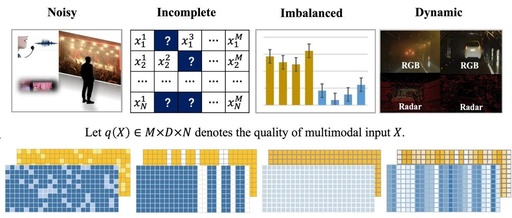

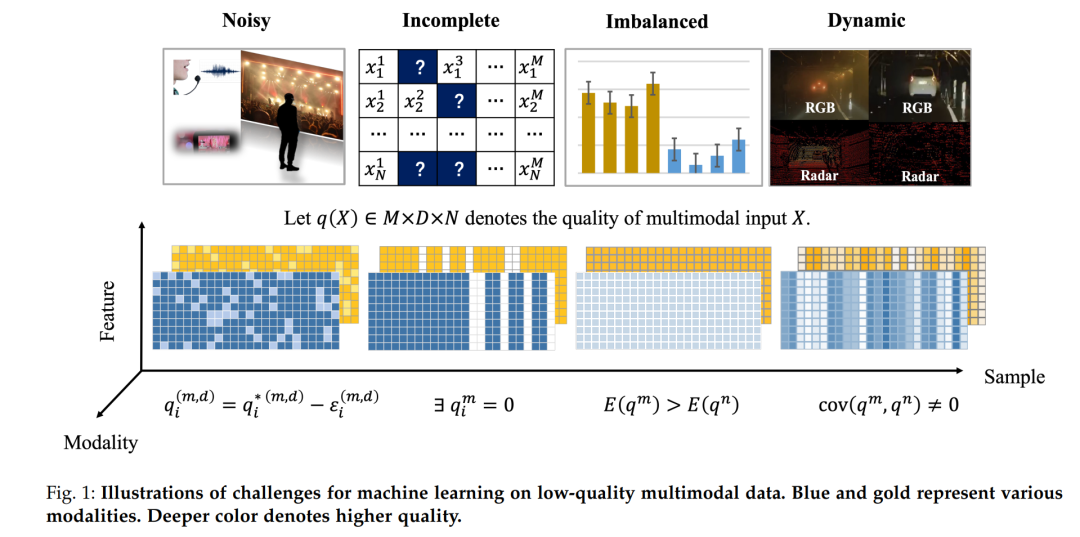
Our perception of the world is based on multiple modalities, such as tactile, visual, auditory, olfactory, and gustatory. Even when certain sensory signals are unreliable, humans can extract useful cues from imperfect multimodal inputs and further piece together the entire scene of ongoing events【1】. With advancements in perception technologies, we can easily collect various forms of data for analysis. To fully unleash the value of each modality, multimodal fusion has emerged as a promising paradigm that integrates all available cues for downstream analysis tasks to achieve precise and reliable predictions, such as in medical image analysis, autonomous vehicles【2】【3】, and emotion recognition【4】【5】【6】. Intuitively, fusing information from different modalities provides the potential to explore cross-modal correlations and achieve better performance. However, there is an increasing awareness that widely used AI models are often misled by spurious correlations and biases present in low-quality data. In real-world scenarios, due to unexpected environmental factors or sensor issues, the quality of different modalities often varies. Some recent studies have empirically and theoretically shown that traditional multimodal fusion may fail on low-quality multimodal data in the wild, such as imbalanced【7】【8】【9】【10】, noisy【11】, or even damaged【12】 multimodal data. To overcome this limitation and move towards robust and generalizable multimodal learning in practical applications, we identify the characteristics of low-quality multimodal data and focus on some unique challenges in real-world multimodal machine fusion. We also highlight potential technological advancements that could help make multimodal fusion more reliable and trustworthy in open environments. In this paper, we identify and explore four core technical challenges surrounding multimodal fusion of low-quality multimodal data. They are summarized as follows (also visually presented in Figure 1):
(1) Noisy multimodal data. The first fundamental challenge is learning how to mitigate the potential impact of arbitrary noise in multimodal data. High-dimensional multimodal data often contains complex noise. The heterogeneity of multimodal data makes it challenging to identify and reduce potential noise, while also providing opportunities to identify and reduce noise by exploring correlations between different modalities.
(2) Incomplete multimodal data. The second fundamental challenge is how to learn from multimodal data with partially missing modalities (i.e., incomplete multimodal data). For example, in the medical field, even patients with the same disease may choose different medical examinations, resulting in incomplete multimodal data. Developing flexible and reliable multimodal learning methods capable of handling incomplete multimodal data is a challenging yet promising research direction.
(3) Imbalanced multimodal data. The third fundamental challenge is how to mitigate the effects of bias and differences between modalities. For example, the visual modality is often more effective than the auditory modality, leading the model to take shortcuts and lack exploration of audio. Although existing fusion methods exhibit promising performance, they may not perform better than single-modality dominant models in certain applications that preferentially favor specific modalities.
(4) Quality-varying multimodal data. The fourth fundamental challenge is how to adapt to the dynamic quality-changing nature of multimodal data. In practice, due to unforeseen environmental factors or sensor issues, the quality of one modality often varies across different samples. For example, under low light or backlight conditions, the amount of information in RGB images is less than that of thermal imaging modalities. Therefore, it is necessary to be aware of quality changes in fusion and dynamically integrate multimodal data in practical applications.
To address these increasingly important multimodal fusion issues, this study systematically organizes the key challenges through several classification systems. Unlike previous works discussing various multimodal learning tasks【13】【14】, this review focuses mainly on the fundamental problems in multimodal learning and the unique challenges posed by low-quality multimodal data in downstream tasks, including clustering, classification, object detection, and semantic segmentation. In the following sections, we detail this field through recent advancements and the technical challenges faced by multimodal fusion: learning on noisy multimodal data (Section 2), missing modality imputation (Section 3), balanced multimodal fusion (Section 4), and dynamic multimodal fusion (Section 5). Section 6 provides a discussion as a conclusion.
Learning on Noisy Multimodal Data
Collecting high-quality multimodal data in real-world scenarios inevitably faces significant challenges posed by noise. Noise in multimodal data【15】 may arise from sensor errors【16】, environmental interference, or transmission loss. For the visual modality, electronic noise in sensors can lead to loss of details. Additionally, the audio modality may be unexpectedly distorted due to environmental factors. Worse still, weakly aligned or even unaligned multimodal samples are common, existing at higher levels of semantic space. Fortunately, considering the correlations between modalities or better utilizing multimodal data can help fuse noisy multimodal data. Various related works【16】【17】【18】 indicate that multimodal models outperform their unimodal counterparts. This can be attributed to the ability of multimodal data to leverage correlations between different modalities to identify and mitigate potential noise.
Multimodal noise can be roughly classified into two categories based on its source: 1) Modality-specific noise, arising from sensor errors, environmental factors, or transmission in each modality; 2) Cross-modal noise, arising from misaligned multimodal pairs, which can be viewed as noise at the semantic level.

Incomplete Multimodal Learning
Multimodal data collected in real applications is often incomplete, with some modalities missing for certain samples due to unforeseen factors (e.g., device failure, data transmission, and storage loss). For instance, in user-facing recommendation systems, browsing behavior history and credit score information may not always be available for certain users【48】. Similarly, while combining data from various modalities, such as MRI scans, PET scans, and CSF information, can provide more accurate diagnoses for Alzheimer’s disease【49】【50】, some patients may refuse these examinations due to the high measurement costs of PET scans and the invasive discomfort of CSF tests. Therefore, incomplete multimodal data is common in Alzheimer’s disease diagnosis【51】. Typically, traditional multimodal learning models assume the completeness of multimodal data and thus cannot be directly applied to cases with missing modalities. To address this issue, incomplete multimodal learning that aims to explore information from incomplete multimodal data with partially missing modalities has emerged and received increasing research attention in recent years【52】. In this section, we primarily focus on the current progress in incomplete multimodal learning research. From the perspective of whether to impute missing data, we classify existing methods into two main categories: imputation-based and non-imputation incomplete multimodal learning, with imputation-based methods further divided into two groups, as shown in Figure 2, including instance-level and modality-level imputation.
Balanced Multimodal Learning
Different modalities are closely related as they describe the same concept from different perspectives. This property has spurred the rise of multimodal learning, where various modalities are integrated to enhance understanding of related events or objects. However, despite the natural cross-modal correlations, each modality has its unique data sources and forms. For example, audio data typically manifests as one-dimensional waveforms, while visual data consists of images made up of pixels. On one hand, this difference endows each modality with different attributes, such as convergence speed, making it difficult to process and learn from all modalities simultaneously, posing challenges to joint multimodal learning. On the other hand, this difference is also reflected in the quality of unimodal data. Although all modalities describe the same concept, the amount of information related to the target event or object varies. For instance, consider a visual-audio sample labeled as a meeting; the visual data clearly displays the visual content of the meeting, which is easily recognizable (see Figure 1c). In contrast, the corresponding audio data is filled with the noisy sounds of street cars, making it difficult to establish a connection with the meeting label. The visual modality clearly contains more information than the audio modality. Due to the greedy nature of deep neural networks【9】, multimodal models tend to rely solely on high-quality modalities with abundant target-related information while underfitting other modalities. To address these challenges and improve the performance of multimodal models, recent research has focused on strategies to balance the differences between modalities and enhance the overall performance of the models.
Dynamic Multimodal Fusion
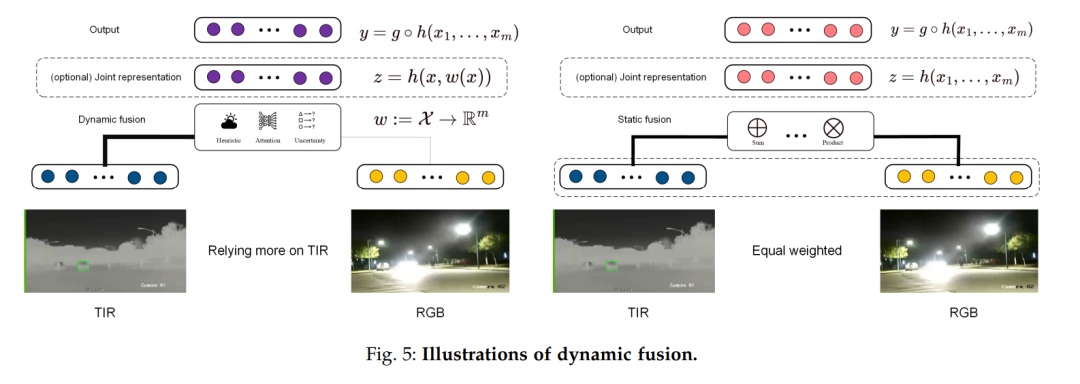
Current multimodal fusion methods often rely on the assumption that the quality of multimodal data is static, which does not always hold true in real-world scenarios. Handling multimodal data with dynamically changing quality is an inevitable issue for multimodal intelligent systems. Due to unexpected environmental factors and sensor issues, some modalities may suffer from poor reliability and loss of task-specific information. Moreover, the quality of different modalities can vary dynamically depending on the scene, as illustrated in Figure 5. This phenomenon has inspired a new multimodal learning paradigm, known as dynamic multimodal fusion, aimed at adapting to the dynamic changes in multimodal data quality and selectively integrating task-specific information. In this section, we focus on the challenges of dynamic multimodal fusion and classify the advancements in the current literature into three main directions: heuristic, attention-based, and uncertainty-aware dynamic fusion.
Convenient Access to Information
Convenient Download, please follow the Special Knowledge public account (click the blue Special Knowledge above to follow)
Reply or send a message “MFLD” to obtain the download link for the “Review on Multimodal Fusion of Low-Quality Data” from Special Knowledge

Click “Read Original” to learn how to use Special Knowledge to access over 100,000 AI-themed knowledge resources