
AliMei’s Guide: ICCV is regarded as one of the top three conferences in the field of computer vision. As one of the highest-level conferences in computer vision, its proceedings represent the latest development directions and levels in the field. Alibaba has multiple papers selected for this year’s conference, and the paper interpreted in this article is one of the selected papers co-authored by Alibaba’s iDST and several institutions, aiming to teach machines to understand images and express them as completely as possible.

Accurate Product Description: The Union of Computer Vision and Natural Language Processing
In recent years, with the rapid development of deep learning technologies, researchers have begun to attempt to combine the relatively independent fields of computer vision (Vision) and natural language processing (Language) to achieve some tasks that were previously considered very difficult, such as “Visual-Semantic Embedding”. This task requires representing images and sentences as fixed-length vectors, which can then be embedded into the same vector space. Thus, through nearest neighbor search in this space, matching and retrieval of images and sentences can be achieved.
A typical application of visual-semantic embedding is image captioning: for any input image, find the most matching sentence in the space to describe the image content. In e-commerce scenarios, when a seller publishes a product on Taobao, this algorithm can automatically generate a descriptive text based on the image uploaded by the seller, for the seller to edit and publish. For example, visual-semantic embedding can also be applied to “Cross-media Retrieval”: when users input a descriptive text in an e-commerce search engine (such as “summer loose bohemian maxi beach skirt”, “artsy fresh doll collar flutter sleeve floral A-line dress”, etc.), through text-image joint analysis, the most relevant product images can be found and returned to users from the product image database.
Previous Limitations: Only Able to Embed Short Sentences for Simple Image Descriptions
Previous visual-semantic embedding methods often could only embed relatively short sentences, thus only providing simple and rough descriptions of images. However, in practical applications, people hope to obtain more detailed and accurate descriptions of images (or salient regions of images). As shown in Figure 1, we not only want to know who is doing what, but also want to know the appearance of the person, surrounding objects, background, time, and place.

Figure 1 Problems with Existing Methods
Existing method: “A girl is playing a guitar.“
Our proposed method: “a young girl sitting on a bench is playing a guitar with a black and white dog nearby.“
To achieve this goal, we propose a framework: the first step is to find some salient regions in the image and describe each region with descriptive phrases; the second step is to combine these phrases into a very long descriptive sentence, as shown in Figure 2.

Figure 2 Our Proposed Framework
For this purpose, when training the visual-semantic embedding model, we need to embed not only the entire sentence into the space but also various descriptive phrases within the sentence. However, previous visual-semantic embedding methods typically used recurrent neural network models (such as LSTM (Long Short-Term Memory) models) to represent sentences. The standard LSTM model has a chain structure: each unit corresponds to a word, and these words are arranged in a sequence according to their occurrence order, with information flowing from the first word along this chain to the last. The last node contains all the information and is often used to represent the entire sentence. Clearly, the standard LSTM model is only suitable for representing entire sentences and cannot represent phrases contained within a sentence, as shown in the figure.
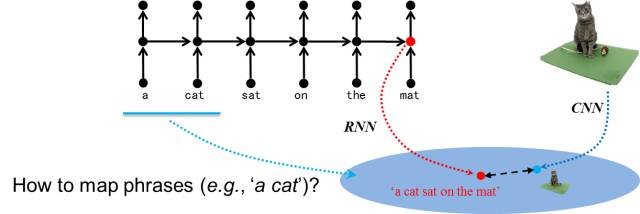
Figure 3 Problems with Chain Structure
Innovative Method of the Paper: Hierarchical LSTM Model Proposed
This paper proposes a multimodal, hierarchical LSTM model (Hierarchical Multimodal LSTM). This method can simultaneously embed the entire sentence, phrases within the sentence, the entire image, and salient regions within the image into the semantic space, and automatically learn the corresponding relationships between “sentence-image” and “phrase-image region”. In this way, we generate a denser semantic space that contains a large number of descriptive phrases, allowing for more detailed and vivid descriptions of images or image regions, as shown in the figure.
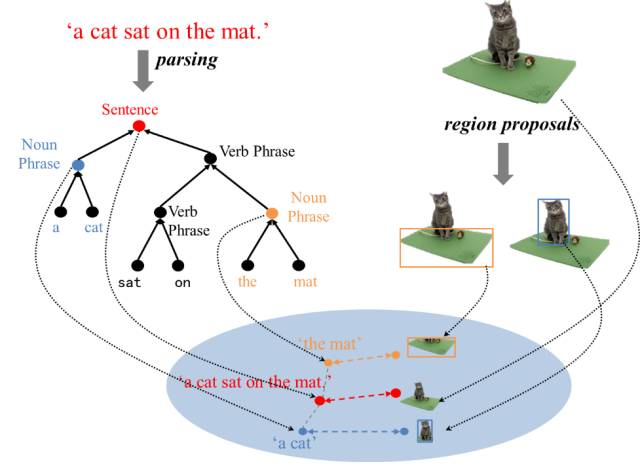
Figure 4 The Proposed Multimodal Hierarchical Structure
The innovation of our method lies in the proposal of a hierarchical LSTM model, where the root node corresponds to the entire sentence or image, the leaf nodes correspond to words, and the intermediate nodes correspond to phrases or regions within the image. This model can jointly embed images, sentences, image regions, and phrases, and through the tree structure, it can fully explore and utilize the relationships between phrases (parent-child phrase relationships). The specific network structure is shown in the figure below.
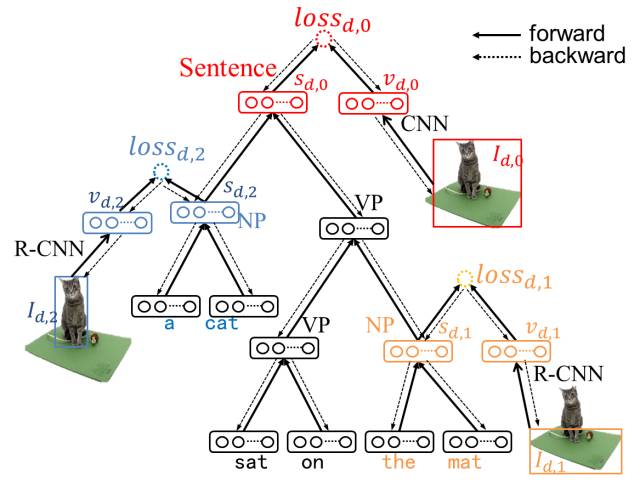
Figure 5 Network Structure
For each phrase and corresponding image region, a loss function is introduced to minimize the distance between the two, with network parameter learning conducted through a structure-based backpropagation algorithm.
Comparisons on Image-Sentence Datasets
|
Image Annotation |
Image Search |
|||||
|
R@1 |
R@10 |
Med r |
R@1 |
R@10 |
Med r |
|
|
SDT-RNN |
9.6 |
41.1 |
16 |
8.9 |
41.1 |
16 |
|
DeFrag |
14.2 |
51.3 |
10 |
10.2 |
44.2 |
14 |
|
SC-NLM |
14.8 |
50.9 |
10 |
11.8 |
46.3 |
13 |
|
DeepVS |
22.2 |
61.4 |
4.8 |
15.2 |
50.5 |
9.2 |
|
NIC |
17.0 |
56.0 |
7 |
17.0 |
57.0 |
7 |
|
m-RNN-vgg |
35.4 |
73.7 |
3 |
22.8 |
63.1 |
5 |
|
DeepSP |
35.7 |
74.4 |
N/A |
25.1 |
66.5 |
N/A |
|
Ours |
38.1 |
76.5 |
3 |
27.2 |
68.8 |
4 |
Figure 6 Comparisons on the Flickr30K Dataset
|
Image Annotation |
Image Search |
|||||
|
R@1 |
R@10 |
Med r |
R@1 |
R@10 |
Med r |
|
|
Random |
0.1 |
1.1 |
631 |
0.1 |
1.0 |
500 |
|
DeepVS |
36.4 |
80.9 |
3 |
28.1 |
76.1 |
3 |
|
m-RNN |
41.0 |
83.5 |
2 |
29.0 |
77.0 |
3 |
|
DeepSP |
40.7 |
85.3 |
N/A |
33.5 |
83.2 |
N/A |
|
Ours |
43.9 |
87.8 |
2 |
36.1 |
86.7 |
3 |
Figure 7 Comparisons on the MS-COCO Dataset
It can be seen that our method achieves good results on several public datasets.
Comparisons on Image Region-Phrase Datasets
We provide a labeled image region-phrase dataset MS-COCO-region, in which some salient objects are manually annotated, and relationships between these objects and phrases are established.
|
Region Annotation |
||||
|
R@1 |
R@5 |
R@10 |
Med r |
|
|
Random |
0.02 |
0.12 |
0.24 |
3133 |
|
DeepVS |
7.2 |
18.1 |
26.8 |
64 |
|
m-RNN |
8.1 |
20.6 |
28.2 |
56 |
|
Ours |
10.8 |
22.6 |
30.7 |
42 |
Figure 8 Comparisons on the MS-COCO-region Dataset
The following are the visual results of our method, demonstrating that our phrases are highly descriptive.

Additionally, we can learn the correspondence between image regions and phrases, as shown below.


You May Also Like
Click on the image below to read

This is a challenge letter to programmers for 1024.

Deep analysis of Alibaba Group’s big data.

What top projects did Alibaba open source at this Cloud Summit?

Follow “Alibaba Technology”
Keep up with the pulse of cutting-edge technology