Source: DeepHub IMBA
This article is about 3800 words, and it is recommended to read in 5 minutes. Since the release of diffusion models, the attention and papers on GANs have decreased significantly, but some ideas within them are still worth understanding and learning. Therefore, in this article, we will implement SN-GAN using PyTorch.
Spectral Normalization GAN (SN-GAN) is a type of Generative Adversarial Network that uses spectral normalization techniques to stabilize the training of the discriminator. Spectral normalization is a weight normalization technique that constrains the spectral norm of each layer in the discriminator. This helps prevent the discriminator from becoming too powerful, leading to instability and poor results.
SN-GAN was proposed by Miyato et al. (2018) in the paper “Spectral Normalization for Generative Adversarial Networks”. The authors demonstrated that SN-GAN performs better than other GANs on various image generation tasks.
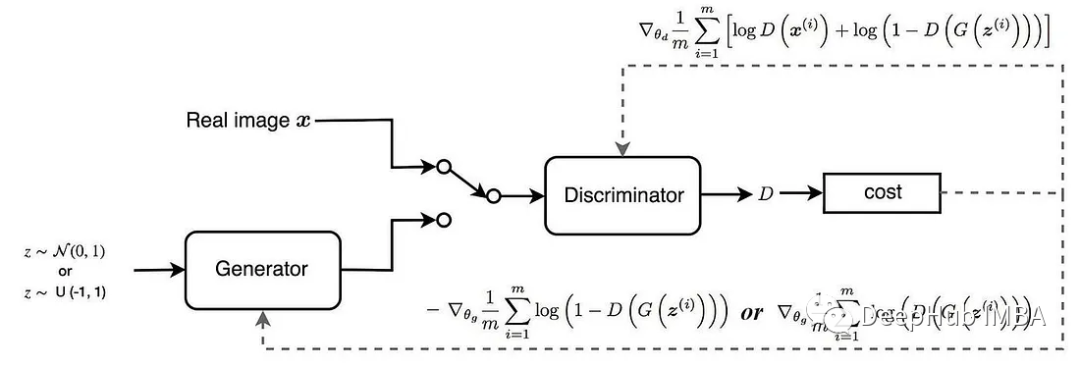
The training method of SN-GAN is the same as that of other GANs. The generator network learns to generate images that cannot be distinguished from real images, while the discriminator network learns to distinguish between real and generated images. These two networks are trained in a competitive manner, ultimately reaching a point where the generator can produce realistic images that deceive the discriminator.
Here are the advantages of SN-GAN compared to other GANs:
-
More stable and easier to train
-
Can generate higher quality images
-
More versatile, capable of generating a wider range of content.
Mode Collapse
Mode collapse is a common problem in the training of Generative Adversarial Networks (GANs). It occurs when the generator network of a GAN fails to produce diverse outputs and instead falls into specific modes. This leads to generated outputs that are repetitive, lacking diversity and detail, and sometimes completely unrelated to the training data.
There are several reasons for mode collapse in GANs. One reason is that the generator network may overfit the training data. This can happen if the training data is not diverse enough or if the generator network is too complex. Another reason is that the generator network may get stuck in a local minimum of the loss function. This can occur if the learning rate is too high or the loss function is poorly defined.
Many techniques have been previously used to prevent mode collapse. For example, using a more diverse training dataset. Using regularization techniques such as dropout or batch normalization is also important, as well as using appropriate learning rates and loss functions.
Wasserstein Loss
Wasserstein loss, also known as Earth Mover’s Distance (EMD) or Wasserstein GAN (WGAN) loss, is a loss function used for Generative Adversarial Networks (GANs). It was introduced to address some issues associated with traditional GAN loss functions, such as Jensen-Shannon divergence and Kullback-Leibler divergence.
Wasserstein loss measures the difference between the probability distributions of real data and generated data while ensuring it has certain mathematical properties. The idea is to minimize the Wasserstein distance (also known as Earth Mover’s Distance) between these two distributions. The Wasserstein distance can be thought of as the minimum “cost” required to transform one distribution into another, where “cost” is defined as the “work