
Today, I will share a retrieval-augmented generation method designed for resource-constrained scenarios: MiniRAG.

Paper link: https://arxiv.org/pdf/2501.06713
Code link: https://github.com/HKUDS/MiniRAG
Introduction
With the rapid development of retrieval-augmented generation (RAG) technology, the performance of language models in knowledge retrieval and generation tasks has significantly improved. However, existing methods heavily rely on large language models (LLMs), leading to high computational costs and resource demands, making it difficult to adapt to resource-constrained scenarios such as edge devices and privacy-sensitive applications. When trying to utilize small language models (SLMs) to reduce costs, existing RAG frameworks perform poorly in semantic understanding and retrieval efficiency, resulting in a significant drop in performance or even failure to run. To address this, the University of Hong Kong proposed MiniRAG, which aims to achieve an extremely minimal and efficient RAG system. MiniRAG introduces two key technological innovations:
-
Heterogeneous Graph Indexing Mechanism: Combines text blocks and named entities into a unified structure, reducing the reliance on complex semantic understanding.
-
Lightweight Topology-Augmented Retrieval: Utilizes graph structures for efficient knowledge search without requiring advanced language capabilities.
Experimental results show that MiniRAG achieves performance comparable to LLM-based methods while occupying only 25% of the storage space.
Method
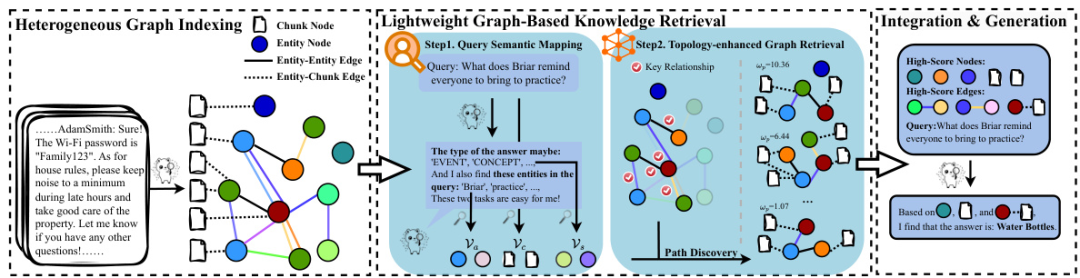
As shown in the figure above, the MiniRAG framework consists of two main components: Heterogeneous Graph Indexing and Lightweight Graph-Based Knowledge Retrieval. Below is a detailed introduction to each component:
1. Heterogeneous Graph Indexing
The Heterogeneous Graph Indexing is the first step of the MiniRAG framework, aiming to provide rich semantic information for subsequent knowledge retrieval by constructing a graph structure containing various types of nodes and edges. The graph consists of two types of nodes, two types of edges, and semantic descriptions:
-
Text Fragment Nodes: Represents coherent segments extracted from the original text, preserving contextual integrity.
-
Entity Nodes: Represents key semantic elements extracted from text fragments, such as events, locations, times, or domain-specific concepts.
-
Entity-Entity Connections: Captures semantic relationships and hierarchies between named entities.
-
Entity-Fragment Connections: Connects entities with their contextual fragments, ensuring semantic and contextual consistency.
-
Semantic Descriptions: Adds language model-generated semantic descriptions to entity-text block connections, providing explicit relational context and supplementing entity information. Each entity-fragment edge is associated with a descriptive text, detailing the semantic relationship between the entity and the text fragment.
Through these steps, MiniRAG constructs a heterogeneous graph:
2. Lightweight Graph-Based Knowledge Retrieval
In the second part, MiniRAG focuses on how to efficiently conduct knowledge retrieval on the device side, especially under resource constraints (such as limitations in computational power and data privacy). MiniRAG proposes a graph-based knowledge retrieval mechanism that uses lightweight text embedding models and semantically aware heterogeneous graphs to improve retrieval efficiency and accuracy. It consists of two main parts: Query Semantic Mapping and Topology-Augmented Graph Retrieval.
2.1 Query Semantic Mapping
During the retrieval phase, MiniRAG aims to identify elements (such as text fragments) related to the user-input query from the already constructed heterogeneous graph index. The specific process is as follows:
-
Entity Extraction: Uses small language models to extract relevant entities from the query (such as events, locations, people, etc.) and predict the possible types of these entities.
-
Lightweight Sentence Embedding: Utilizes lightweight sentence embedding models to calculate the semantic similarity between query entities and all entity nodes in the graph, thus effectively conducting node retrieval.
-
Query-Guided Inference Path Discovery: MiniRAG employs a query-guided inference path discovery mechanism to effectively capture inference chains related to the query through the following steps:
-
Initial Entity Identification: Matches entities in the query with nodes in the graph to determine the starting point of the path. -
Answer-Aware Entity Selection: Selects the entity most likely to serve as the answer from the starting nodes based on the predicted answer type. -
Context-Rich Path Formation: Forms inference paths containing rich evidence chains by incorporating relevant text fragments.
2.2 Topology-Augmented Graph Retrieval
The goal of this part is to find a comprehensive evidence chain connecting the query entities and potential answers within the graph index, that is, the inference path. The main steps are as follows:
-
Key Relationship Identification: Identifies entity-entity connections related to the query in the graph through node-edge interactions, calculates relevance scores based on distances to the starting and answer nodes, and selects high-ranking edges to construct a key relationship set.
-
Query-Guided Path Discovery: Defines a candidate inference path set and quantifies the importance and query relevance of paths using an entity-conditioned scoring function, selecting high-scoring paths to construct the final inference path set.
-
Query-Relevant Text Block Retrieval: Collects all text blocks related to the entity nodes in the inference path through entity-text block connections.
2.3 Integration & Generation
Finally, MiniRAG combines the two key pieces of information obtained through the topology-augmented retrieval mechanism and multi-stage filtering process (namely important relationships and best text blocks) to form a comprehensive, structured input representation for generation tasks. This integration strategy enhances the accuracy and reliability of the generated outputs.
Conclusion
MiniRAG adopts innovative heterogeneous graph indexing and lightweight heuristic retrieval mechanisms, successfully integrating the advantages of text-based and graph-based RAG methods while significantly reducing reliance on language model capabilities, effectively addressing the challenges of information retrieval and generation in resource-constrained environments. While ensuring efficiency, MiniRAG significantly enhances the performance of small language models in complex tasks, especially suitable for environments with edge computing and other constrained devices.