Written by Pavel Senchanka, Google Software Engineering Intern

TensorFlow Lite is a leading solution for on-device inference of machine learning models. While a complete TensorFlow Lite training solution is still under development, we are eager to share a new example of on-device transfer learning. This article will introduce you to a practical approach for personalizing on-device machine learning models. Let’s dive into what problems transfer learning can solve and how it works.
Why Personalizing Machine Learning is Very Useful
Today, many machine learning solutions rely on large amounts of training data to solve problems. Image recognition, object detection, speech, and language models are all carefully trained on high-quality datasets, allowing these models to achieve as much generality and accuracy as possible. This scale can address many issues, but it cannot cater to the specific needs of every user through customization. Suppose you want to adjust the model based on user demands to improve the user experience. When sending user data to the cloud for training the model, you must be extremely cautious to prevent potential privacy breaches. In some cases, it may not be appropriate to send data to a central server for training, as we need to consider power consumption, data throttling, and privacy issues. However, if you train the data directly on the device, you do not have to worry about these issues, and you can enjoy the following benefits: you can keep privacy and sensitive data on the device, saving bandwidth, and you can train data even without a network connection. However, you will also face a challenge: training requires a massive amount of data samples, which can be difficult to obtain on-device. Training a deep network from scratch in the cloud can take days, making this method unsuitable for on-device applications. To avoid training an entirely new model from scratch, we adapt a pre-trained model to similar problems, a process known as transfer learning.
What is Transfer Learning?
Transfer learning is a technique that involves using a pre-trained model on a “data-rich” task and retraining some layers of that model (usually the last layer) to handle another “data-scarce” task. For example, you can take an image classification model (like MobileNet) that has been pre-trained on a set of categories (such as those in ImageNet) and then retrain the last few layers of that model to handle another task. Transfer learning is not limited to the image domain; similar techniques can also be applied to text or voice domains.
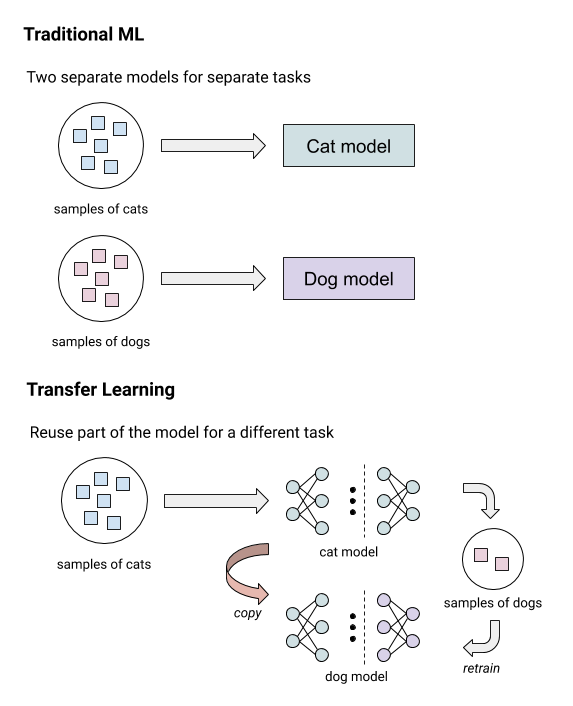
This example illustrates the conceptual difference between traditional machine learning (ML) and transfer learning.
With transfer learning, you can easily train personalized models on-device, even with limited training data and computational resources, while also protecting user privacy.
Training an Image Classifier on Android Devices
In our released sample project, there is an Android application that learns to classify camera images in real-time. In this application, we can take sample photos for different target categories and then train them on-device.

The application uses transfer learning techniques on the MobileNetV2 quantized model, which we have pre-trained with ImageNet and replaced the last few layers with a trainable softmax classifier. You can recognize four arbitrary new categories by training the last few layers, and the accuracy depends on the “difficulty” of the categories to be captured. We observed that even with just a few dozen samples, good results can be achieved. (Keep in mind that we pre-trained the MobileNetV2 model with 1.3 million samples from ImageNet!). This application can run on all compatible latest Android devices (with system version 5.0 and above), so we encourage you to give it a try. The released sample includes project configurations compatible with Android Studio. To run the application, simply import the project in Android Studio, connect your device, and click “Run”. For more detailed instructions, please refer to the project’s README file. Feel free to share your experiences with us using the hashtags #TFLite, #TensorFlow, and #PoweredByTF!
-
READMEhttps://github.com/tensorflow/examples/blob/master/lite/examples/model_personalization/README.md
Using the Transfer Learning Pipeline for Your Own Tasks
The new GitHub example includes a set of reusable tools to help you easily create and use your own personalized models. This example consists of three different independent parts, each responsible for one step in the transfer learning pipeline.
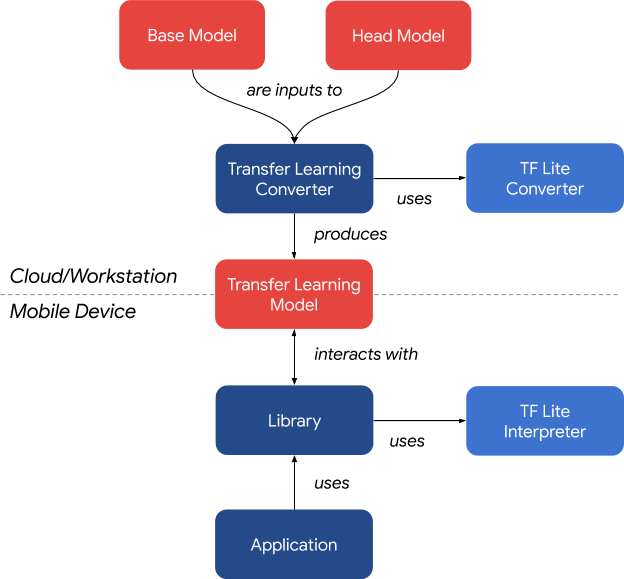 Converter To generate a transfer learning model for your task, you need to select two types of models to form it:
Converter To generate a transfer learning model for your task, you need to select two types of models to form it:
- Base model: Typically a deep neural network pre-trained on common data-rich tasks.
-
Head model: This model takes the features generated by the base model as input and learns to handle the target (personalization) task. This model is usually a simple network consisting of several fully connected layers.
You can define your model in TensorFlow or use some shortcuts provided by the converter to easily complete model definition. Specifically, for a head model that includes a fully connected layer and a softmax activation function, the SoftmaxClassifier is a shortcut provided by the model that is specially optimized to better fit TensorFlow Lite. The transfer learning converter provides CLI and Python API, so you can use the converter in your own programs or notebooks.
Android Library
The transfer learning model generated by the transfer learning converter cannot be directly used with the TensorFlow Lite interpreter. You need to use an intermediate layer to handle the model’s non-linear lifecycle. Currently, we only provide an Android implementation of this intermediate layer. The Android library is hosted as part of the example but is located in a separate Gradle module, making it easy to integrate into any Android application. For more details on the transfer learning pipeline, please refer to the detailed instructions in the README.
-
READMEhttps://github.com/tensorflow/examples/blob/master/lite/examples/model_personalization/README.md
Future Work
In the future, we may work on improving the transfer learning pipeline as well as developing a complete training solution for TensorFlow Lite. Today, we simply introduced the transfer learning pipeline in the form of a GitHub example, and we will provide a complete training solution in the future. Next, we will adjust the transfer learning converter to generate a single TensorFlow Lite model that can run without additional runtime libraries. Thank you for reading this article! Please share any projects you undertake using this pipeline with us through the TensorFlow Lite Google Forum (https://groups.google.com/a/tensorflow.org/forum/#!forum/tflite) .
Acknowledgments
As a team effort, the success of this project is thanks to Yu-Cheng Ling and Jared Duke for their guidance during this time, and I also want to thank Eileen Mao and Tanjin Prity, as well as other members of the Google TensorFlow Lite team, including interns.