
Madio.net
Mathematics China
Currently, building a Convolutional Neural Network (CNN) is generally done directly using deep learning frameworks such as Pytorch or Tensorflow, which is quite simple. However, if you’re writing the backpropagation process from scratch, it is much more complicated than BP networks, as it involves more than just matrix multiplication.
The goal is to implement CNN from scratch.
At the beginning, I searched for blogs related to the backpropagation of convolutional neural networks online and discovered several issues:
-
The formulas are really hard to comprehend, with a lot of variables, and it was only after implementing it myself that I found the time complexity of convolution is quite high, involving several layers of for loops; -
The backpropagation of the convolutional layer involves an operation with the weight matrix rot180 when calculating the gradient of the input from the output gradient, and there are also issues with padding the gradient, as seen in the blog on the backpropagation algorithm for convolutional neural networks (CNN) – Liu Jianping Pinard – Blog Garden: https://www.cnblogs.com/pinard/p/6494810.html (Highly recommend Liu Jianping’s blog), as shown below.
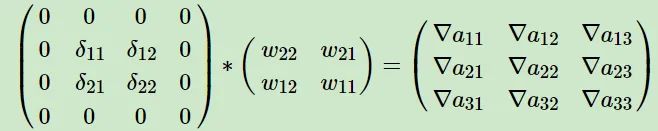
This example is not wrong, but it is just a special case. If the stride is greater than 1, it not only requires padding 0 around the edges, but also padding 0 between data points. The specific process is exactly the same as the forward process of transposed convolution. However, even if this can be done correctly, the padding operation is very costly. Assuming stride = 2, then about half of the calculations involve multiplying by 0, which is meaningless computation. I personally think this approach is not advisable and have adopted other strategies.
Step by step implementation encountered not only these two issues, but overcame them one by one. The key to the entire process is – grit your teeth and write honestly, don’t just look at the formulas.
This has been my long-standing wish, and I finally realized it. Throughout the process, I also revisited some C++ pitfalls and optimization techniques, gaining a clearer understanding of the forward and backward processes of convolution and how to build deep learning workflows, which was very rewarding.
Outline
Convolutional Neural Networks (1) Tensor Definition: https://zhuanlan.zhihu.com/p/463673933
Convolutional Neural Networks (2) From Image to Tensor: https://zhuanlan.zhihu.com/p/468161119
Convolutional Neural Networks (3) ReLU Layer: https://zhuanlan.zhihu.com/p/468161821
Convolutional Neural Networks (4) Pooling Layer: https://zhuanlan.zhihu.com/p/468163843
Convolutional Neural Networks (5) Convolutional Layer: https://zhuanlan.zhihu.com/p/468164733
Convolutional Neural Networks (6) Linear Layer: https://zhuanlan.zhihu.com/p/468165951
Convolutional Neural Networks (7) Building CNN Network Structure: https://zhuanlan.zhihu.com/p/469475509
Convolutional Neural Networks (8) Training CNN: https://zhuanlan.zhihu.com/p/468177334
Code
https://github.com/hermosayhl/CNN
Environment
-
Windows 11 -
>=C++17 (TDM GCC 10.3.0: https://jmeubank.github.io/tdm-gcc/download/) -
OpenCV 4.5.2 -
Build Tool CMake
Dataset
The small image classification dataset used is from cat-dog-panda: https://www.kaggle.com/ashishsaxena2209/animal-image-datasetdog-cat-and-panda, excluding cat (as cat and dog are relatively more difficult), and then randomly selecting 1000 bird images from the CUB-200 bird dataset: http://www.vision.caltech.edu/visipedia/CUB-200.html to create a small three-class dataset. The train: valid: test ratio is 8:1:1.
Network Model
I don’t even know what kind of network structure this is, just designed it at random (as long as it runs), with only convolutional layers, max pooling layers, ReLU layers, Softmax layers, and Linear fully connected layers. It is simpler than AlexNet, with an accepted input size of 224x224x3, outputting 3 values, and obtaining probabilities through softmax. The loss function is cross-entropy, and the optimization method is SGD (Stochastic Gradient Descent). Finally, it can achieve an accuracy of about 0.91 on the test set, which is not high, but at least it runs through.
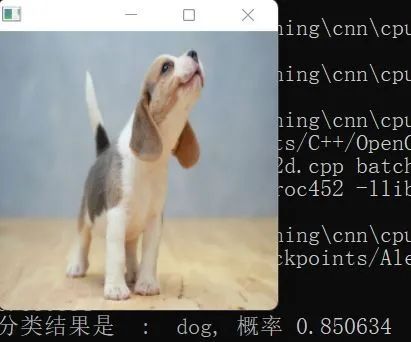
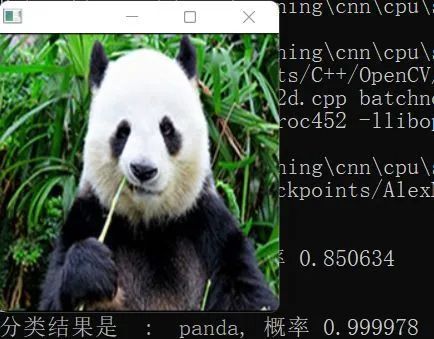
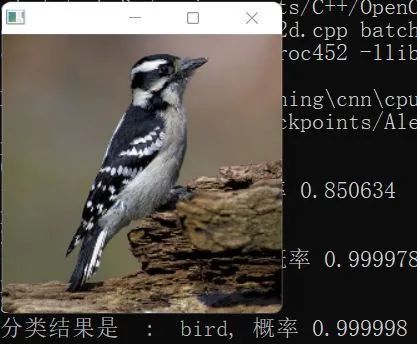
Although I also wrote BatchNorm and DropOut layers later, training was not an issue. The forward and backward propagation of these two layers are correct, but during the valid and test phases, it overfitted… I tried various methods found online, but they all failed, leaving this as an issue.
I also attempted Grad-CAM visualization of the neural network, achieving results that differ slightly from the details in the paper, as shown in the example below, classified as bird.

Click below
Follow us
— THE END —