Cost is the invisible competitive advantage of large models.
Author|Liu Yangnan
Editor|Zhao Jian
Today, the Tsinghua University-affiliated large model company “Mianbi Intelligent” released its first flagship large model “Mianbi MiniCPM”, which has been aptly named “Little Cannon”.
According to Mianbi Intelligent’s co-founder and CEO Li Dahai, the parameter scale of Mianbi MiniCPM is 2B, using 1T selected data, and its performance surpasses the popular French large model Mistral-7B, competing directly with LLama 2-13B. The company behind Mistral-7B, Mistral AI, is referred to as the “European version of OpenAI”.
The core realization of Mianbi MiniCPM is to achieve stronger performance with a smaller size and lower cost. “Small size is the ultimate arena of model technology,” said Li Dahai.
The so-called “edge large model” means that the model service is deployed on local terminals such as mobile phones, computers, and IoT devices, with the inference process completed directly by the terminal chip without the need for internet connectivity. In the second half of 2023, major smartphone manufacturers both domestic and abroad, including Huawei, Xiaomi, Vivo, OPPO, Honor, Apple, and Samsung, have all laid out plans for edge large models, and Mianbi Intelligent is the first large model manufacturer to layout edge models.
As the competition for edge large models intensifies, why are so many manufacturers eager to participate? Why has Mianbi Intelligent, with its core strategy of “large model + Agent”, taken the lead in laying out edge large models?
After the press conference, media outlets such as “Jiazi Guangnian” engaged in in-depth discussions with Mianbi Intelligent co-founder and CEO Li Dahai, Mianbi Intelligent co-founder and Tsinghua University tenured associate professor Liu Zhiyuan, Mianbi Intelligent CTO Zeng Guoyang, and Tsinghua University computer science PhD Hu Dingsheng.
How Can a 2B Model Surpass a 7B Model?
What is the actual performance of the “Little Cannon” released by Mianbi Intelligent?
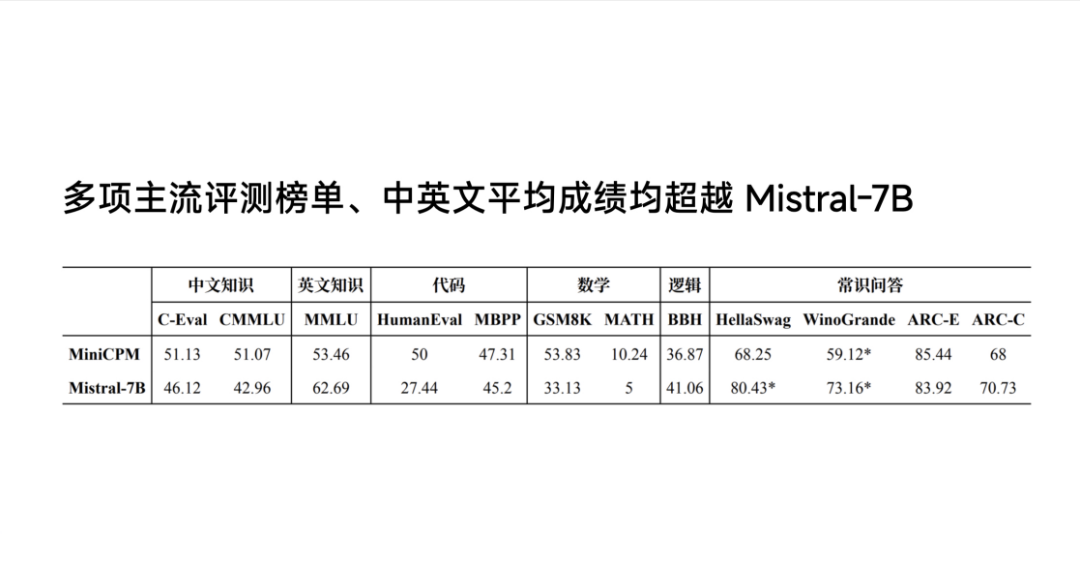
According to the data provided by Mianbi Intelligent, MiniCPM-2B has surpassed Mistral-7B in evaluation rankings across Chinese and English knowledge, coding, mathematics, logic, and common sense Q&A, and is comparable to 13B, 30B, and 40B scale models.
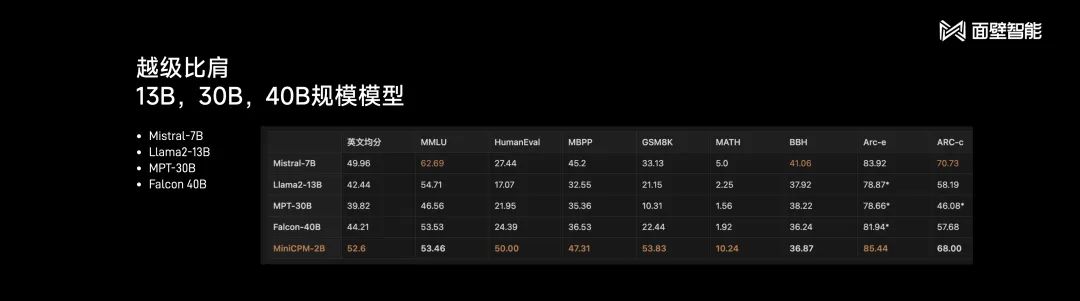
Some may ask, with the parameter scale reduced to 2B, can it still be considered a “large” model? In response, Liu Zhiyuan explained: “A large model is not just about having a large parameter size; it is actually a technology. The ‘large’ refers to our ability to govern and scientifically handle large data effectively.”
“Data-driven approaches have become a more established route in the NLP field. I believe that once the technical route of any discipline or direction is determined and validated, the next task in that field must be to make that route more scientific and standardized, so as to better serve all aspects. Next, in addition to pursuing larger models and stronger emergent capabilities, how to fully exploit the upper limits of fixed-size models is also a very important mission for us, perhaps even a more important mission.” Liu Zhiyuan further stated.
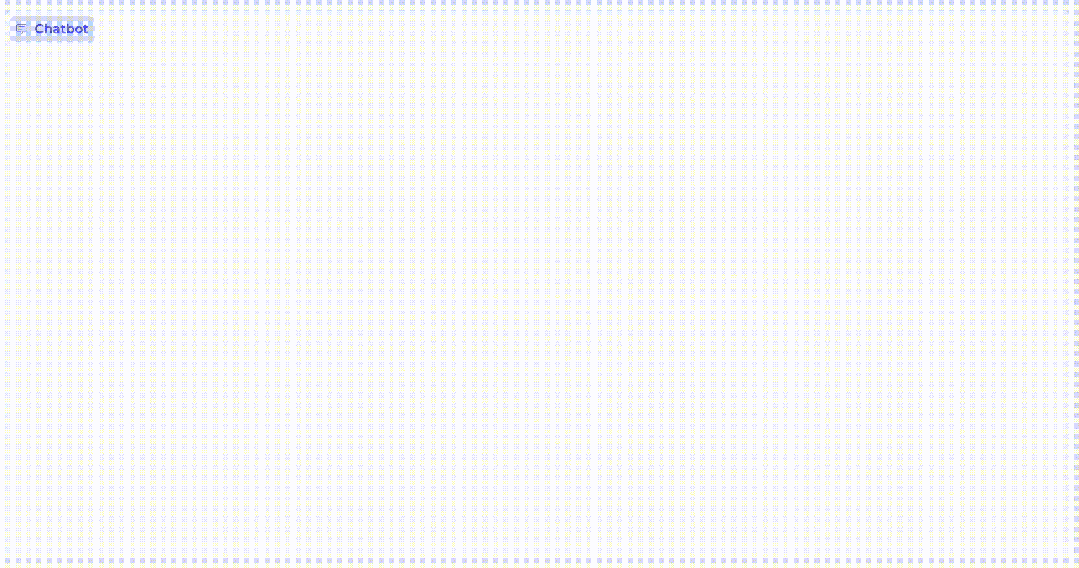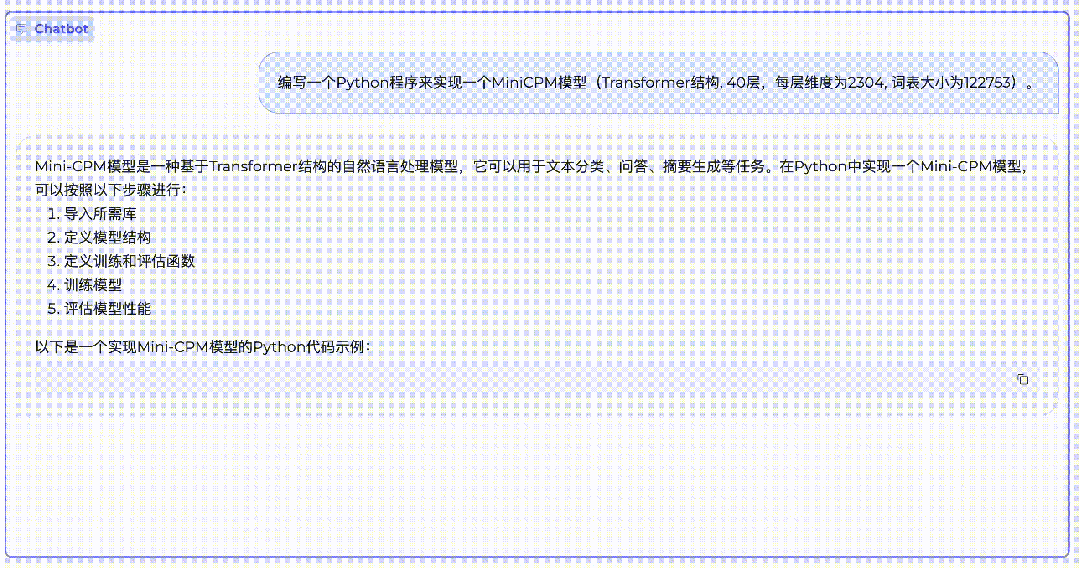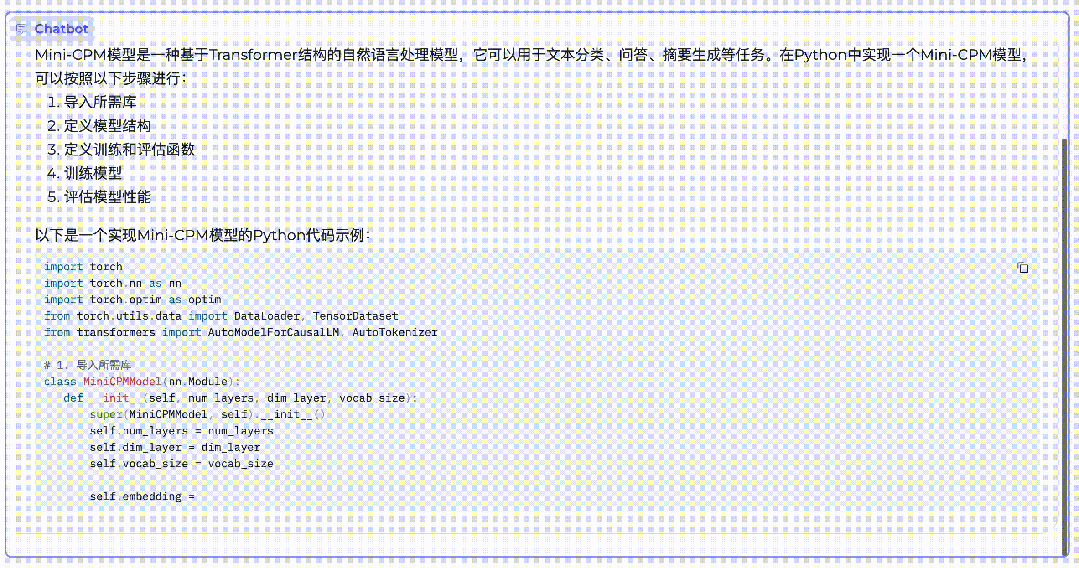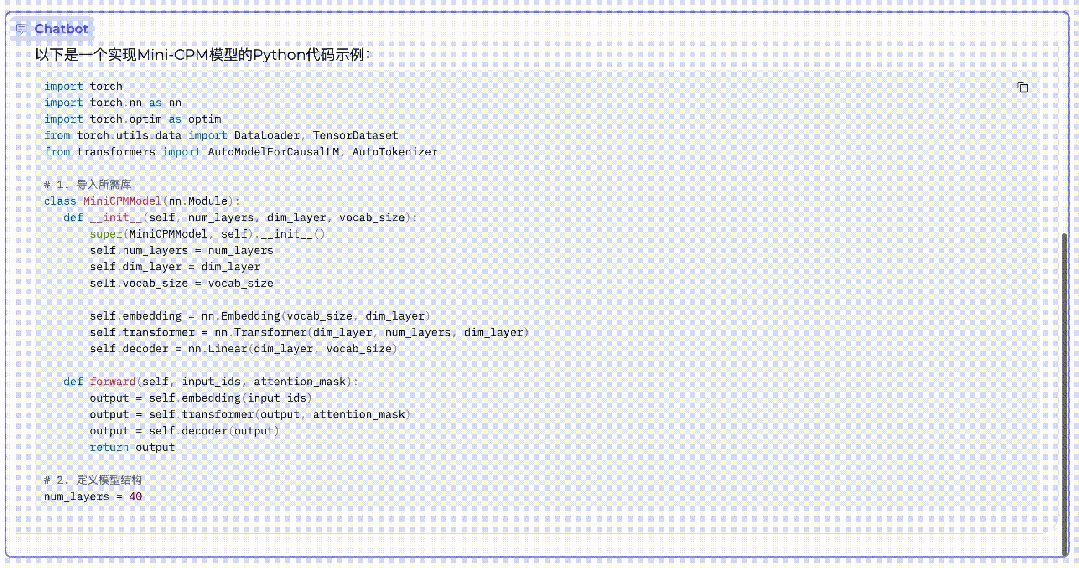
MiniCPM is a phased achievement of Mianbi Intelligent’s scientific approach to large model technology. During the conference, Li Dahai also demonstrated the language understanding and code generation capabilities of the “Little Cannon”.
“Little Cannon” writes its own code
Additionally, Mianbi Intelligent has for the first time implemented multi-modal capabilities on the edge, with the edge version of the model called “MiniCPM-V”. At the press conference, Li Dahai demonstrated the performance of multi-modal capabilities on the edge by putting an OPPO phone into airplane mode. It was reported that Mianbi Intelligent’s edge model has an inference speed of about 7 tokens per second on mobile phones.
It is worth noting that Mianbi Intelligent is also continuously exploring multi-modal models. According to reports, the multi-modal model Mianbi OmniLMM has already achieved more precise multi-modal understanding capabilities and enables real-time multi-modal streaming interactions.

Mianbi OmniLMM multi-modal capability demo
In terms of energy efficiency, MiniCPM supports CPU inference. This time, Mianbi Intelligent also launched a quantized version of MiniCPM, with memory flash compression of 75%, and performance with minimal loss.
In March 2022, half a year before the launch of ChatGPT, Liu Zhiyuan analyzed ten considerations regarding the research direction of large models, one of which mentioned the energy efficiency issue of large models. As large models grow larger, the consumption of computing and storage costs naturally increases. “Once a large model is trained and put to use, its ‘size’ will make the inference process very slow. Therefore, another frontier direction is how to efficiently compress the model, accelerating inference while maintaining its effectiveness. The main technical routes in this area include pruning, distillation, and quantization, etc.”
Today, after nearly two years of iteration, how has Mianbi Intelligent achieved “small to defeat large”?
In terms of computing power, Mianbi Intelligent has built a high-efficiency infrastructure that can increase inference speed by ten times and reduce inference costs by 90%.

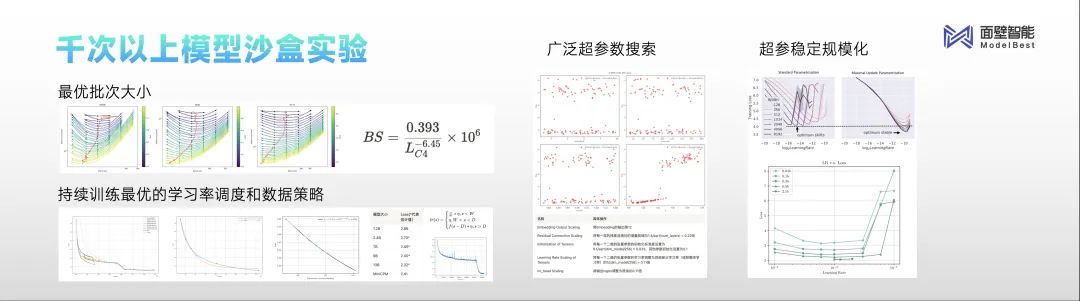
In terms of algorithms, Mianbi Intelligent has introduced a “model sandbox”, transforming the training process of large models from “alchemy” to “experimental science”.
“Before releasing MiniCPM, we conducted thousands of model sandbox experiments to explore the optimal configurations. All sizes of models can achieve the best results through optimal hyperparameter configurations obtained through experimentation. For example, we optimized the globally used learning rate scheduler, discovering that the WSP scheduler is very friendly for continuous training,” Li Dahai shared.
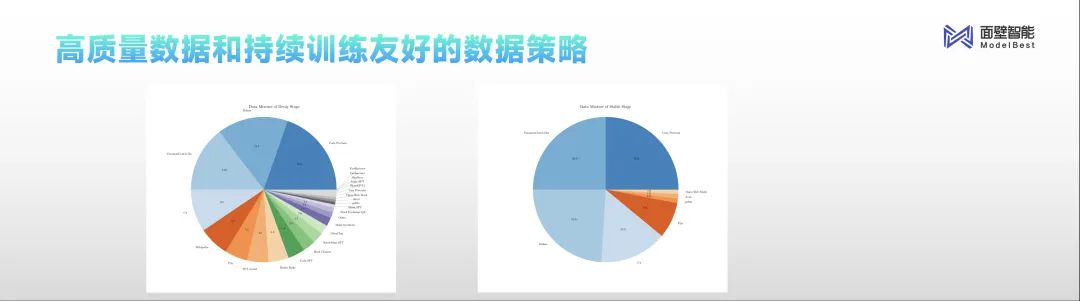
In terms of data, a modern data factory has formed a closed loop from data governance to multi-dimensional evaluation, driving rapid iteration of model versions.
Currently, MiniCPM has been fully open-sourced. Mianbi Intelligent has also open-sourced two data recipes for industry reference.
The Commercial Significance of Edge Models
In the second half of 2023, the competition for edge large models is heating up.
In August 2023, Huawei was the first to announce the integration of large models into mobile assistants. Subsequently, Xiaomi upgraded its Xiao Ai large model, Vivo launched the BlueLM large model, OPPO introduced its self-trained personalized large model and the AndesGPT intelligent agent, and Honor released the Magic large model.
Looking overseas, according to media reports, Apple’s R&D department recently published a research paper on large models entitled “Large Language Models in Flash: Efficient Large Language Model Inference with Limited Memory”, which proposes the concept of using flash technology innovations to overcome the challenges of large model deployment on the edge; in the New Year’s message on January 3, Samsung strongly endorsed its AI business and released its first Galaxy S24 series phone equipped with the edge AI assistant “Galaxy AI” on January 18.
Upstream chip manufacturers and downstream application developers are also taking action. Qualcomm and MediaTek have successively released next-generation mobile chips capable of supporting the operation of large models with billions of parameters on mobile phones; Humane, backed by Sam Altman, launched the AI Pin in November 2023, aiming to build a future-oriented operating system.
Why are edge large models becoming a new trend?
On one hand, for terminal manufacturers, deploying large models on terminals may stimulate a new round of sales growth and may even explore a new generation of “AI hardware products” that could disrupt current mainstream terminal devices. The AI hardware product Rabbit, which garnered attention at CES 2024, has already refreshed public perception of the new generation of AI hardware.
On the other hand, for large model manufacturers, training massive models with hundreds of billions or even trillions of parameters consumes a lot of computing power and energy, supported by a massive investment of talent and funds; in practical implementation, massive models are also not economical and not user-friendly.
“In the future, cost will be the invisible competitive advantage of large models.” At the press conference, Li Dahai made a strong assertion. This is not merely talk; he shared, “In commercial practice, we have noticed that many customers are concerned about the cost of the model.”
Discussions about reducing model costs permeated the entire press conference. Han Xu, a postdoctoral researcher at Tsinghua University and chief researcher at Mianbi Intelligent, shared: “Our core goal is to further reduce the cost of large models through acceleration technology.”
In this context of “reducing costs and increasing efficiency” for large models, “cloud-edge collaboration” is becoming a new technological trend in the AI field. A research report from CITIC Securities pointed out that “using the cloud as the AI brain, and the edge and terminal as the small brain will become the main line of technological development.”
Mianbi Intelligent is also exploring a set of multi-size model technology solutions for cloud-edge collaboration.
“Imagine if in the next 1-2 years, a phenomenal C-end product emerges, with tens of millions of users using a product driven by large models, how can we support its computing cost? It must be a cloud-edge collaboration solution. Any problem that can be solved by the computing power on the user’s phone should not be solved in the cloud; otherwise, the computing load on the cloud would be unimaginable.” Liu Zhiyuan explained.
At the same time, Li Dahai added: “Edge models have significant commercial value. Once large models run on the edge, many applications that were previously impossible can now be advanced.”
Moreover, from the perspective of Mianbi Intelligent’s technical path, edge large models can also feedback into Agents. Mianbi Intelligent CTO Zeng Guoyang stated: “Edge large models are closer to users, and the capabilities of Agents applied to edge models can better serve specific scenarios. These two directions can support each other and create some wonderful chemical reactions.”
Those who have a slight understanding of Mianbi Intelligent know that over the past year, Mianbi Intelligent has made significant strides in the direction of “large model + Agent”. Liu Zhiyuan proposed a brand new concept for the future, “IoA”, which stands for Internet of Agents. Mianbi Intelligent’s technical path has gradually expanded from foundational large models to Agents and then to final upper-layer applications.
Based on the research and development of large language models, Mianbi Intelligent has launched the “three carriages” of AI Agents:
The first carriage is the AgentVerse, a general platform for intelligent agents driven by large models, which consists of various AI experts forming “workgroups” to help users solve complex tasks.
The second carriage is ChatDev, a multi-agent collaborative development framework based on AgentVerse, which is an AI-native application based on collective intelligence that can be applied to SaaS platform products for software development, helping developers complete software development at lower costs and higher efficiency.
The third carriage is the XAgent application framework for AI agents, which can independently decompose and handle complex tasks, akin to a more powerful single intelligent entity.
Edge models are the “final link” for Agents to truly enter the homes of ordinary people.
Mianbi and Zhihu
In this wave of large model trends, Liu Zhiyuan, co-founder of Mianbi Intelligent and tenured associate professor of computer science at Tsinghua University, is one of the first to venture into the field.
Looking back to 2017, when Google introduced the Transformer neural network architecture. A year later, Google followed up with the BERT model.
Through BERT, Liu Zhiyuan realized the impact of Transformers on the NLP technical path. “Transformers now have significant influence; one aspect is that each layer utilizes Attention to capture global information, enhancing the learning ability of long-range dependencies, which CNN lacks. At the same time, Transformers can achieve excellent acceleration on GPUs, learning better results from more training data, which RNN series models struggle to accomplish,” Liu Zhiyuan stated in an interview.
In January 2019, Liu Zhiyuan organized his students in the Tsinghua NLP lab to hold a seven-day meeting at a hotel by Yanqi Lake, ultimately deciding to set aside other work and fully focus on researching large models.
In December 2020, Liu Zhiyuan led his team to launch the world’s first Chinese pre-trained large model, CPM-1; in 2021, he began organizing core members of the lab to establish a new company; in August 2022, Mianbi Intelligent was officially founded, three months before the emergence of ChatGPT.
On November 30, 2022, after the release of ChatGPT, a new wave of artificial intelligence surged in. In February 2023, Wang Huiwen announced his entry into the field, founding Guangnian Zhiwai and actively recruiting talent. Following the acquisition of top tech firm Oneflow, news of Guangnian Zhiwai acquiring top-tier “Tsinghua system” stars like Mianbi Intelligent gradually spread.
In fact, Mianbi Intelligent was indeed seeking partners at that time. Despite its strong technology and a team comprised of many talents from Tsinghua’s NLP lab, running a company is different from conducting research; having technology alone is not enough. Issues such as organizational management, strategic positioning, and business model are also critical to the survival of the enterprise. Mianbi Intelligent’s team primarily consisted of engineers, making it challenging to address these complex non-technical problems.
Quickly, an announcement dispelled all rumors. In February 2023, Zhihu announced its investment in Mianbi Intelligent; on June 2, Zhihu announced that its partner and CTO Li Dahai would serve as the board member and CEO of Mianbi Intelligent, responsible for strategic development and daily operations management.
Li Dahai graduated with a master’s degree from the Department of Mathematics at Peking University. After graduation, he joined Google as one of the founding employees in China, later serving as engineering director at YunYun and head of search technology at Wandoujia, with 12 years of entrepreneurial experience. He joined Zhihu in 2015 as a partner and CTO, responsible for building Zhihu’s overall technical system, overseeing community governance and user experience, and has extensive experience in building top-tier technical systems, strategic planning, technology management, and commercial implementation, having established search and recommendation services at Zhihu from scratch, and initiated Zhihu’s AI “smart community”, helping Zhihu transition from a user base of millions to hundreds of millions and forming a relatively stable business model with diversified revenue sources.
Zhihu and Mianbi Intelligent form a mutually beneficial partnership.
Li Dahai mentioned in an interview about his investment in Mianbi Intelligent, saying: “This is the only project I initiated as CTO of Zhihu.” At that time, as a mid-tier internet company and a publicly listed firm, Zhihu wanted to embrace a new technological wave but could not invest in it as recklessly as a startup. Mianbi Intelligent provided the technical strength that Zhihu needed.
For Mianbi Intelligent, Zhihu has a wealth of high-quality Chinese internet data, which is essential for training large models.
Under the leadership of Li Dahai, Mianbi Intelligent has been making steady progress. In April 2023, Zhihu and Mianbi Intelligent announced the launch of their first Chinese large model “Zhihai Map AI” and application “Hot List Summary”; on May 27, Li Dahai disclosed the latest progress of their collaboration at the 2023 Digital Expo, including the announcement that the Chinese foundational large model CPM-Bee10b developed by Mianbi Intelligent was fully open-sourced, the release of the dialogue model product “Mianbi Luka”, and the internal testing of the second model application in the Zhihu scenario, “Search Aggregation”. While focusing on the Agent direction, the foundational model continues to catch up with the world’s leading levels. In November 2023, Mianbi Intelligent released its latest multi-modal large model CPM-Cricket, which is comparable to GPT-3.5 in capability.
It is noteworthy that Mianbi Intelligent is further exploring based on a wealth of open-source achievements. As early as April 2022, before the establishment of Mianbi Intelligent, Liu Zhiyuan led the team to initiate the OpenBMB open-source community, developing many open-source technologies and tools for large models.
Over the past year, Mianbi Intelligent’s research team has rapidly expanded from a dozen to over 100 members, with an average age of just 28. The company’s CTO Zeng Guoyang is only 25 years old and has been following Liu Zhiyuan to lead the development of the CPM series large models.
How far Mianbi Intelligent can go ultimately depends on whether it can form a closed-loop business model.
In terms of business path selection, Li Dahai has stated: “Mianbi Intelligent focuses more on the C-end. On one hand, in terms of organizational capability, Mianbi Intelligent’s gene is more inclined towards C, so for B-end business, we prefer to choose partners who are good at communicating with customers and have strong delivery capabilities; we provide the platform and tools while partners handle the delivery and implementation work.”
Notably, towards the end of the “Little Cannon” press conference, Li Dahai revealed an “Easter egg”, the C-end application “Xinjian” launched by Mianbi Intelligent.
It can be seen that from large models to Agents and then to C-end applications, Mianbi Intelligent’s technical roadmap is becoming increasingly clear.
(Cover image source: Mianbi Intelligent)