
Jishi Guide
Choosing the right architecture is crucial for developing visual large models.>> Join the Jishi CV technology exchange group to stay at the forefront of computer vision
With OpenAI’s GPT-4o leading the way and Google’s series of powerful models following, advanced multimodal large models are making waves.
While other practitioners are in awe, they are once again pondering how to catch up with these super models.
At this moment, a paper by HuggingFace and the Sorbonne University in France summarizes the key experiences for constructing visual large models, pointing developers in a clear direction.

These experiences cover multiple aspects such as model architecture selection, training methods, and training data. After extensive comparisons, the authors provide a detailed summary of the core points, including:
-
Choosing the right architecture is crucial for developing visual large models.
-
The impact of language models on overall performance is greater than that of visual modules.
-
Using a staged pre-training strategy is more beneficial for building model capabilities.
-
Training data should include various types and pay attention to the balance between them.
It can be said that HF’s ability to create SOTA visual models of the same scale, Idefics2, relies on these experiences.
Idefics2 is built on Mistral-7B, with a total of 8B parameters, capable of accurately recognizing handwritten fonts.

Professionals have commented that this is a very good survey report, which is very helpful for developers of visual models, but they also remind not to treat it as a one-size-fits-all solution.

Of course, some have jokingly said that all architectures and data are just fluff, and having a GPU is the most critical.

There is some truth to this, but jokes aside, let’s take a look at what experiences HuggingFace has provided us.
From SOTA Model Development Practice
The experiences in HuggingFace’s paper come from the development process of the visual model Idefics2.
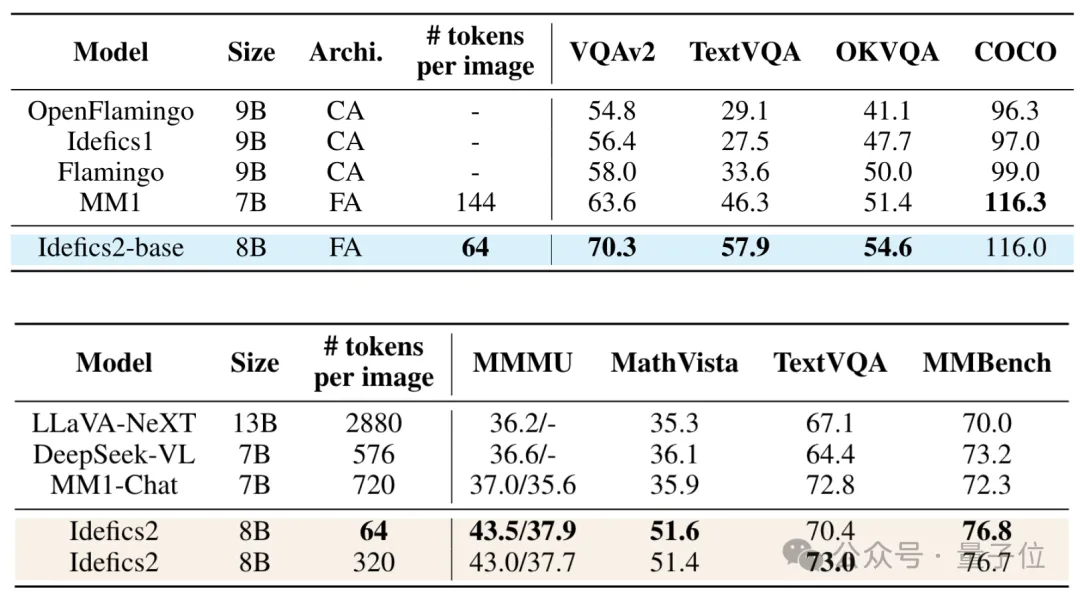
Compared to the previous generation Idefics1 and SOTA models like Flamingo of the same scale, Idefics2 performs excellently on multiple datasets, even surpassing larger 13B models.
At the same time, compared to MM1, which slightly outperforms Idefics2 on the COCO dataset, Idefics2 significantly reduces the tokens consumed per image.
From the development practice of Idefics2, HuggingFace brings us experiences that include at least the following aspects:
-
Selection of backbone and architecture
-
Training methods and strategies
-
Diversity and processing strategies of data
The Impact of Language Models on Overall Performance is Greater
Current visual large models mainly adopt the form of language model + visual encoder for development. The authors evaluated the impact of both on overall performance.
The results show that the quality of the language model is more important than that of the visual model.
With the same parameter count, using a better language model (e.g., replacing Llama-7B with Mistral-7B) can significantly improve the performance of the visual large model on downstream tasks.
The improvement brought by upgrading the visual encoder is limited, so when trade-offs are necessary, the best practice is to prioritize stronger language models.

Of course, this does not mean that upgrading the visual encoder is useless. When conditions permit, choosing a better visual encoder can also bring certain performance improvements.
Additionally, it should be noted to choose one that matches the downstream task. For example, in text recognition tasks, one should use a visual encoder that supports variable resolution; if the task requires high inference speed, a lighter model can be chosen.
In practical applications, inference speed and memory usage are also factors that need to be weighed. The SigLIP-SO400M used in Idefics2 strikes a good balance between performance and efficiency.
Choose Architecture Type Based on Requirements
Regarding architecture selection, this paper discusses two common types: fully autoregressive and cross-attention.
The fully autoregressive architecture generates each output through an autoregressive method, considering the dependencies of the entire sequence; the latter allows the model to dynamically focus on different parts of another modality while processing one modality, achieving more flexible inter-modal interaction.
In specific work, the authors found that which architecture performs better depends on whether the pre-trained backbone is frozen.
(In simple terms, if the pre-trained backbone participates in the formal training process, it is non-frozen; if it does not participate, it is frozen)
If it is not frozen, the fully autoregressive architecture performs better; conversely, the cross-attention architecture is better.
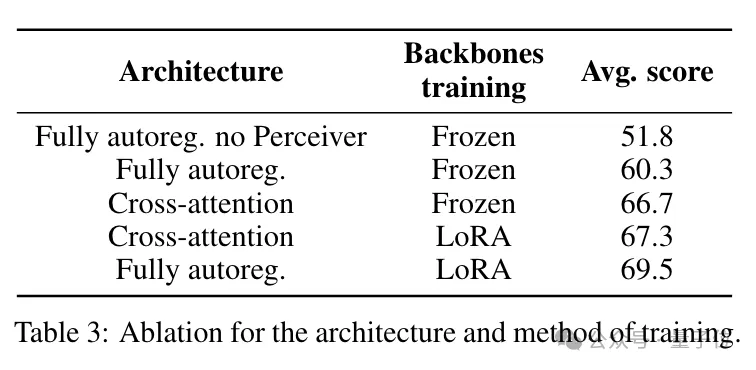
Whether to freeze the backbone depends on the developer’s focus. Under limited resources, if high performance and low latency are required, freezing is more appropriate; if a higher degree of flexibility and adaptability is desired, a non-frozen training method should be chosen.
Specifically for Idefics2, the choice was made not to freeze the backbone, thus adopting the fully autoregressive architecture.
Training Phase Experiences
Choosing the right architecture is certainly important, but the training process is also essential. During the training process of Idefics2, the authors summarized these experiences for our reference:
First, a staged pre-training strategy is adopted overall, starting with lower resolution images, then introducing higher resolution PDF documents. This approach can gradually build the model’s various capabilities.
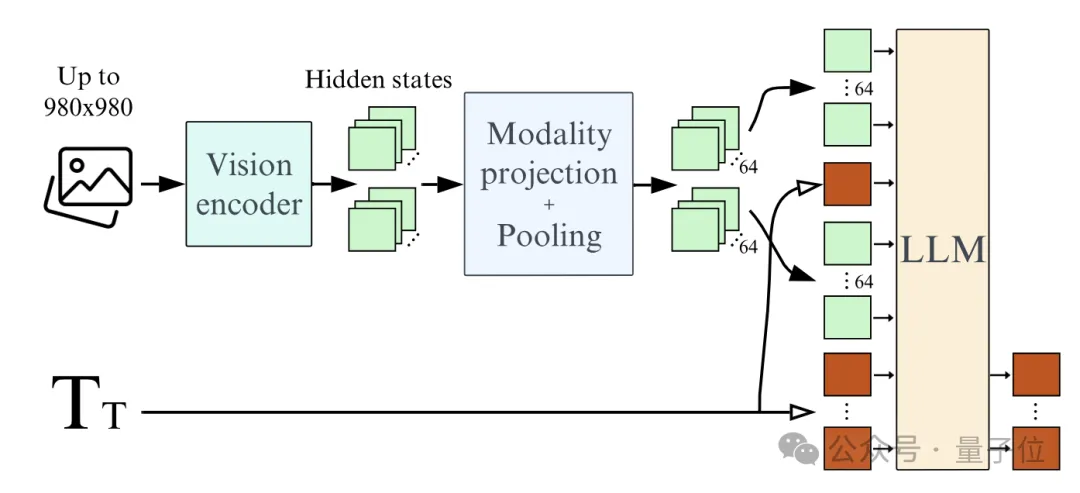
Second, using Learned Pooling instead of directly feeding image features into the language model can significantly reduce the number of image tokens, greatly improving training and inference efficiency while also enhancing performance.
Third, data augmentation is employed, where images are split into multiple sub-images during training. This can trade computation time for stronger performance during inference, especially effective in tasks like text recognition, though not all images need this treatment.
Fourth, using more diverse data and tasks during instruction fine-tuning can enhance the model’s generalization and robustness.
Additionally, to stabilize training, when the pre-trained unimodal backbone participates in training (non-frozen), the authors employed LoRA technology to adapt the pre-trained parameters.
Diversity of Data and Processing Strategies
Besides the training process itself, the chosen data also significantly impacts model performance.
From the collection phase, it is essential to select various types of data. For instance, Idefics2 uses data from three categories—document-image alignment (e.g., web pages), image-text pairs (e.g., image captions), and OCR-labeled PDF documents.
The proportions of various data types should also be appropriately balanced based on actual needs, rather than simply dividing them equally.
As for data scale, the more the better, provided low-quality data is filtered out.
Of course, collection is just one step in obtaining training data; to train the model well, certain processing and handling are also required.
Different preprocessing and augmentation strategies should be applied to different types of data. For example, higher resolution images are necessary for OCR data, while lower resolution can be used for other data.
It is important to maintain the original aspect ratio and resolution of images when processing, which can significantly save computational costs during training and inference while enhancing model adaptability.
If you find these experiences insightful, you can read the original paper for more details, and feel free to share your development experiences in the comments.
Paper link:https://arxiv.org/abs/2405.02246

Reply “Dataset” in the public account backend to get 100+ resources organized for deep learning in various directions
Jishi Essentials

Click to read the original text and enter the CV community
Gain more technical insights