

This is a work by Big Data Digest, please refer to the end of the article for reproduction requirements.
Original Author | Adam Geitgey
Translation | Wu Shuang, Da Li, Da Jieqiong, Aileen
To know oneself and one’s enemy, whether you want to become a hacker (which is not recommended!) or prevent future hacking intrusions, it is essential to understand how to deceive deep learning models trained on massive amounts of data.
As long as there are programmers coding, hackers will relentlessly seek ways to exploit these programs. Malicious hackers will take advantage of even the smallest vulnerabilities in the code to infiltrate systems, steal data, and cause significant damage.
But systems driven by deep learning algorithms should be able to avoid human interference, right? How can a hacker break through a neural network trained on terabytes of data?
However, it turns out that even the most advanced deep neural networks can be easily fooled. With just a few tricks, you can force the model to predict any result you desire:
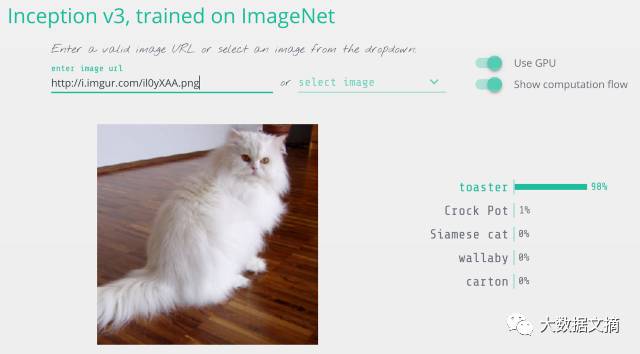
We can modify the above image of a cat so that it is recognized by the model as a toaster.
Therefore, before you enable a new system driven by deep neural networks, let’s take a detailed look at how to compromise the system and how to protect your system from hacker attacks.
Neural Networks Help Protect Cybersecurity
Now let’s assume we run an auction site like eBay. On our site, we want to prevent people from selling prohibited items—like live animals.
But if you have millions of users, enforcing these rules can be very difficult. We could hire hundreds of people to manually review each auction listing, but that would undoubtedly be very expensive. Instead, we can use deep learning to automatically check auction photos for prohibited items and flag those images.
This is a typical image classification problem. To build this model, we will train a deep convolutional neural network to identify prohibited items from compliant items, and then run the identification model on all photos on the site.
First, we need a dataset containing thousands of auction images based on historical auction listings. The dataset should include images of both compliant and prohibited items so that we can train the neural network to distinguish between them:

Next, we begin training the neural network, using the standard backpropagation algorithm. The principle of this algorithm is that we pass a training image through the network along with the expected result, then go back through each layer of the neural network to slightly adjust their weights to make the model better produce the correct output for that image:
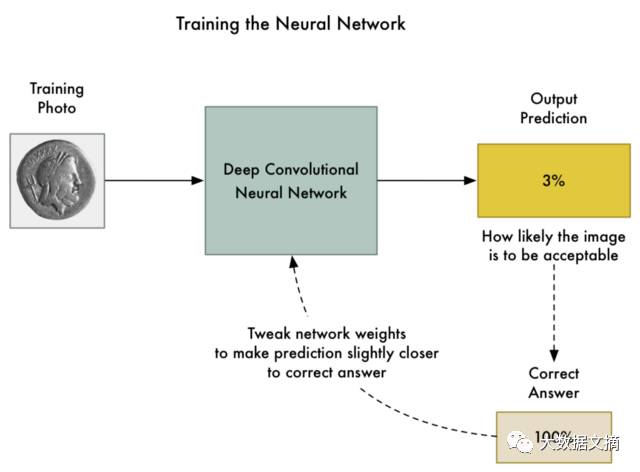
We repeat the above process thousands of times with thousands of different photos until the model produces the correct results with acceptable accuracy consistently.
Eventually, we will have a neural network model that can reliably classify images:
But things are often not as reliable as they seem…
Convolutional neural networks are very powerful for overall image recognition and classification. They are not affected by the position of complex shapes and patterns within the image. In many image recognition tasks, their performance can rival or even surpass that of humans.
For such advanced models, small changes to some pixels in the image should not significantly affect the final prediction result, right? Yes, it might slightly change the probability of the prediction, but it shouldn’t change the prediction from “prohibited” to “compliant.”
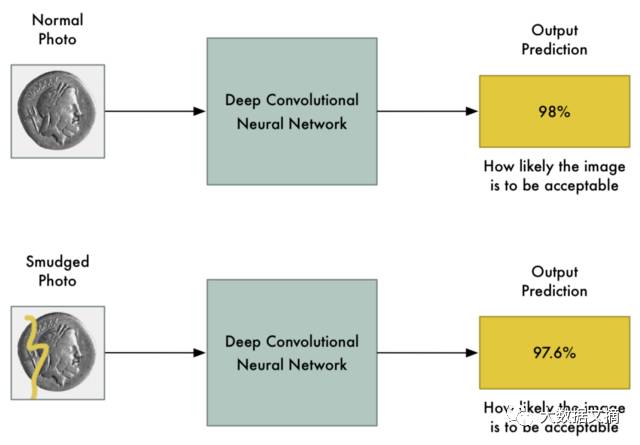
What we expect is that small changes to the input photo will only cause small changes to the final prediction.
However, a famous paper from 2013, “Intriguing Properties of Neural Networks,” found that this is not always the case. If you know exactly which pixels to change and by how much, you can deliberately force a neural network to make incorrect predictions for a given image without making significant alterations to its appearance.
This means we can intentionally create an image that is clearly a prohibited item but make it completely fool our neural network model.
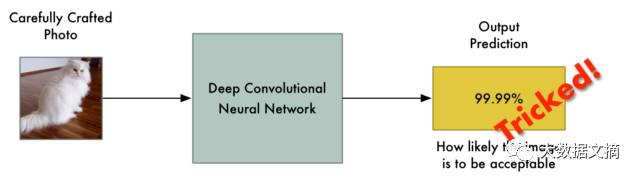
How can this be? The way machine learning classifiers work is by finding the decision boundary that distinguishes between things. The following illustration shows a simple two-dimensional classifier that learns to separate green balls (compliant) from red balls (prohibited):
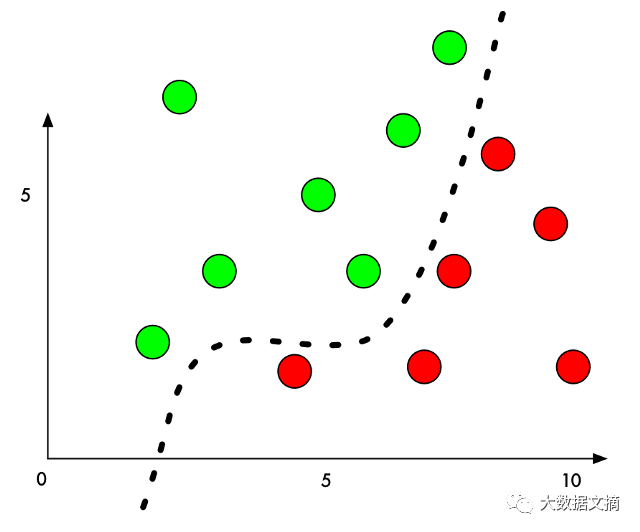
Now, the classifier has achieved 100% accuracy. It has found a boundary that perfectly separates all the green balls from the red balls.
However, if we want to adjust the model so that a red ball is intentionally classified as a green ball, how much do we need to move the red ball to push it into the green ball’s classification area?
If we slightly increase the Y value of the red ball next to the boundary, we can almost push it into the green ball’s classification area:
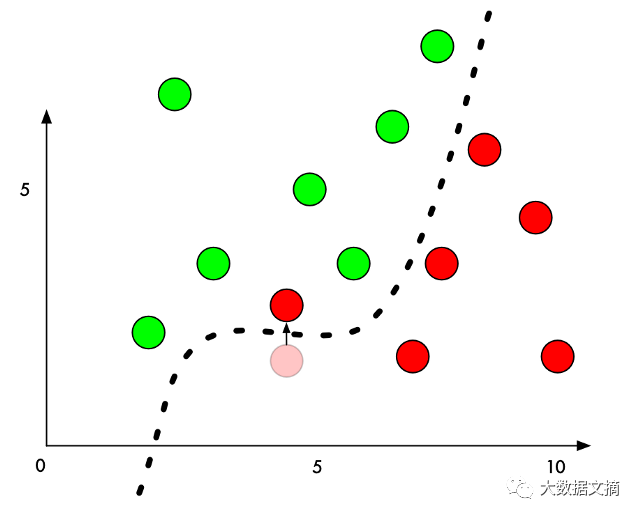
So to deceive a classifier, we just need to know which direction to push this point to get it across the decision boundary. If we don’t want the change to be too obvious, ideally we would make the move as small as possible, so it appears to be an unintentional mistake.
When using deep neural networks for image classification, each “point” we classify is actually a complete image made up of thousands of pixels. This gives us thousands of possible values we can fine-tune to push the prediction across the decision line. If we can ensure that our adjustments to the pixel points in the image are not visibly obvious, we can achieve this while tricking the classifier without making the image appear tampered with.
In other words, we can take an image of a real object and make very slight modifications to specific pixel points so that the image is completely recognized by the neural network as another object—and we can precisely control what that substitute is:
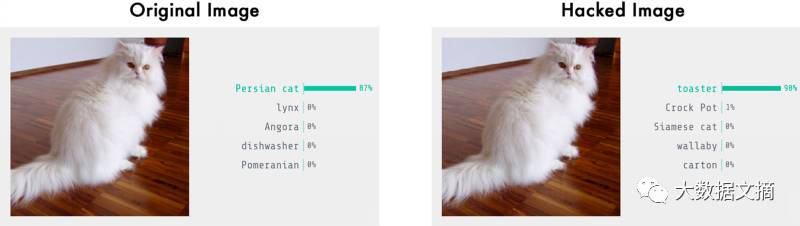
Turning a cat into a toaster. The image detection results are from the Keras.js web demo: https://transcranial.github.io/keras-js/#/inception-v3
How to Fool Neural Networks
We have previously discussed the basic process of training a neural network to classify photos:
1. Add a training image;
2. Check the neural network’s prediction results to see how far it is from the correct answer;
3. Use the backpropagation algorithm to adjust the weights of each layer in the neural network to bring the prediction closer to the correct answer.
4. Repeat steps 1-3 on thousands of different training photos.
So, compared to adjusting the weights of each layer in the neural network, what if we directly modify the input image itself until we get the answer we want?
So we selected a pre-trained neural network and “trained” it again, but this time we will use the backpropagation algorithm to directly adjust the input image instead of the weights of the neural network layers:
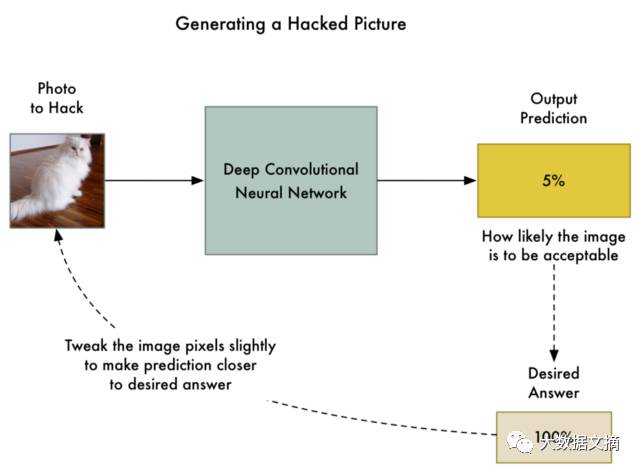
So here is the new algorithm:
1. Add a photo we want to “fool.”
2. Check the neural network’s prediction results to see how far it is from our desired answer.
3. Use the backpropagation algorithm to adjust the photo itself to bring the prediction result closer to our desired answer.
4. Repeat steps 1-3 with the same photo thousands of times until the neural network outputs the result we want.
After this, we will have an image that can fool the neural network without changing the neural network itself.
The only problem is that since the algorithm has no restrictions on adjustments, allowing any pixel point to be adjusted to any scale, the final result of the image change may be large enough to be obvious: they might have color spots or wavy areas.

An image that has been “fooled” shows green spots around the cat and wavy patterns on the white wall due to no constraints on the adjustments to pixel points.
To prevent these obvious distortions, we can impose a simple constraint on the algorithm. We limit the change of each pixel in the altered image to a small value, such as 0.01%. This allows the algorithm to still fool the neural network while not deviating too much from the original image.
The image generated after adding the constraint is as follows:

The “fooled” image generated under the condition that each pixel can only change within a certain range.
Even though this image appears unchanged to the human eye, it can fool the neural network!
Now Let’s Code
First, we need a pre-trained neural network to fool. We won’t start training from scratch but will use the neural network created by Google.
Keras is a well-known deep learning framework that includes several pre-trained neural networks. We will use a copy of Google’s Inception v3 deep learning neural network, which has been trained to detect over a thousand different objects.
Here is the basic code in Keras for image recognition using this neural network. (Text code can be found at the link) https://gist.github.com/ageitgey/8a010ee99f55fe2ef93cae7d02e170e8#file-predict-py
Before proceeding, make sure you have Python 3 and Keras installed:
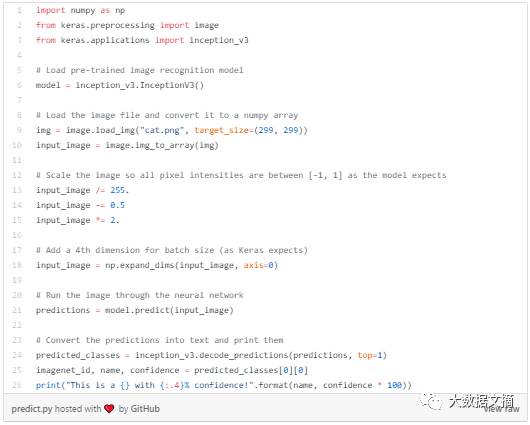
After running it, it correctly identified our image as a Persian cat:

Now we will slightly alter the image until we can fool this neural network into thinking the image is a toaster.
Keras does not have a built-in method to train through input images; it only trains the neural network layers, so I had to enhance my skills to manually write the training steps code.
Here is my code: (Text code can be found at the link) https://gist.github.com/ageitgey/873e74b7f3a75b435dcab1dcf4a88131#file-generated_hacked_image-py




After running, we can finally obtain an image that can fool the neural network.

Note: If you do not have a GPU, this may take several hours to run. If you do and have configured Keras and CUDA, it should take only a few minutes.
Now we will put the altered image back into the original model to test if it was successful.

We did it! The neural network was fooled into thinking the cat was a toaster!
What Can We Do with the “Fooled” Image?
This operation of creating “fooled” images is known as “creating adversarial examples.” We are intentionally generating data that causes machine learning models to produce errors. This operation is clever, but what practical uses does it have in real life?
Researchers have found that these altered images have some surprising properties:
-
When “fooled” images are printed, they can still deceive neural networks! Therefore, you can use these special images to fool cameras and scanners, not just systems that upload images from computers.
-
Once a neural network is fooled, if other neural networks are trained on similar data, even if they are designed completely differently, they can also be fooled by these special images.
Thus, we can do many things with these altered images!
However, there are many limitations on how we create these special images—we need to have access to the neural network to manipulate it directly. Because we are essentially “training” the neural network to deceive itself, we need a copy of it. In real life, no company would allow you to download their trained neural network code, meaning we cannot perform this type of attack… right?
Not at all! Researchers have recently discovered that we can mirror the movements of another neural network to synchronize our network, training our alternative neural network.
Then you can use the alternative neural network to generate “fooled” images that can still fool the original network! This is called a black-box attack.
This type of attack is limitless in scope and can have terrifying consequences! Here are some examples of what hackers could do:
-
Fool self-driving cars into thinking that a “stop” sign is a green light—this could cause accidents!
-
Deceive content filtering systems into failing to recognize offensive and illegal information.
-
Trick ATM check scanning systems into misidentifying the actual amount of money on the check. (If you get caught, you could reasonably deflect blame!)
These attack methods are not limited to image alterations. You can use the same approach to deceive classifiers that process other types of data. For example, you could fool virus scanners into misidentifying your virus as safe!
How Can We Prevent Such Attacks?
Now that we know that neural networks can be fooled (as can other machine learning models), how can we prevent this?
Simply put, no one has been able to guarantee complete security. Methods to prevent these types of attacks are still under research. To stay updated with the latest research, the best way is to follow the cleverhans blog by Ian Goodfellow and Nicolas Papernot, who are the most influential researchers in this field.
However, some things we currently know are:
-
If you simply create many “fooled” images and include them in your subsequent training data, this will make your neural network more resistant to these attacks. We call this adversarial training, and it may be the most viable defensive measure at this time.
-
Another effective method is called defensive distillation, where another model is trained to mimic your original model. But this is a new and quite complex method, so unless there is a specific need, I don’t want to delve into this further.
-
So far, researchers have tried every conceivable method to defend against these attacks and have failed.
Since we don’t have a final conclusion yet, I suggest you consider what risks such attacks might pose to your work when using neural networks, at least to mitigate some risks.
For example, if you have a single machine learning model as the only security line for identifying confidential information, even if it cannot be fooled, that is not a good idea. But if you are using machine learning as an intermediary process and still have human verification, it may be fine.
In other words, treat machine learning models, like other methods, as not completely reliable technology. Think about what consequences a user could face if they intentionally hacked your system to deceive your network, and how you need to handle it to mitigate that risk.
Learn More
Want to learn more about adversarial examples and how to protect against attacks? Here are some related resources:
-
This field of research is still young, and reading some key papers can get you started: “Intriguing Properties of Neural Networks” (https://arxiv.org/abs/1312.6199), “Explaining and Harnessing Adversarial Examples” (https://arxiv.org/abs/1412.6572), “Practical Black-Box Attacks Against Machine Learning” (https://arxiv.org/abs/1602.02697), and “Adversarial Examples in the Real World” (https://arxiv.org/abs/1607.02533).
-
Follow Ian Goodfellow and Nicolas Papernot’s cleverhans blog to keep up with the latest research developments: http://www.cleverhans.io/.
-
Check out ongoing Kaggle competitions where researchers are figuring out new ways to defend against these attacks.
Original link: https://medium.com/@ageitgey/machine-learning-is-fun-part-8-how-to-intentionally-trick-neural-networks-b55da32b7196
Recommended AI Courses
High quality, high density, low price
Super high cost-performance ratio courses are back
Limited-time offer599 yuan
Series courses register together for more surprise discounts
Reply “Volunteer” to join us




Click the image to read
Summary of Major Hacking Events in the First Half of 2017


