal solutions through constant experimentation and optimization.
-
Low Resource Mode (Deployment Stage): DS-Agent reuses successful cases accumulated during the development stage to generate code, significantly reducing the demand for computational resources and base model inference capabilities, making it possible for open-source large models to automate data science tasks.
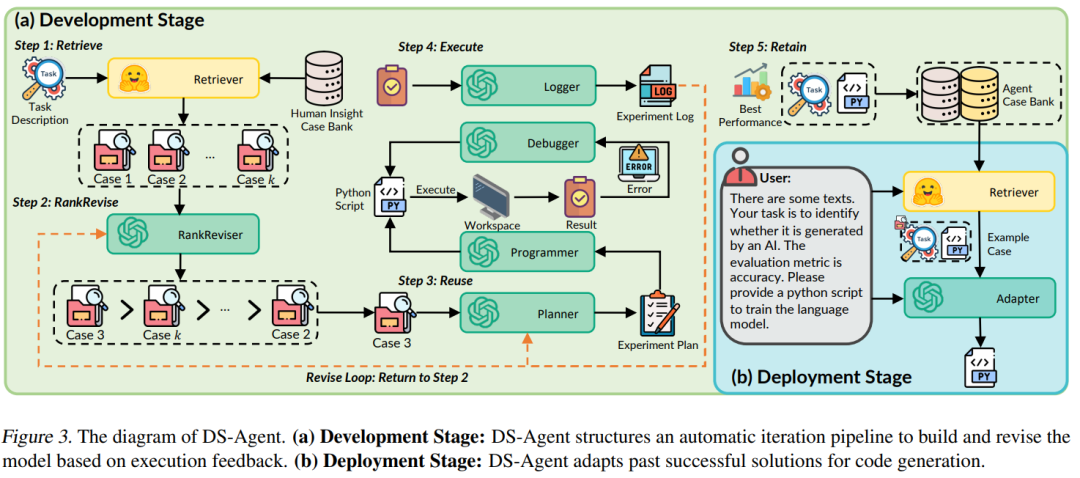
During the development stage, given a new data science task, DS-Agent first retrieves relevant human expert knowledge from Kaggle and builds an initial solution based on this. It then enters an iterative loop, training machine learning models through programming and debugging to achieve performance metrics on the test set. These feedback metrics become key criteria for evaluating and improving solutions. DS-Agent makes necessary modifications to the model design based on these metrics to seek optimal model designs. In this process, the most optimal machine learning solutions are stored in the case library to provide references for similar tasks in the future.
In the deployment stage, DS-Agent’s working mode becomes more direct and efficient. At this stage, it directly retrieves and reuses verified successful cases to generate code, eliminating the need to explore from scratch again. This not only reduces the demand for computational resources, allowing DS-Agent to respond quickly to user needs but also significantly lowers the requirements for the base model’s capabilities, providing high-quality machine learning models in a low-resource manner.
Experimental Setup
We collected 30 different data science tasks covering three major data modalities (text, tabular, and time series) and two core machine learning problems (classification and regression), designing various evaluation metrics to ensure task diversity.
Development Stage Experimental Results
In the development stage, DS-Agent achieved a 100% success rate for the first time in data science tasks using GPT-4; in contrast, DS-Agent, even with GPT-3.5, demonstrated a higher success rate than the strongest baseline, ResearchAgent, using GPT-4.
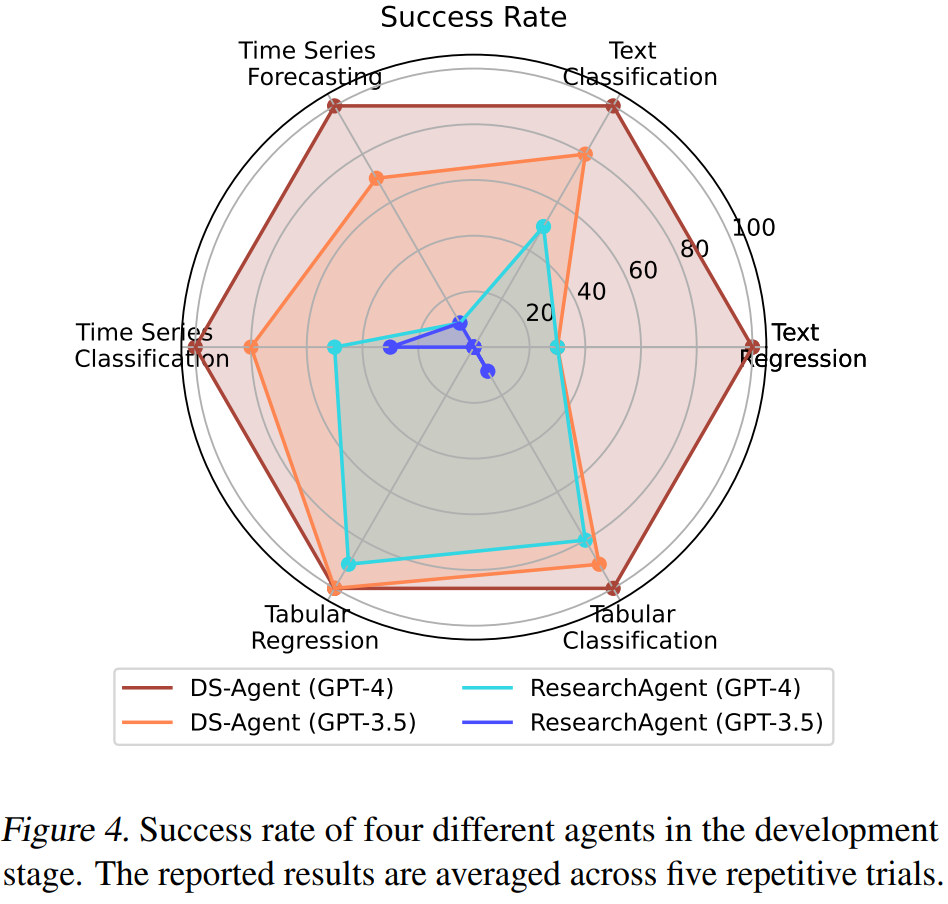
Moreover, DS-Agent achieved first and second place in evaluation metrics on the test set when using GPT-4 and GPT-3.5, significantly outperforming the strongest baseline, ResearchAgent.
Deployment Stage Experimental Results
In the deployment stage, DS-Agent achieved an almost 100% first-time success rate using GPT-4, while the open-source model Mixtral-8x7b-Instruct saw its first-time success rate leap from 6.11% to 31.11%.
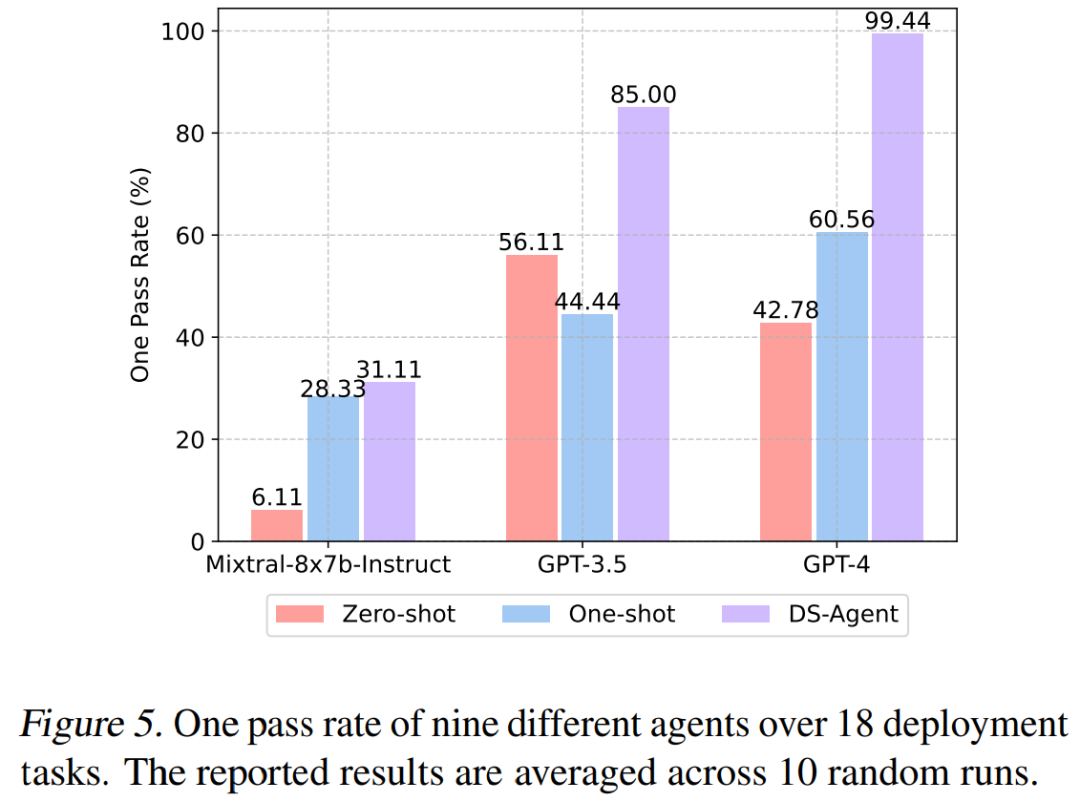
In the evaluation of test set metrics, DS-Agent achieved first and second place using GPT-4 and GPT-3; however, unfortunately, the open-source large model Mixtral-8x7b-Instruct, despite the support of DS-Agent, still did not surpass GPT-3.5.
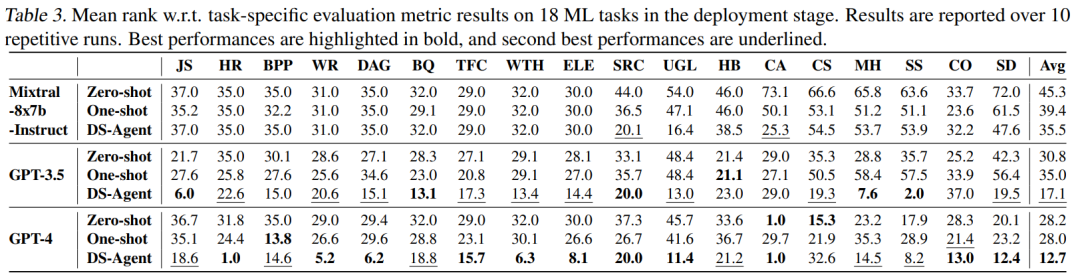
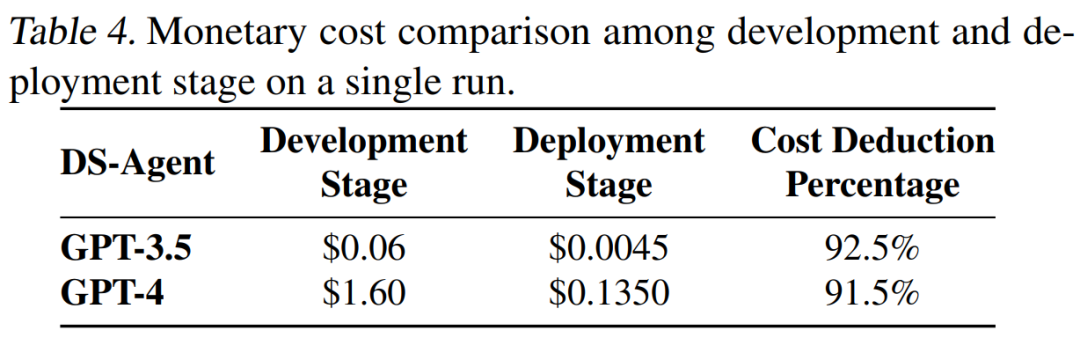
Finally, we analyzed the API call costs of DS-Agent under the two different modes. By comparison, we found that during the development stage, the single-call costs for DS-Agent when calling GPT-4 and GPT-3.5 were $1.60 and $0.06, respectively. However, in the deployment stage, costs were significantly reduced: the cost for a single use of GPT-4 dropped to just 13 cents, while the cost for a single use of GPT-3.5 was less than 1 cent. This means that in the deployment stage, we achieved over 90% cost savings compared to the development stage.
With DS-Agent, even if you have no programming knowledge or have not studied machine learning, you can easily tackle various complex data analysis challenges, gain deep business insights instantly, provide effective decision support, optimize strategies, and predict future trends, thus significantly improving the work efficiency of enterprise data departments. Imagine, marketers can quickly generate user profiles and marketing strategy analyses by simply describing their needs in natural language; financial analysts can say goodbye to the tediousness of manual modeling and instead discuss market trends with the agent… All of this may soon become a reality. Of course, automated data science is still in its infancy and large-scale application will take time. However, the emergence of DS-Agent undoubtedly presents an exciting future scenario. With the continuous development of artificial intelligence, cumbersome data analysis work may one day be taken over by AI, allowing humans to devote more time to insight-driven thinking and innovative decision-making.

Scan the QR code to add the assistant on WeChat
About Us
