"IT Chat" is a professional IT information and service platform under the Machinery Industry Press, dedicated to helping readers master more professional and practical knowledge and skills in the broad IT field, quickly enhancing workplace competitiveness. Click on the blue WeChat name to quickly follow us!
Faced with numerous large model choices in the market, how to scientifically select them has become an important issue for enterprises. Based on the author’s practical experience, we will evaluate large models from three dimensions: basic information assessment, performance assessment, and registration information assessment.
Basic Information Assessment of Large Models
The basic information assessment of large models is crucial as the first step in selection. Below, we will elaborate on the basic information evaluation of large models from six aspects: parameter count, data scale and dimensions, model architecture, application areas, vendor characteristics, and community support and ecosystem.
The parameter count is an important indicator of the complexity of large models, directly affecting the model’s expressiveness and learning ability. According to the scaling laws and emergent capabilities of large models, a larger parameter count usually implies stronger learning and expressive abilities. However, increasing the parameter count also leads to higher computational resource consumption and training difficulty, which can affect fine-tuning strategies during project execution and computational resources during deployment.
Therefore, enterprises should choose models with an appropriate parameter count based on their computational resources and business needs. For resource-constrained enterprises, it is advisable to select models with a moderate parameter count to balance performance and resource consumption, avoiding the blind pursuit of high parameter counts, and evaluating the model’s performance in light of actual application scenarios.
2. Model Data Scale and Dimensions
Data is the foundation for training large models, and the choice of data scale and dimensions directly impacts the training effectiveness and performance of the model. Large and comprehensive datasets help models learn broader knowledge and enhance generalization capabilities, while domain-specific datasets can enable models to perform better on specific tasks.
Therefore, it is preferable to choose models trained on datasets relevant to the industry or field of the enterprise to ensure that the model has a deep understanding of the specific domain. Additionally, consider the richness and diversity of data to improve the model’s generalization ability and adaptability.
The model architecture determines how large models learn and their performance limits. Currently, most mainstream large model architectures are based on Transformers, but different models may have innovations and optimizations in architecture to suit different application scenarios.
Therefore, in practical projects, attention should be paid to the innovations and optimizations in model architecture, understanding improvements in performance and reductions in computational complexity, and selecting verified, stable-performing model architectures to reduce risks in practical applications.
4. Model Capability Application Areas
Different large models may be optimized for specific fields, or their underlying training data determines their application capabilities. Therefore, when selecting large models, it is necessary to determine the application’s domain based on the actual needs of the enterprise.
5. Vendor Characteristics
The characteristics of the vendor are also a factor to consider during selection. Factors such as the vendor’s reputation, technical strength, and service quality will affect the user experience and subsequent support for the model.
6. Community Support and Ecosystem
An active community and a rich ecosystem mean more resources and support, helping enterprises solve problems and optimize models during use. The activity level of the community and the completeness of the ecosystem are also important factors in evaluating the value of large models.
Performance Assessment of Large Models
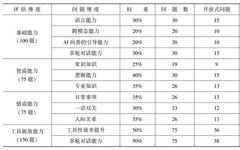
The performance assessment of large models is a key step after selecting basic information. It aims to comprehensively measure the performance of large models in practical applications. In project practice, we evaluate the performance of large models from two main aspects: general model capabilities and scenario adaptability. For general model capabilities, we will comprehensively assess the selected large models in terms of basic capabilities, IQ capabilities, EQ capabilities, and tool efficiency capabilities to determine whether they possess general intelligence similar to humans. The scenario adaptability assessment is more specific; we will design verification questions based on the project’s actual needs and use the large model’s responses and handling of these questions to verify whether it truly meets the specific requirements of the project.
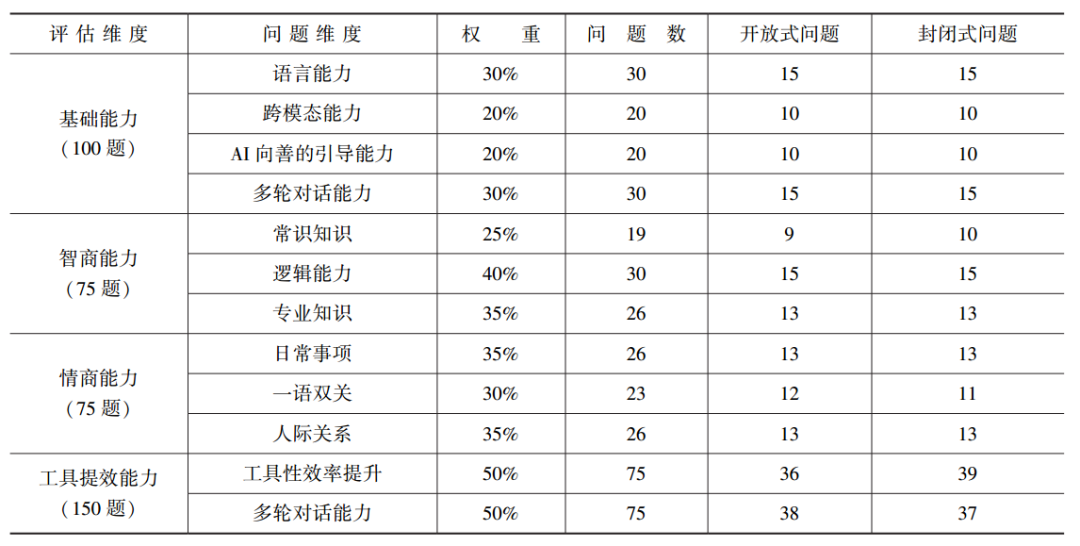 Table 1. General Capability Assessment Method Questionnaire for Large Models
Table 1. General Capability Assessment Method Questionnaire for Large Models
 Figure 1. Example of General Testing Assessment for Large Models
Figure 1. Example of General Testing Assessment for Large Models
 Figure 2. Example of Specific Scenario Assessment After Prompt Optimization for Large Models
Figure 2. Example of Specific Scenario Assessment After Prompt Optimization for Large Models
 Figure 3. Example of Scenario Capability Testing Assessment After Fine-Tuning for Large Models
Figure 3. Example of Scenario Capability Testing Assessment After Fine-Tuning for Large Models
Registration Information Assessment of Large Models
Currently, although there are no explicit requirements that enterprises must only use registered large models when building private large models, completed registration models have undergone strict capability reviews, thus having strong advantages in model performance and safety. Therefore, it is recommended that enterprises prioritize using registered large models.
1. Overview of Large Model Registration
Large model registration, specifically for generative artificial intelligence (large language models), is a specific management process set by the Internet Information Department for generative synthesis (deep synthesis) algorithms. This system is established to ensure that large models have passed strict capability reviews and safety assessments before being put into operation, thereby ensuring that they meet certain standards in model performance and safety.
Here, “generative artificial intelligence technology” specifically refers to models and related technologies capable of generating content such as text, images, audio, and video. “Deep synthesis technology” encompasses techniques for creating network information, including text, images, audio, and video, using methods such as deep learning and virtual reality. These technologies include text generation and style transfer, question-answer dialogues, and face generation and replacement, among others.
(1) Subjects of Large Model Registration
According to the “Interim Measures for the Management of Generative Artificial Intelligence Services,” generative artificial intelligence service providers with public opinion attributes or social mobilization capabilities must carry out safety assessments and registration in accordance with national regulations. These service providers are mainly divided into two categories: platform operators and technical support providers.
(2) Large Model Registration Process
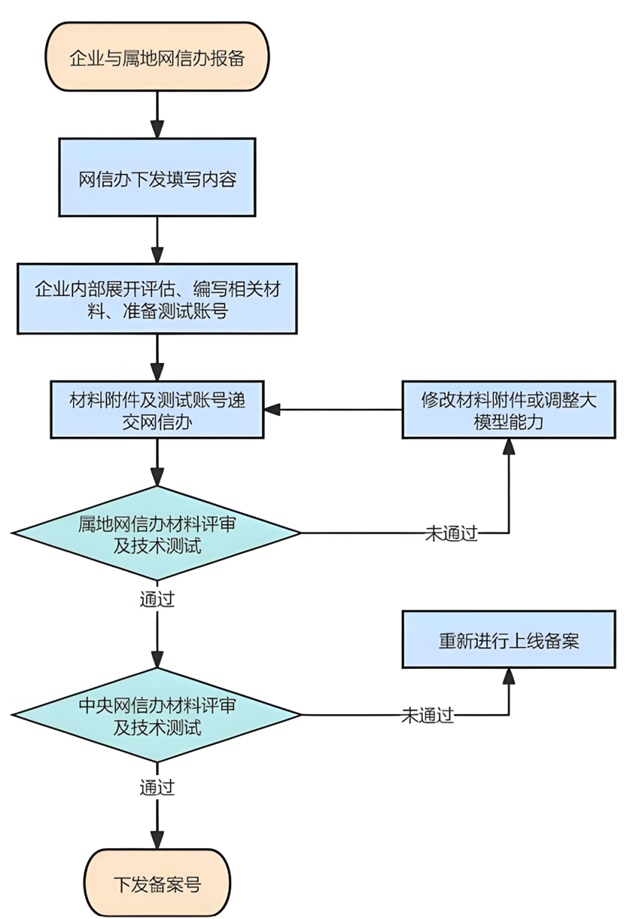
As shown in the figure below, the important nodes in the large model registration process are as follows:
Figure 4. Large Model Registration Process
(3) Materials Required for Large Model Registration
When registering a large model, the service provider needs to prepare the following materials:
Large model online registration application form: detailing the model’s basic information, development team details, application scenarios, etc.
Attachment 1: Safety self-assessment report: a comprehensive assessment of the model’s safety, including data safety, algorithm safety, system safety, etc.
Attachment 2: Model service agreement: clarifying the rights and obligations between the service provider and users to protect both parties’ legal rights.
Attachment 3: Corpus annotation rules: detailing the annotation rules and methods used in training the model.
Attachment 4: Keyword interception list: listing potential keywords or sensitive terms that may be recognized and intercepted by the model.
Attachment 5: Assessment test question set: providing a set of test questions used to evaluate the model’s performance and accuracy.
In summary, the establishment and implementation of the large model registration system are of great significance for standardizing the development of artificial intelligence technology in China. Through strict registration processes and material reviews, it can ensure that large models meet high standards in legality, safety, and performance, thereby promoting the healthy and sustainable development of China’s artificial intelligence industry.
2. Enterprise Review and Assessment of Registration Information
When a large model is registered, it will submit detailed application scenarios, safety self-assessment reports, model annotation rules, keyword and sensitive term interception information, and test set information. This is crucial for enterprises to fully understand and assess the capabilities and applications of large models, determining whether the vendor has the implementation capability for this project. The following are common methods we use in project practice.
(1) Clarify Evaluation Objectives and Standards
Before starting the evaluation, enterprises should first clarify their business needs, technical requirements, and safety standards. This helps enterprises review relevant information more targeted in the subsequent evaluation process, ensuring that the selected large model meets the enterprise’s safety needs.
(2) Review Application Scenarios
Enterprises should carefully read the application scenario descriptions provided in the large model registration to understand the model’s main uses, usage environment, and expected effects. By comparing with the actual needs of the enterprise, determine whether the model is suitable for the business scenario of the enterprise. At the same time, pay attention to potential risk points and challenges in the application scenarios to formulate corresponding countermeasures in subsequent cooperation.
(3) Analyze Safety Self-Assessment Report
Safety is an important factor that enterprises cannot ignore when selecting large models. Enterprises should carefully review the safety self-assessment report to understand the design and implementation of the model in terms of data security, algorithm security, and system security. Pay particular attention to the security vulnerabilities mentioned in the report and the corresponding countermeasures to ensure that the model can guarantee the security and integrity of enterprise data in practical applications.
(4) Verify Annotation Rules
The annotation rules directly affect the model’s understanding and processing capabilities of data. Enterprises should verify whether these rules are scientific, reasonable, and meet the enterprise’s data processing needs. By comparing the annotation rules of different models, choose those that can more accurately reflect the enterprise’s data characteristics and processing logic.
(5) Check Keyword and Sensitive Term Interception Information
The keyword and sensitive term interception functionality is crucial for ensuring information security and compliance with laws and regulations. Enterprises should check the keyword and sensitive term lists provided in the registration information to ensure they are comprehensive and meet the enterprise’s compliance requirements. At the same time, test the model’s interception functionality to avoid inappropriate content or sensitive information leakage in practical applications.
(6) Evaluate Test Set Information and Model Performance
The test set information is an important basis for evaluating the performance of large models. Enterprises should review whether the design of the test set is reasonable, whether the data is rich and diverse, and understand the evaluation indicators and methods used during the testing process. By comparing the test results of different models, choose those that perform excellently on key indicators such as accuracy and recall rate. Furthermore, enterprises can design their own test cases for further performance testing of the model.
In summary, the enterprise’s review and assessment of the registration information of large models is a systematic and detailed process. By clarifying evaluation objectives, reviewing application scenarios, analyzing safety reports, verifying annotation rules, checking keyword interception information, and evaluating test set information and model performance, enterprises can gain a more comprehensive understanding of the capabilities and applications of large models, thus making more informed choices.
The above content is excerpted from “AI Empowerment: Concepts, Technologies, and Enterprise-Level Project Applications of Large Models”
Author: Tian Ye, Zhang Jianwei

▊ “AI Empowerment: Concepts, Technologies, and Enterprise-Level Project Applications of Large Models”
Tian Ye, Zhang Jianwei
-
Top 1 in JD’s “Computer and Internet” book sales ranking!
-
Forewords by Wu Shengnan, Vice President of SANY Group, and Yan Jun, Vice President of XCMG Group.
-
Summary of practical experiences in large models and intelligent agents from Lenovo’s solution service business group, providing a panoramic view of the large model product ecosystem and technical principles, proposing standards for selecting and building large models and methods for project implementation, a practical guide for enterprises to build, deploy, and apply large models.
This book focuses on the practical application of large model technology in enterprises, helping readers apply large models to reduce costs and increase efficiency. The book consists of 6 chapters: Introduction to Large Models, Large Model Product Ecosystem, Technical Principles of Large Models, How Enterprises Deploy and Apply Large Models, Implementation Methods for Enterprise Large Model Projects, and Practical Applications of Large Models in Enterprises.
This book provides detailed standards for selecting and building large models, aiming to provide enterprises with a clear guide for large model construction, helping readers understand how to build, deploy, and apply large models. It details the implementation methods for enterprise large model projects, from project planning to engineering deployment, and showcases the powerful application potential of large models in foundational infrastructure, enterprise knowledge platforms, business knowledge bases, intelligent agents, and personal office intelligent assistance tools through specific enterprise application practice cases, helping readers master key technologies and management capabilities for applying large models in practice.
The target audience for this book includes practitioners in artificial intelligence, machine learning, and data analysis, enterprise managers and decision-makers interested in digital transformation and intelligent applications, technical researchers and developers who wish to enhance their skills through large model technology and implementation methods, and readers interested in large model technology who wish to explore this cutting-edge technology and its application scenarios.
Author: Ji Xu<br/>Editor: Hao Jianwei<br/>Reviewer: Cao Xinyu