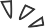Image Source @GPT Generated
Image Source @GPT Generated
▎The premise of competing for computing power is that computing power is becoming a new business model. The craze of “alchemy” for large models will pass, and computing power service providers need to prepare for the future and pivot in a timely manner.
Author|Qin Conghui
Editor|Gai Hongda
This article was first published on the Titanium Media APP
Using 40 years of global weather data, pre-training with 200 GPU cards for about 2 months, a large model with hundreds of millions of parameters named Pangu Meteorological Model was trained.
This is the story of Bi Kaifeng, who graduated from Tsinghua University three years ago and trained a large model.
However, from a cost perspective, based on a normal calculation of 7.8 yuan/hour for a GPU, the training cost of Bi Kaifeng’s Pangu Meteorological Model may exceed 2 million. This is still a vertical large model in the meteorological field; if it were a general large model, the cost could increase a hundredfold.
Data shows that there are already over 100 large models with a parameter scale of 1 billion in China. However, the industry is facing a dilemma where high-end GPUs are hard to come by. The high cost of computing power, along with the lack of computing power and funds, has become the most immediate issue facing the industry.
How Scarce Are High-End GPUs?

“Yes, there is a shortage, but what can we do?” A senior executive from a major company blurted out when asked if there is a shortage of computing power.
This seems to have become an industry-wide accepted problem, as the price of an NVIDIA A100 reached 200,000 to 300,000 yuan at its peak, and the monthly rental price of a single A100 server has soared to 50,000-70,000/month. However, even at such high prices, it is still possible to be unable to obtain chips, and some computing power suppliers have encountered unusual experiences such as suppliers failing to deliver.
A senior executive in the cloud computing industry, Zhou Lijun, also shared similar feelings: “The shortage of computing power does exist. Many of our clients want high-end GPU resources, but what we can provide cannot fully meet the broad market demand for now.”
Interface showing sold-out high-performance computing cluster equipped with A100 from a cloud service provider
It has been proven that the shortage of high-end GPUs is unsolvable in the short term across the industry. The explosion of large models has led to a rapid increase in market demand for computing power, but the supply growth has not kept pace. Although the supply of computing power will eventually shift from a seller’s market to a buyer’s market in the long run, how long this transition will take remains unknown.
Everyone is calculating how much “inventory” (NVIDIA GPUs) they have, even using this to gauge market share. For example, if one has nearly 10,000 cards, and the total market is 100,000 cards, then the share is 10%. “By the end of the year, the inventory might reach about 40,000; if the market is 200,000, then it might account for 20% of the market,” a source familiar with the situation explained.
On one hand, there is difficulty in obtaining cards, while on the other hand, the threshold for training large models is not as easy to “enter” as the industry promotes. As mentioned, the training cost of Bi Kaifeng’s Pangu Meteorological Model may exceed 2 million. However, it should be noted that Bi Kaifeng’s Pangu Meteorological Model was trained based on the Pangu General Model, and its parameters are in the hundreds of millions. If one were to train a general model with a billion parameters or larger, the cost could increase tenfold or a hundredfold.
“Currently, the largest investment is in training. Without several billion in capital, it is difficult to continuously work on large models,” said Qiu Yuepeng, Vice President of Tencent Group, COO of Cloud and Smart Industry Group, and President of Tencent Cloud.
“You have to run fast, at least before the money runs out, to achieve results for the next round of financing,” a startup founder described the current situation of large models. “This path is a dead end. If you don’t have hundreds of billions or trillions of funds backing you, it is difficult to get through.”
In this situation, the common view in the industry is that as the competition in the large model market intensifies, the market will shift from frenzy to rationality, and companies will control costs and adjust strategies according to changing expectations.
Proactive Responses to Unsolvable Problems

No conditions? Create conditions—this seems to be the mindset of most participants in large models. As for how to create conditions and address the real problems, various companies have many methods.
Due to the shortage of high-end GPU chips, and the GPUs available in the Chinese market are not the latest generation, their performance is usually lower, so companies need longer time to train large models. These companies are also looking for innovative ways to compensate for the computing power shortfall.
One method is to use higher quality data for training to improve training efficiency.
Recently, the China Academy of Information and Communications Technology released the “Research Report on the Standard System and Capability Architecture of Industry Large Models,” which mentioned the evaluation of large model data layers. The report suggests that in terms of data quality, which greatly affects the model’s performance, it is recommended to introduce manual labeling and confirmation, selecting a certain proportion from the raw data for labeling to build a significantly high-quality dataset.
In addition to reducing large model costs through high-quality data, for the industry, enhancing infrastructure capabilities to achieve stable operation of over a thousand cards for two weeks without failure is both a technical challenge and a method to build reliable infrastructure and optimize large model training.
“As a cloud service provider, we help customers establish stable and reliable infrastructure. Because the stability of GPU server cards can be poor, any failure can interrupt training, leading to an increase in overall training time. High-performance computing clusters can provide customers with more stable services, which can relatively reduce training time and solve some computing power issues,” Zhou Lijun said.
At the same time, the scheduling of computing power card resources tests the technical capabilities of service providers. Xu Wei, head of Internet solutions at Volcano Engine East China, told Titanium Media that having computing power card resources is one aspect, but how to schedule these card resources for actual use is the core capability and engineering ability that poses greater challenges. “Breaking one card into many smaller cards and trying to achieve distributed and refined scheduling can further lower computing power costs,” Xu Wei said.
The network also affects the speed and efficiency of large model training. Large model training often involves thousands of cards, and connecting hundreds of GPU servers requires extremely high network speeds. If the network is congested, the training speed will be very slow, and efficiency will be significantly affected. “As long as one server overheats and crashes, the entire cluster may need to stop, and training tasks need to be restarted. This places very high demands on cloud service operation and maintenance capabilities and problem diagnosis capabilities,” Qiu Yuepeng said.
Some vendors are also taking a different approach, transitioning from cloud computing architecture to supercomputing architecture as a means to reduce costs. In scenarios where user needs are met, non-high-throughput computing tasks, and parallel tasks, supercomputing cloud can be about half the price of cloud supercomputing, and then through performance optimization, resource utilization can be increased from 30% to 60%.
Additionally, some vendors choose to use domestic platforms for large model training and inference to replace the hard-to-obtain NVIDIA. “We jointly released the iFLYTEK Xinghuo integrated machine with Huawei, which can conduct training and inference on domestic platforms. This is remarkable. I am particularly pleased to inform everyone that Huawei’s GPU capabilities are now comparable to NVIDIA’s. Ren Zhengfei attaches great importance to this, and three directors of Huawei have worked at iFLYTEK’s special class, and they have now achieved a level that can benchmark NVIDIA’s A100,” said Liu Qingfeng, founder and chairman of iFLYTEK.
Each of the aforementioned methods is a relatively large project, so it is generally challenging for companies to meet their needs through self-built data centers. Many algorithm teams choose to support the most professional computing power vendors. Among them, parallel storage also constitutes a significant cost, as well as technical capabilities, corresponding failure rate guarantees, etc., are also part of hardware costs. Of course, one must even consider the operational costs of IDC available area electricity, software, platform, personnel, etc.
Only GPU clusters at the thousand-card level can achieve scaling effects. Choosing a computing power service provider means that the marginal cost is zero.
Sun Ninghui, an academician of the Chinese Academy of Engineering and a researcher at the Institute of Computing Technology, Chinese Academy of Sciences, once stated in a speech that AIGC leads to an explosion in the artificial intelligence industry, and the large-scale application of intelligent technology has a typical long-tail problem, where strong departments with strong AI capabilities (such as cybersecurity, Nine Institutes and Nine Institutes, and meteorological bureaus), research institutions, and large and medium-sized enterprises only occupy about 20% of the computing power demand. The remaining 80% consists of small and medium-sized enterprises, which are often limited by company size and budget, making it difficult to access computing power resources or constrained by the high prices of computing power, thus missing out on the development dividends in the AI era.
Therefore, to achieve large-scale application of intelligent technology and ensure that the artificial intelligence industry is both “well-received” and “profitable,” a large amount of cheap and easy-to-use intelligent computing power is needed so that small and medium-sized enterprises can conveniently and affordably use computing power.
Whether it is the urgent demand for computing power from large models or the various challenges that need to be addressed in the application process, one new change that needs to be noted is that computing power has become a new service model in the process of market demand and technological iteration.
Exploring New Models of Computing Power Services

What kind of computing power are we competing for in large models? To answer this question, we first need to talk about computing power services.
In terms of types, computing power is divided into general computing power, intelligent computing power, and supercomputing power, and these computing powers have become a service as a result of the dual drive of the market and technology.
The “2023 Computing Power Service White Paper” defines computing power service as a new field of the computing power industry based on diverse computing power, linked by a computing power network, and aimed at effectively supplying computing power.
The essence of computing power services is to achieve unified output of heterogeneous computing power through new computing technologies, and to intersect and integrate with cloud, big data, AI, and other technologies. Computing power services not only include computing power but also unify resources such as computing power, storage, and networks, completing computing power delivery in the form of services (such as APIs).
Understanding this point reveals that a significant portion of those scrambling for NVIDIA chips are actually computing power service providers, i.e., computing power producers. Industry users who truly call upon computing power APIs only need to specify their corresponding computing power requirements.
According to Titanium Media App, from the software perspective, all software interactions that generate large model usage can be divided into three types: the first type is large model API calls, where each company has its pricing and settles based on that; the second type is self-owned small models, where they purchase computing power themselves or even deploy it themselves; the third type is collaboration between large model vendors and cloud vendors, which is essentially dedicated cloud services, paid monthly. “Generally, these are the three types. Kingsoft Office currently mainly adopts API calls and has created its own computing power scheduling platform for internal small models,” said Yao Dong, Vice President of Kingsoft Office.
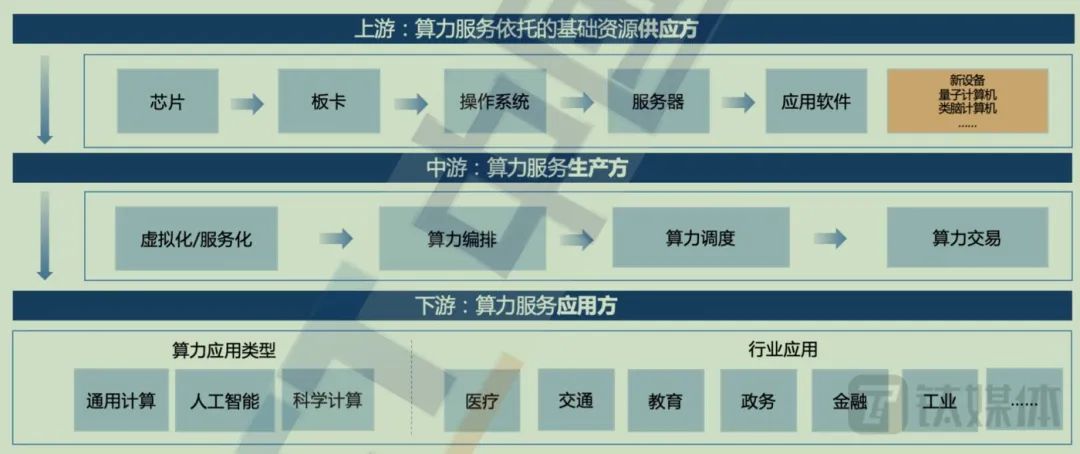
Computing power industry chain structure diagram, source: China Academy of Information and Communications Technology
In other words, in the computing power structure industry chain, upstream companies mainly provide support resources for general computing power, intelligent computing power, supercomputing power, storage, and networks. For example, in the large model computing power competition, NVIDIA belongs to the upstream direction of basic resource supply, while the stocks of server manufacturers like Inspur Information have risen in response to market demand.
Midstream companies are mainly cloud service providers and new computing power service providers, whose roles are primarily to achieve computing power production through computing power orchestration, computing power scheduling, and computing power trading technologies, and to complete computing power supply through APIs and other means. The aforementioned computing power service providers, Tencent Cloud, and Volcano Engine are in this segment. The stronger the service capability of midstream computing power service companies, the lower the threshold for application parties, which is more conducive to the inclusive and ubiquitous development of computing power.
Downstream companies rely on the computing capabilities provided by computing power services to generate value-added services within the industry chain, such as industry users. This part of the users only needs to specify their requirements, and computing power producers configure the corresponding computing power to complete the “computing power tasks” issued by users.
This approach has more cost and technical advantages compared to the previous model of independently purchasing servers to build a large model computing environment. Bi Kaifeng’s training of the Pangu Meteorological Model should have directly called upon the underlying high-performance computing services of Huawei Cloud, so will the process of other large model companies using computing power or paying for computing power be any different?
Iteration of Computing Power Business Models

ChatGLM is one of the first general large models launched. Taking the computing power usage of Zhizhu AI’s ChatGLM as an example, according to publicly disclosed information, Zhizhu AI has utilized several mainstream AI computing power service providers in China. “Theoretically, they should have used all of them,” a source said, which may also include mainstream computing power service providers/cloud service providers in China.
Pay-per-use and subscription billing are currently the mainstream models of computing power services. The usage demand can generally be divided into two types: one is to choose the corresponding computing power service instance. On a certain cloud service provider’s official website, high-performance GPU servers equipped with three mainstream graphics cards: A800, A100, and V100 are available.
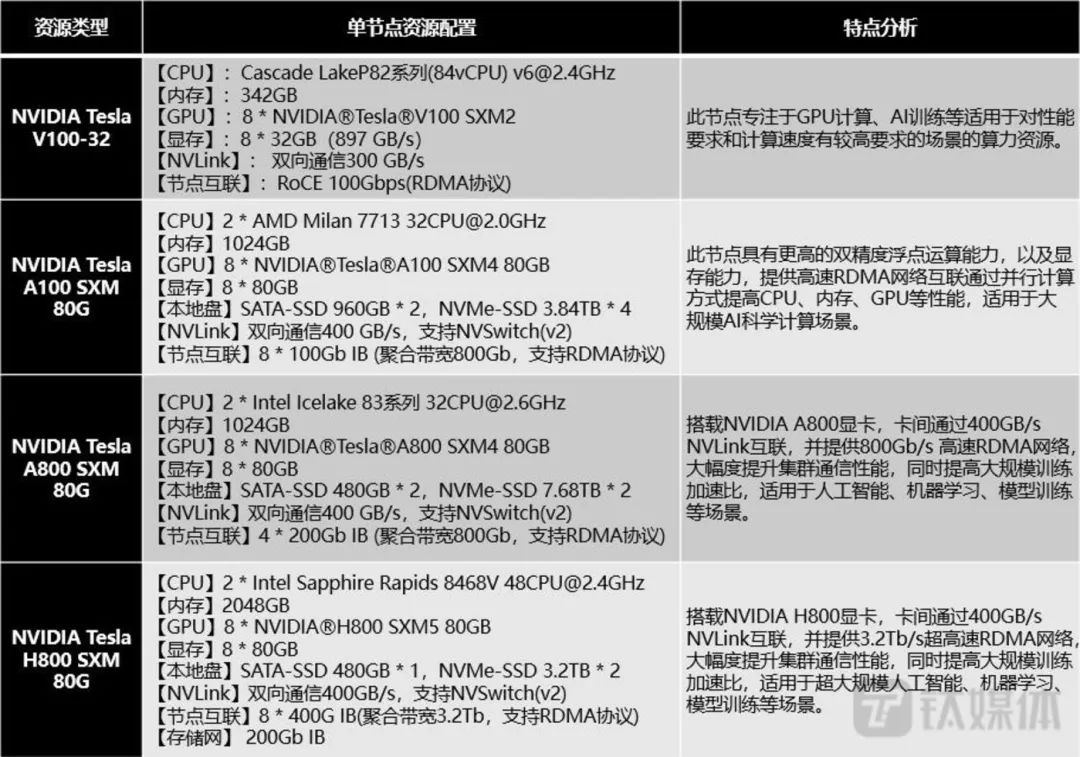
Types of high-performance computing GPU graphics cards offered by a computing power service provider
The other type is to choose the corresponding MaaS service platform for industry-specific fine-tuning of large models. For example, the pay-per-use price for the Tencent Cloud TI-ONE platform is 20.32 yuan/hour for a configuration of 8C40G V100*1, which can be used for automated learning, visual modeling, task-based modeling, and visual modeling.
The industry is also promoting the “integration of computing and networking” in computing power services. By comprehensively judging information such as computing tasks and the status of computing network resources, a computing and network orchestration scheme that supports cross-architecture, cross-region, and cross-service provider scheduling is formed, and related resource deployment is completed. For example, as long as a sum of money is deposited, stored in the computing power network, the partitions within the computing power network can be called at will. Depending on application characteristics, the most suitable partition, the fastest partition, or the most cost-effective partition can be selected, and then billed based on duration, deducting costs from the pre-stored funds.
Cloud service providers are also doing this. Computing power services, as a unique product of cloud services, allow them to quickly participate in the computing power industry chain.
Data from the Ministry of Industry and Information Technology shows that in 2022, China’s total computing power scale reached 180 EFLOPS, ranking second in the world. As of 2022, China’s computing power industry scale has reached 1.8 trillion yuan. Large model computing power has significantly accelerated the development of the computing power industry.
One saying is that the current computing power service is essentially a new type of “selling electricity” model. However, depending on the division of labor, some computing power service providers may need to help users with more system performance tuning, software installation, large-scale job operation monitoring, and operational characteristic analysis, which is part of the last mile of operation and maintenance work.
As the high-performance computing demand for large models becomes normalized, computing power services, which have evolved from cloud services, have rapidly entered the public eye, forming a unique industry chain and business model. However, at the beginning of the computing power industry’s explosion due to large models, the shortage of high-end GPUs, high computing power costs, and the scramble for chips have created a unique landscape of this era.
“At this stage, the competition is about who can get the cards in the supply chain. NVIDIA is currently the king of the entire industry, controlling all markets. This is the current situation,” a source commented. It seems that under the conditions of supply not meeting demand, whoever can get the cards can deliver services.
But not everyone is scrambling for cards because the shortage is temporary; problems will always be solved. “Those engaged in long-term research are actually not scrambling; they can just wait because they will not die. Currently, only a group of startups is genuinely scrambling for cards, as they need to ensure they can survive until next year,” said the source.
Amidst many uncertainties, computing power becoming a service is a certain trend. Computing power service providers need to be prepared to anticipate changes in the market and adapt quickly when large models return to rationality and market winds change rapidly.
*Note: At the request of the interviewee, Zhou Lijun is a pseudonym
(This article was first published on the Titanium Media APP)

Recommended Hot Videos
According to Reuters, Ferrari has announced that its luxury sports cars in the U.S. are now accepting cryptocurrency payments and will expand this plan to Europe based on customer requests, as many of its clients have invested in cryptocurrencies. The report mentions that Ferrari has turned to one of the largest cryptocurrency payment processors, BitPay, for its initial phase in the U.S. and will allow transactions using Bitcoin, Ethereum, and USDC.
———–Splendid Divider———–
Download the Titanium Media App for a leading edge and deeper insights.
Download【Titanium Media App】, for a leading edge and deeper insights.