Author / Hangzhou Danna Technology Co., Ltd.

Ai Homework is an APP that automatically grades math homework using AI technology. In just one year since its launch, it has accumulated over ten million users, helping many teachers and parents save time and improve efficiency.
Within the Ai Homework APP, there is a feature called “Mental Calculation Practice,” which aims to provide children with a lightweight and convenient method to reinforce their mental math skills directly on their phones. As shown in the figure below:
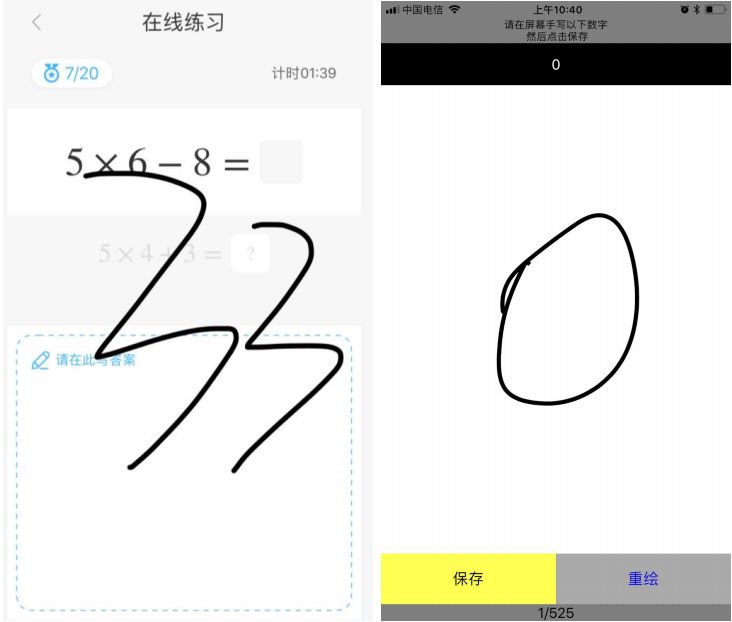
To recognize handwritten strokes on the screen, our initial method was to track the writing trajectory, which is a relatively traditional and classic approach. This method relies on rules and does not require a large amount of training data. However, through our experiments, we found that while this method works well for a small number of digits, it performs poorly for larger numbers, especially in cases where digits are written together or the writing order is not standard.
At this point, we decided to use Deep Learning to solve the problem, and we needed to address the issues of training data, model, and mobile deployment.
First is the training data, which is an unavoidable issue in deep learning. To this end, we specifically developed a small tool (iOS / Android) that allows our annotators to easily generate training data. This tool randomly generates some numbers (including decimals and fractions), and the annotators write the prompted numbers on the screen, which can then be conveniently saved to our server. We collected the first batch of raw data, consisting of about 5000 training images.
Next is the model. Since the model needs to run on mobile devices, both the input image size and the model itself need to be relatively compact. Based on the portrait aspect ratio, we ultimately processed all images to a size of 60×100 (height x width). The overall framework of the model is a seq2seq model, which was originally used by Google to solve NLP-related problems. We made some adjustments to adapt it for image OCR.
First, we need a basic model to generate features, and we ultimately chose MobileNet. The core of the MobileNet model is to factor the standard convolution operation into a depthwise convolution and a 1*1 convolution (referred to as pointwise convolution). In simple terms, it splits the original convolution layer into two layers: the first convolution layer performs convolution on each input channel with its corresponding filter, while the second layer is responsible for combining the results of the previous layer’s convolution. MobileNet can significantly reduce computation time and parameter count while maintaining accuracy. As the name suggests, we believe using this as the backbone network can yield good performance on mobile devices, and this model has a standard implementation in TensorFlow’s model zoo, along with a pre-trained model. The rich model implementations were one of the important reasons we chose to implement it using TensorFlow.
After obtaining the image features, we performed a standard Encoder->Decoder process using LSTM RNN. Thanks to the rich implementations in TensorFlow, this entire process can be easily implemented by calling the seq2seq-related interfaces in TensorFlow. However, there were some changes to the interfaces of seq2seq after TensorFlow 1.0, and we used the updated interfaces.
Next is how to deploy the model to the client for execution, which presented us with many choices. Overall, we needed to choose between using TensorFlow Mobile or TensorFlow Lite. Additionally, on the iOS side, we needed to consider whether to convert the model to an iOS CoreML model. Since CoreML only started supporting from iOS 11, we quickly ruled out this option. At the time we were developing this feature, TensorFlow had just released version 1.4 (now it’s 1.12), and Lite was still a brand new thing. The biggest issue was its insufficient support for various ops, and at that time, the official website recommended using the Mobile version in production environments. Therefore, despite the various advantages of Lite, we chose Mobile.
The documentation for TensorFlow Mobile is relatively comprehensive, and we did not encounter significant obstacles during the deployment process. One point to note is that we needed to use the print_selective_registration_header tool to analyze the operators actually used in the model, which greatly reduced the size of the generated runtime library.
Thus, our first version was successfully launched and ran stably, but we continued to pay attention to the developments of Lite. After some consideration, especially after hearing more about TensorFlow Lite at the Google Developer Conference in October 2018, we decided to replace the Mobile version with Lite, primarily based on the following considerations:
-
A smaller runtime library size. The runtime library generated by TensorFlow Lite is very small, removing many unnecessary dependencies. For example, the model uses the new lightweight FlatBuffers format, while the previous protobuf required many dependency libraries. At the same time, TensorFlow Lite implements the core operators of the original TensorFlow in a more lightweight manner, effectively reducing the size of the runtime library.
-
Faster runtime speed. Many core operators in TensorFlow Lite are optimized specifically for mobile platforms, and through NNAPI, it transparently supports GPU acceleration, allowing automatic fallback to CPU computation on older devices.
-
The model quantization feature of TensorFlow Lite allows the model to be quantized to int8, reducing the model size to one-fourth of its original size with almost no loss in computational accuracy.
However, we still encountered many difficulties. Mainly:
-
TensorFlow Lite does not yet support control flow, which means that the dynamic_decode in TensorFlow’s new seq2seq interface cannot be correctly exported for execution.
-
The support for LSTM in TensorFlow Lite is not comprehensive enough, such as the forget bias parameter not being supported.
-
Some operators we used are not supported in TensorFlow Lite, such as GatherTree, etc.
Implementing control flow in TensorFlow Lite is not an easy task and cannot be directly achieved through custom ops. Ultimately, we transformed dynamic decoding into static unfolding, which slightly sacrificed some performance but resolved this issue. For the forget bias issue, we cleverly added the forget bias to the LSTM forget gate’s bias during parameter recovery, eliminating the need to modify TensorFlow Lite’s code. Other issues can be resolved through custom ops, which is relatively easier.
Finally, we used toco to export the graph pb to TensorFlow Lite format, and the next step was to integrate it into the mobile application. At this stage, we did not encounter many obstacles. With the experience from integrating TensorFlow Mobile previously, we quickly completed the integration. During the specific implementation, we encapsulated the recognition interface, so that when we migrated from TensorFlow Mobile to TensorFlow Lite, our colleagues in client development hardly needed to change the code to use the new interface.
After completing the migration from TensorFlow Mobile to TensorFlow Lite, we improved the inference speed by 20%, and the model size was reduced by 75%, which is very attractive.
As mobile computing power continues to enhance, more and more deep learning models can run on mobile devices. Currently, TensorFlow Lite is also rapidly developing and iterating, and we believe that TensorFlow Lite will continue to improve in more practices.
Thanks to the TensorFlow Lite team for their support during our development process, especially to technical experts Gu Renmin and Liu Renjie for providing us with many helpful materials and references. We hope for more opportunities for collaboration in the future.