
As we all know, Zuckerberg’s Meta has open-sourced Llama3 with two versions: the 8B and 70B pretrained and instruction-tuned models. There is also a larger 400B parameter version expected to be released this summer, which may be the first open-source model at the GPT-4 level!
Let’s start with a preliminary understanding of Llama3.
Model Architecture
Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The adjusted version employs supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for usefulness and safety.
Relevant Parameters
| Training Data | Parameter Count | Context Length | Grouped Query Attention (GQA) | Pretraining Data | Knowledge Cutoff Date | |
| Llama 3 | Public Online Datasets | 8B | 8K | Yes | 15T+ | March 2023 |
| Llama 3 | 70B | 8K | Yes | 15T+ | December 2023 |
The Llama3 model was trained in two data center clusters newly built by Meta, including over 49,000 NVIDIA H100 GPUs.
Installation Instructions
For the installation of Ollama, please refer to previous articles; I won’t elaborate further here.
Google has open-sourced Gemma, here is the local deployment guide!
Pulling Llama3
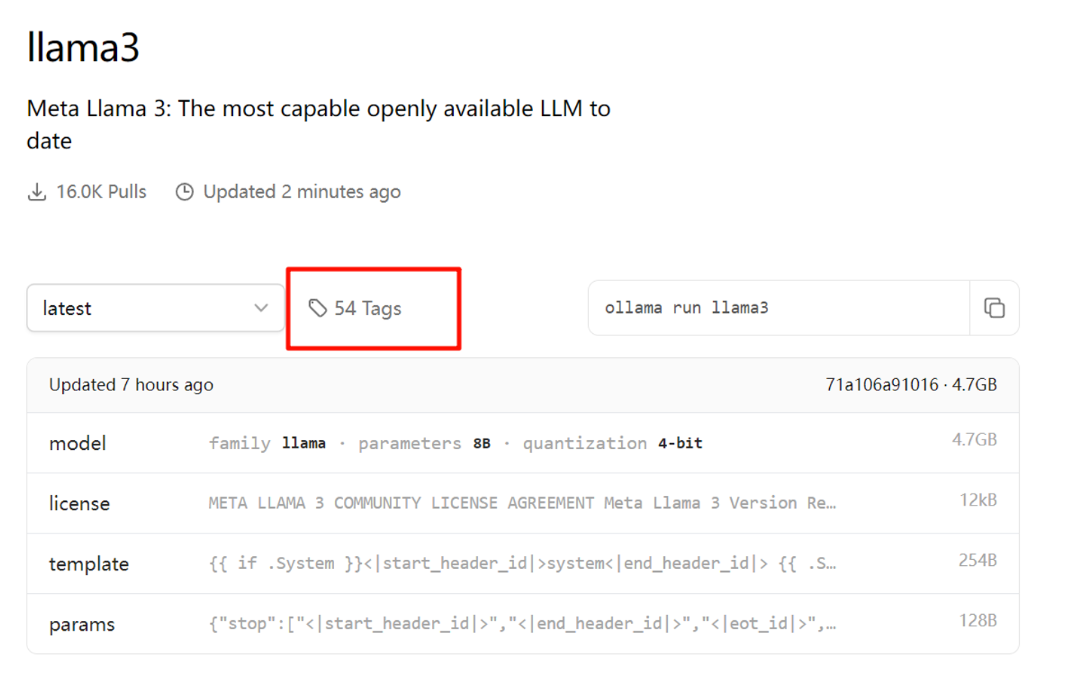
In just a few hours, 54 tags have already been updated.
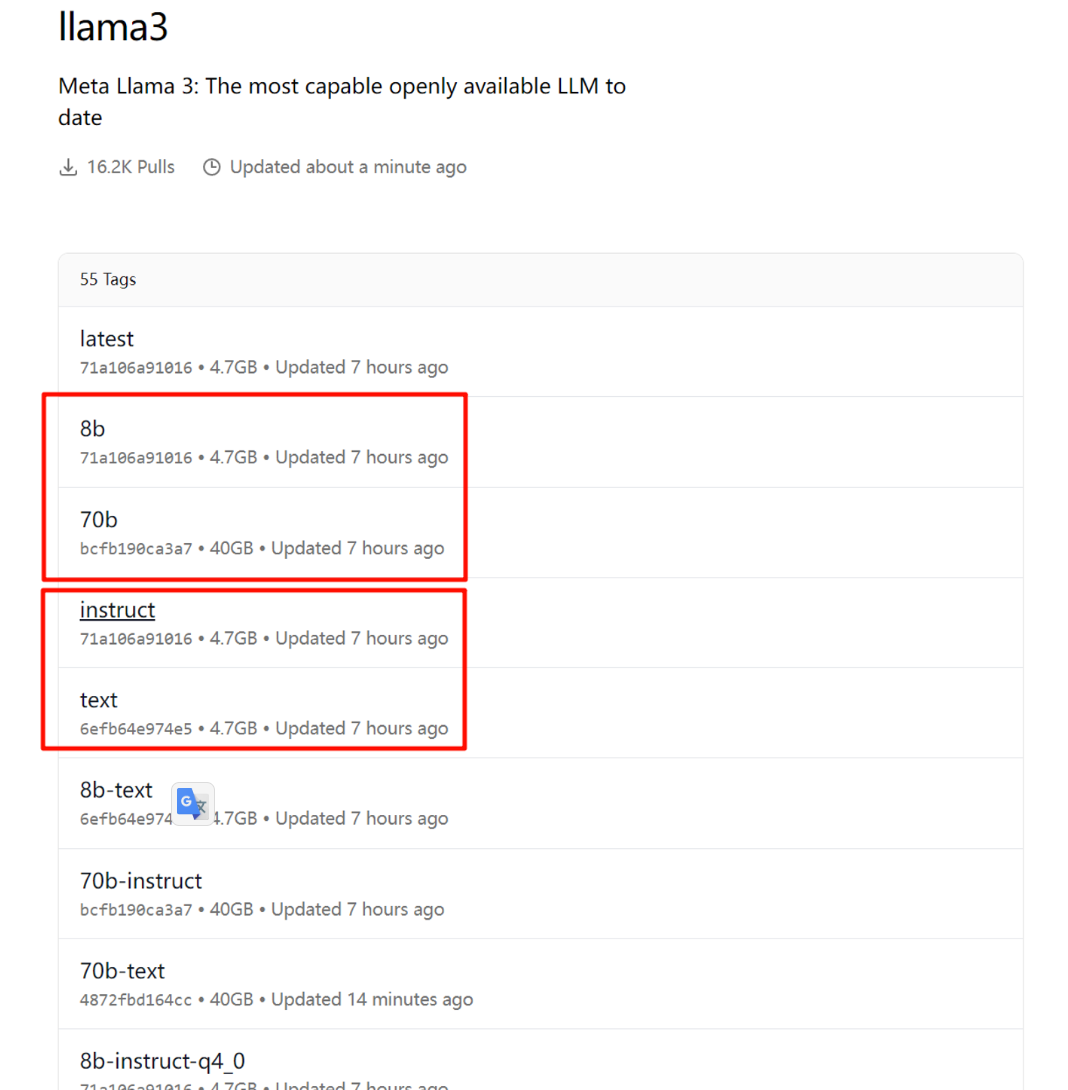
Currently, it is recommended to pull these four versions; other quantized versions have been adjusted by unknown users.
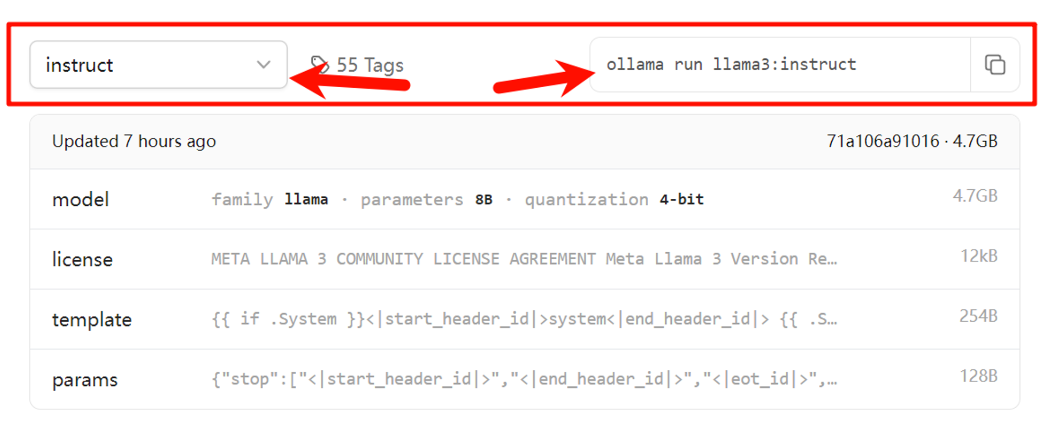
On the left side is the version dropdown selection; the selected version will display the pull code in the code window on the right. Just click the copy icon and paste it into the CMD or PowerShell terminal.
Note: This example is for Windows users.

Just like this, press Enter to start pulling Llama3 (the pulling speed for domestic users is also very fast).
Using Llama3
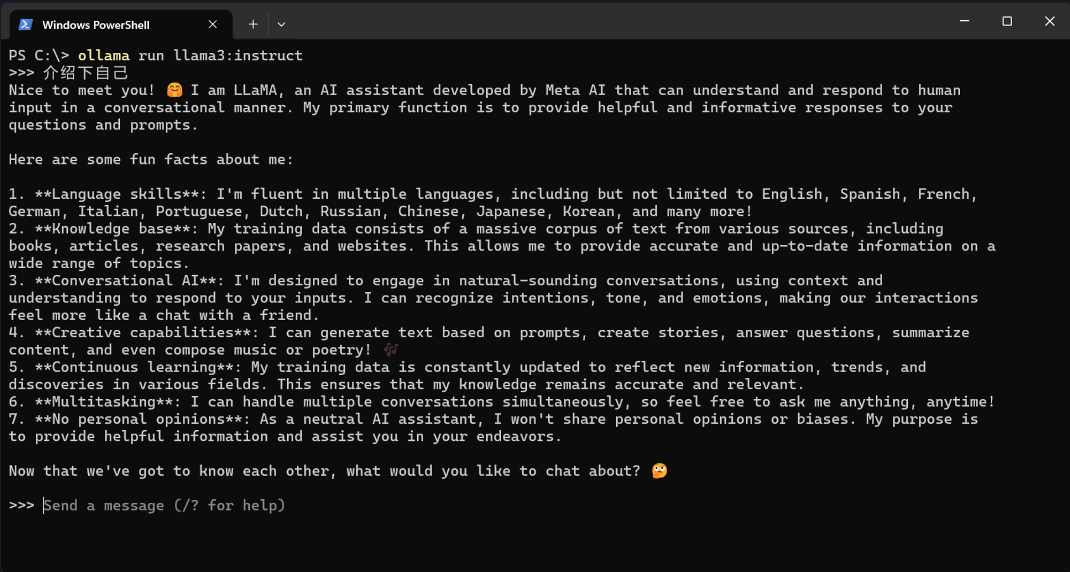

Llama3_8B generates very quickly; this version runs fine with an 8GB NVIDIA card.
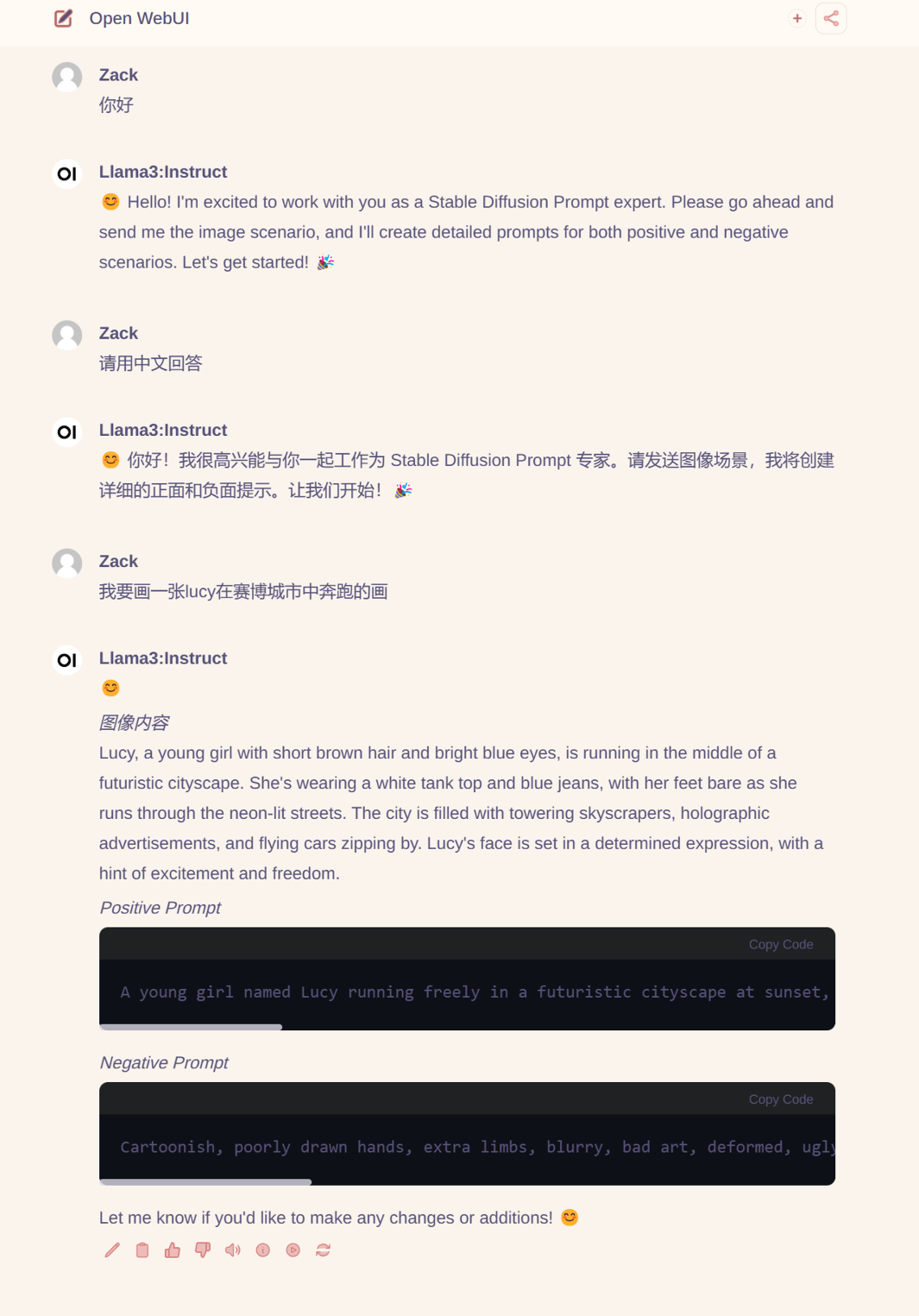
Next, let’s try setting the SD instruction master system prompt with Open WebUI to test the understanding of instructions, which works perfectly.

