
By: This article is translated from the English paper “Generate Impressive Videos with Text Instructions: A Review of OpenAI Sora, Stable Diffusion, Lumiere and Comparable Models” (KARAARSLAN, Enis; AYDIN, Ömer, 2024) using software, and has not been polished. Errors and omissions are inevitable. For interested readers, it is recommended to read the original paper.
In the field of computer science, the process of converting text input into video has always faced significant computational challenges. However, the rapid development of text-to-video artificial intelligence (AI) technology in recent years indicates significant progress in this field. Looking to the future, breakthroughs in realistic video generation technology and data-driven physical simulation will strongly propel this field toward new heights. The rise of text-to-video AI not only has revolutionary potential but also permeates multiple creative fields, such as film production, advertising planning, graphic design, game development, as well as social media, influencer marketing, and educational technology. This study aims to comprehensively examine the methodologies of generative AI in text-to-video synthesis, particularly focusing on the in-depth exploration of large language models and AI architectures. To achieve this goal, various methods such as literature review, technical assessment, and solution proposals have been employed. In this process, well-known models in the industry, such as OpenAI Sora, Stable Diffusion, and Lumiere, have been evaluated for their effectiveness and the complexity of their architectures. However, the pursuit of artificial general intelligence (AGI) also faces many challenges. These challenges include but are not limited to human rights protection, preventing potential misuse of technology, and safeguarding intellectual property. This study aims to explore feasible ways to address these challenges and propose practical solutions to promote environmentally friendly and computational efficiency in the context of text-to-video AI.
1. Introduction
With the wave of digitization sweeping across, the advancement and evolution of technological knowledge have received unprecedented impetus. In recent years, significant achievements in the field of artificial intelligence (AI) have been particularly noteworthy. This leap in technology has been driven by the surge in hardware capacity, enhanced processing power of computer systems, and the increasing prevalence of cloud and edge computing paradigms. In the AI field, the rapid advancement of computing capabilities and the continuous optimization of AI algorithms complement each other, jointly enhancing the efficiency and practicality of AI models. As a result, AI has penetrated various industries and become a vital force driving social progress.
In this context, leading companies like OpenAI have launched their own AI models and tools, leading the technological trend. Notably, OpenAI’s ChatGPT chatbot, released in November 2022, has received widespread acclaim globally. Subsequently, OpenAI capitalized on this success by releasing the GPT-4 version, further enhancing its AI model’s capabilities in image processing. Looking ahead, OpenAI’s efforts in utilizing AI to create videos from text remain promising. Although these technological breakthroughs require substantial computational resources, the existing technological environment suggests that achieving the necessary processing power is no longer an unattainable dream.
The core objective of this study is to explore the broad application prospects brought by the text-to-video capabilities of generative AI tools. To achieve this goal, we aim to answer the following key questions:
● How are the mainstream text-to-video synthesis models evaluated from a technical perspective? How do they address the challenges faced in generating realistic videos?
● What strategies can effectively ensure the authenticity and traceability of generated content during the text-to-video synthesis process?
● Considering the substantial consumption of power and water resources by transformer models, what environmental and computational challenges do we face? How can we formulate practical strategies to reduce these costs for long-term sustainability?
2. Basic Principles
This section will first clarify the fundamental concepts of large language models (LLMs), which are the primary drivers of modern chatbot technology and are gradually being integrated into the AI field. It will also explore the emerging capabilities of video generation in this context.
2.1 Large Language Models
Large language models (LLMs) represent a class of AI systems that excel in processing and generating natural language text. These systems utilize deep neural networks and are extensively trained on vast databases of text, including books, articles, web content, and social media discussions. Through this process, LLMs grasp the inherent complex patterns and structures of natural language, enabling them to perform various tasks, including question answering, text summarization, language translation, and article writing. However, despite their powerful capabilities, LLMs also have several issues that need attention. Concerns have been raised about potential biases in training data, factual inaccuracies, and a lack of ethical considerations in their design and operation. Furthermore, the opacity of LLM functions hinders their interpretability and transparency, making it difficult to discern the underlying principles behind their generated responses and operational methods.
2.2 Text-to-Image AI
Images are often elements that can be interpreted by text, but creating them requires special skills and effort. Illustrations, photographs, and paintings are examples in this regard. Therefore, a tool that can use natural language to generate realistic images can provide unprecedented convenience, allowing people to easily create unique visual content. The ability to edit images using natural language offers significant advantages for real-world applications that require iterative improvements and support detailed control.
The process of text-to-image (T2I) has been extensively studied in the literature, as evidenced by several studies (Ramesh et al., 2021; Yu et al., 2021; Yu et al., 2022; Ding et al., 2022; Gafni et al., 2022). Different text-to-image generation models have been developed based on diffusion models (Ho et al., 2020), such as GLIDE (Nichol et al., 2021), DALLE-2 (Ramesh et al., 2022), and Imagen (Saharia et al., 2022). GLIDE uses CLIP guidance at scale 2.0 and employs classifier-free guidance at scale 3.0 (Ho and Salimans, 2022), eliminating the need for CLIP reordering or curation. DALLE-2 enhances text-image alignment using the CLIP (Radford et al., 2021) feature space. Imagen utilizes a cascaded diffusion model to generate high-resolution videos, while subsequent models like VQ-diffusion (Gu et al., 2022) and latent diffusion models (LDMs) (Rombach et al., 2022) operate in the latent space of autoencoders to improve training efficiency. Our approach extends LDMs by expanding the 2D model into the spatiotemporal domain within latent space.
2.3 Development of Text-to-Video AI
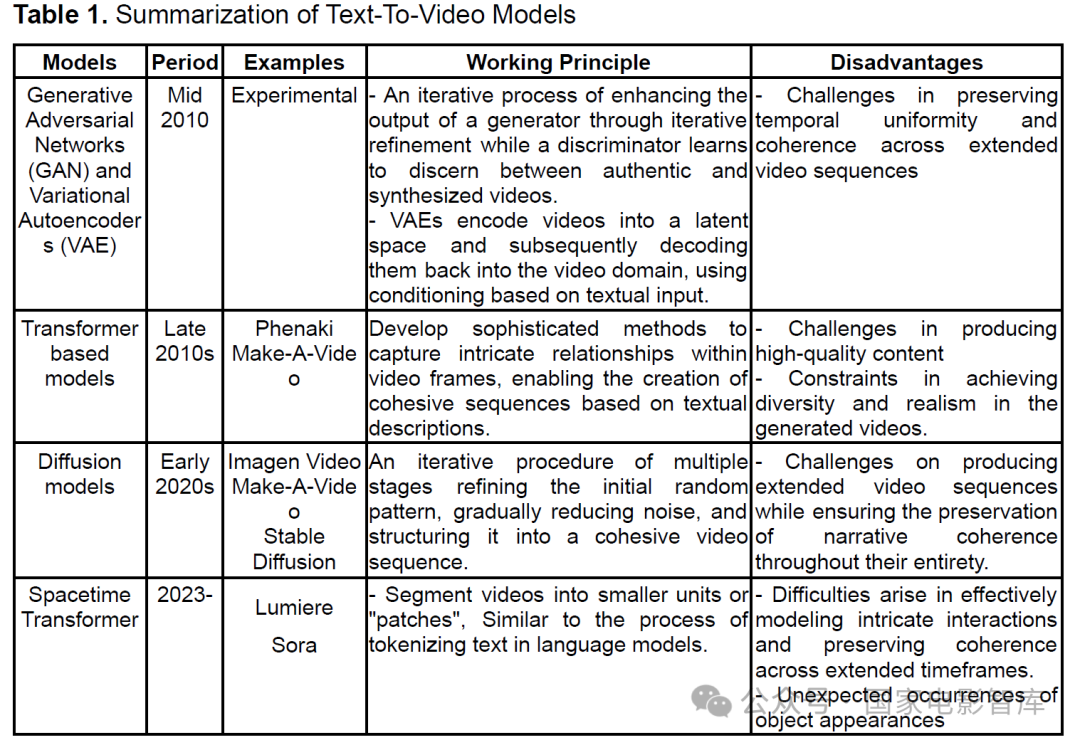
In the past, due to limitations in computational resources, creating videos from text was a challenging process. This often led to restrictions in resolution and complexity. However, with advancements in hardware and software solutions, this situation is improving. These models and their existing issues can be summarized in Table 1 (Martin, 2024).
The research can be summarized as follows: Lee et al. (2018) trained a conditional generative model to extract static and dynamic information from text in their study. They proposed a hybrid framework that combines variational autoencoders (VAE) and generative adversarial networks (GAN). This framework utilizes static features (i.e., “themes”) to represent background colors and object layout structures under text conditions. In contrast, dynamic features are incorporated by transforming the input text into image filters. To train deep learning models, they developed a method to automatically create matching text-video corpora from publicly available online videos. Experimental results demonstrate that the framework can generate realistic and diverse short videos, accurately conveying the information of the input text. From the perspective of the Inception score, commonly used to evaluate image generation in visual and GAN contexts, the framework outperformed the baseline model that directly applied the text-to-image generation process to video production (Le et al., 2018).
Balaji et al. (2019) discussed the development of conditional generative models for text-to-video synthesis, which is a challenging yet crucial aspect of machine learning research. They introduced the Text-Filtered Conditional Generative Adversarial Network (TFGAN), a conditional GAN model that adopts a novel multi-scale text conditioning scheme to enhance the association between text and video. The authors also created a synthetic dataset of text-conditioned moving shapes for systematic evaluation. Extensive experiments demonstrate that TFGAN significantly outperforms existing methods, showcasing its ability to generate new categories of videos not encountered during training.
Yan et al. (2021) introduced VideoGPT, an intuitive architecture for natural video generation modeling. VideoGPT employs VQ-VAE, utilizing 3D convolutions and axial self-attention to learn downsampled discrete latent representations of raw videos. Then, a GPT-like architecture is used to model these discrete latent variables in a spatiotemporal manner. Despite its simple architecture, VideoGPT achieves competitive results in video generation on the BAIR Robot dataset compared to state-of-the-art GAN models. It also demonstrates the ability to generate high-fidelity natural videos from UCF-101 and Tumbler GIF datasets (TGIF). The authors provide samples and code to ensure reproducibility, aiming to provide a minimized implementation of a transformer-based video generation model (Yan et al., 2021).
Liu et al. (2023) introduced “Generative Disco,” a generative AI system designed specifically for text-to-video generation, aimed at enhancing music visualization. This system recognizes the complexity and resource intensity of traditional music visualization creation, thus leveraging large language models to assist users in visualizing music intervals. It achieves this by identifying prompts describing images at the start and end of intervals and interpolating between them to synchronize with musical beats. The authors propose design patterns, namely transitions (for changes in color, time, theme, or style) and holds (to focus on subjects), to enhance the quality of generated videos. A study conducted in collaboration with professionals indicates that these patterns provide a highly expressive framework capable of creating coherent visual narratives. Their paper ultimately emphasizes the universality of these design patterns and the potential of generative video for creative professionals.
3. Methods
This study adopts multiple methodologies. It primarily serves as a literature review while also conducting technical assessments of specific text-to-video generation models, including OpenAI Sora, Stable Diffusion, and Lumiere. The core of this assessment lies in elucidating the inherent advantages and disadvantages of these models. Subsequently, a comparative analysis was conducted, carefully examining selected AI models used for generating videos from text, and conducting an in-depth analysis of their architectures, performances, and technical details for comprehensive comparison.
4. Major Model Evaluations
4.1 Lumiere
Lumiere is a text-to-video diffusion model designed to create realistic and coherent motion in synthesized videos, addressing a key challenge in video synthesis. The model employs a Space-Time U-Net architecture, capable of generating the entire video length in a single operation. This contrasts with existing models that use remote keyframes and temporal super-resolution methods, making global temporal consistency a challenge.
Lumiere utilizes spatial and temporal downsampling and upsampling, along with a pre-trained text-to-image diffusion model, to generate full-frame rate, low-resolution videos across multiple spatiotemporal scales. The model achieves state-of-the-art results in text-to-video generation, demonstrating its versatility in various content creation tasks and video editing applications, such as image-to-video, video restoration, and stylized generation (Lumiere, 2024).
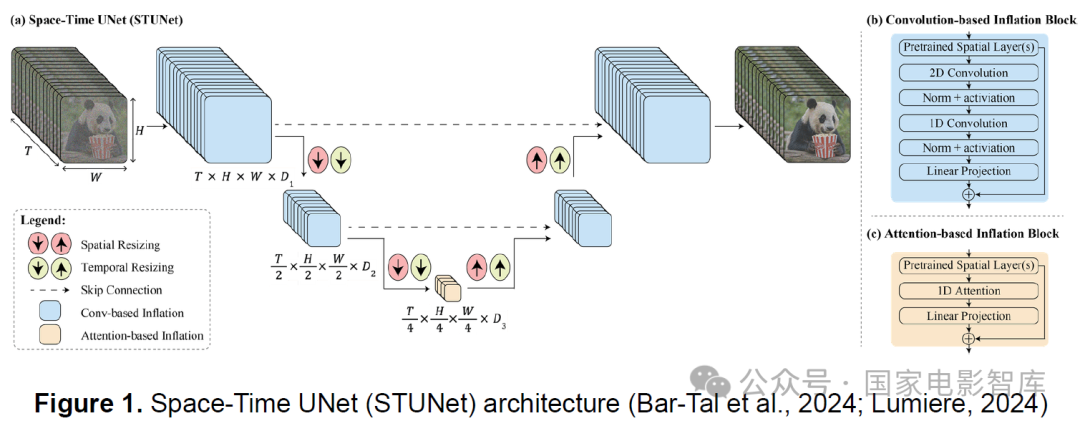
Bar-Tal et al. (2024) extended the pre-trained text-to-image (T2I) U-Net architecture (Ho et al., 2022) to a spatiotemporal UNet (STUNet). This STUNet performs spatial and temporal downsampling and upsampling on videos. Figure 1.a shows the activation map of STUNet, where colors represent features from different temporal modules. Figure 1.b illustrates convolution-based blocks composed of pre-trained T2I layers followed by decomposed spatiotemporal convolutions. Figure 1.c displays attention-based blocks at the coarsest U-Net level, where pre-trained T2I layers are followed by temporal attention (Bar-Tal et al., 2024).
4.2 Stable Diffusion
Stable Diffusion (Rombach et al., 2022) is an influential generative model in the field of text-to-image generation. The standout advantage of Stable Diffusion lies in its ability to produce high-quality images. This capability is based on improving throughput through multiple diffusion steps, increasing control by gradually adding noise, and facilitating image synthesis. Since 2022, Stable Diffusion version 1.1 has been continuously improved.
Using this version, the model’s ability to create realistic and specific thematic images can be better evaluated by analyzing the specific training results on custom datasets. Additionally, the Computer Vision and Learning Department at LMU Munich has provided an easily accessible Hugging Face-compatible format for Stable Diffusion version 1.1.
Hilado (2023) specialized in training Stable Diffusion 1.1 using the Pokémon dataset and achieved encouraging results. Common issues in pre-trained images, such as redundant text and inconsistencies like unrecognizable characters and style variations, were evident. This situation is illustrated in Figure 2.

Many images generated by Hilado’s fine-tuned model align more closely with features in the specific thematic dataset. Examples of such alignment include a white background, consistent character styles, and color usage. In the first prompt, the fine-tuned model generated only red and white images related to the character, while the pre-trained model included a character without red. The second prompt provided more instances of white backgrounds and consistent coloring in the fine-tuned model images. In the final prompt, the images generated by the pre-trained model deviated from the style of Pokémon characters compared to the fine-tuned model (Hilado, 2023).
4.3 OpenAI Sora
OpenAI Sora is an AI model designed to help people solve real-world problems. The development of this model aims to teach AI to understand and simulate the dynamic physical world. Sora is capable of creating videos up to one minute long according to user intentions while maintaining visual quality. Sora is presented to red team members to assess particularly critical areas and improve its model through feedback from creative professionals. Progress at each research stage is shared to demonstrate the capabilities of AI.
Sora is a model capable of accurately rendering complex scenes and deeply understanding language, able to comprehend prompts and create emotionally rich characters. However, the model also has some shortcomings, such as potential difficulties in simulating complex physical scenes and challenges in understanding certain causal relationships (Sora, 2024).
Sora is a diffusion model that starts with static noise and gradually eliminates this noise to create videos. It can create all frames of a video at once or extend existing videos. By using a single prediction for multiple frames, the model addresses the challenging issue of ensuring object consistency even when temporarily out of sight. With an architecture similar to GPT models, Sora achieves exceptional scalability.
Videos and images are represented as a collection of small data units called patches, enabling the model to train on a broader range of visual data. Based on DALL-E and GPT models, Sora can more faithfully follow text instructions using DALL-E 3’s captioning techniques. In addition to creating videos based on text instructions, the model can also create videos from existing images, animate images, extend existing videos, or fill in missing frames. Sora undertakes the fundamental tasks of understanding and simulating the real world.
Before Sora is used in OpenAI products, it will undergo various safety measures. The model will be tested with tools capable of detecting misleading content and will collaborate with red team members to address safety challenges. Future OpenAI products are also planned to incorporate C2PA metadata (https://c2pa.org/). Furthermore, security methods used in DALL-E 3 will be employed, utilizing text classifiers to check for policy violations in text entries while using robust image classifiers to review videos for compliance with usage policies. By communicating with policymakers, educators, and artists, we will understand relevant concerns and identify positive use cases for the technology. However, it may not be possible to anticipate all positive and negative use scenarios, making it crucial to emphasize the importance of learning from real-world usage processes (Sora, 2024).
An article co-authored by OpenAI researchers titled “Video generation models as world simulators” (OpenAI, 2024) provides important insights into the Sora model. The article emphasizes Sora’s ability to generate videos with different aspect ratios and resolutions. It showcases Sora’s flexibility in executing various image and video editing tasks, including creating looping videos and adjusting temporal factors, such as stretching forward or backward. Additionally, Sora can change the backgrounds of existing videos.
A particularly striking finding in the article is Sora’s ability to “simulate digital worlds.” Notably, the article describes an experiment where the word “Minecraft” was input into Sora, resulting in Sora skillfully generating a HUD, gameplay, and even replicating the game’s dynamics, including physics. This experiment demonstrates Sora’s capability to create and control player characters in simulated digital environments (Wiggers, 2024).
These findings not only highlight Sora’s powerful capabilities in video generation and editing but also signal its potential applications in broader fields such as game development and virtual world construction. As technology continues to evolve, we can expect Sora and similar models to bring us richer digital experiences and possibilities.
In AI-generated videos, achieving consistency and repeatability across multiple scenes has previously been a significant challenge. This is because it is difficult to fully understand the context and details from previous scenes or frames when creating each scene or frame separately and to incorporate them consistently into subsequent scenes. However, by integrating a comprehensive understanding of language, visual context, and accurately interpreting instructions, the model can maintain narrative coherence. Additionally, it can effectively portray the personality and emotions of characters based on instructions, making them stand out as compelling characters in the film.
Sora expands upon earlier research on generative image data models. Earlier studies employed various techniques, including diffusion models, autoregressive transformers, recurrent networks, and generative adversarial networks (GANs). However, these techniques were often limited to specific types of visual data, such as fixed sizes or short films. To break these limitations and generate films of varying lengths, aspect ratios, and resolutions, Sora has undergone extensive development (Kiuchi, 2024).
5. Results
The video “Pepperoni Hug Spot – AI-Generated Commercial” is an experimental fictional work created using artificial intelligence to shoot commercial videos, representing one of the early attempts at progress in this field. This video was generated by the Runway AI platform in April 2023. Initial observations show that the video exhibits semantic integrity, but upon closer inspection, viewers will find significant distortions and discrepancies with reality. The video describes a family, including a mother, father, a girl, and a boy, enjoying pizza. While this scene appears ordinary at first glance, a detailed analysis reveals distortions and deformities in the facial features and limbs of the characters, clearly indicating that the video was not filmed in the real world but created by a computer.
Despite some imperfections, the video marks a significant advancement for AI in the field of video generation. It demonstrates AI’s ability to generate coherent and engaging video content, although further optimization and refinement are needed in certain details. As technology continues to evolve, we can expect AI’s performance in video generation to increasingly approach the real world, bringing more innovations and possibilities to advertising, entertainment, and other fields.
Additionally, the video shared at https://openai.com/sora was generated by OpenAI’s Sora model based on the text of Prompt 1. This video was released nine months after the video generated by the Runway AI platform in April 2023. For non-professionals, it is challenging to distinguish between the newly generated AI video and a video filmed in the real world. The text of Prompt 1 contains six sentences, vividly describing the environment, accessories, clothing, and visual features of a woman, as well as the streets and other characters around her. OpenAI’s Sora model successfully generated a 59-second high-fidelity video, making it difficult for non-professionals to detect its artificial synthesis traces.

However, those who understand that the video is AI-generated may notice some slight logical and reality issues, particularly with the limbs of the woman and background characters, although these issues are not obvious. Experts in the field can easily spot these anomalies. Despite the only nine-month gap between these two examples, the significant and satisfactory acceleration of development is evident, manifested in the improvement of video quality and more realistic performances. As development continues, it is foreseeable that more realistic and longer AI-generated videos will soon become commonplace.
6. Risks and Limitations
The main risks and limitations associated with deploying transformers lie in computational and environmental aspects. It is widely recognized that using transformers requires substantial computational overhead and places high demands on GPU (graphics processing unit) capabilities. Prominent figures in the technology field, such as Elon Musk, have emphasized the potential impact of this demand on global power infrastructure. During the closing Q&A session of the Bosch Connected World conference in 2024, Musk expressed concerns about the availability of necessary power infrastructure, particularly transformers, to support the continuous operation of transformative technologies. He specifically warned of an impending shortage of transformer supply, attributing it to the growing deployment of AI (artificial intelligence) systems and the widespread adoption of electric vehicles (EVs), both of which place immense pressure on global energy resources. Musk’s remarks indicate that proactive measures must be taken to address expected challenges in the supply of power infrastructure to support the accelerated development of technological innovation.
Therefore, while promoting the development of AI video generation technology, we must recognize the potential risks posed by these technologies and strive to seek solutions to mitigate their impact on global power infrastructure. Additionally, we need to pay attention to issues such as data privacy and security to ensure that user privacy and data security are protected while enjoying the conveniences brought by technology.
The water consumption of AI systems is often overlooked. The operational process involves both onsite and offsite water consumption. Onsite water refers to the water used within the operational scope of facilities, such as data centers, which require substantial water for cooling through mechanisms like cooling towers or external air intake. In contrast, offsite consumption encompasses water utilization in power production, including cooling systems in power plants and water evaporation during hydropower processes. Moreover, the supply chain of AI technology also involves implicit water consumption, which is particularly evident in microchip production, as microchip manufacturing requires a large amount of ultra-pure water (UPW). Large language models also contribute to freshwater consumption during the training phase and query execution. Similarly, the operation of transformers will also require more water.
Water footprint can be calculated using the formula (WaterFootprint = ServerEnergy x WUE(Onsite) + ServerEnergy x PUE x WUE(Offsite)). Here, the onsite water use efficiency (WUE) quantifies the efficiency of water use in cooling systems. Power usage effectiveness (PUE) assesses the energy overhead beyond IT operations, including cooling energy consumption and power distribution losses. Additionally, the offsite WUE, also known as the power-water intensity factor, is used to evaluate the efficiency of water use during power production (Ren, 2024).
7. Discussion
Currently, most products on the market are limited to generating short videos (about 4 seconds), while Sora is capable of producing 60-second videos, setting a new benchmark in the industry. People often feel uneasy about overly realistic humanoid robots (Mori, MacDorman & Kageki, 2012) and virtual characters (Altundas & Karaarslan, 2023), a phenomenon known as the “uncanny valley.” Most videos do not contain realistic human content, and some professionals have evaluated them as exemplars of the “uncanny valley” phenomenon. However, Sora demonstrates extraordinary clarity, smooth motion, and an astonishing restoration of human anatomy and physical properties of the real world.
Nevertheless, Sora will also face fierce competition from various products, including startups like Runway Gen-2, Pika Labs, Stability AI, and Google’s Lumiere. Improvements in these technologies pose a threat to stock video agencies, potentially rendering traditional stock assets obsolete. Text-to-video AI technology has the potential to revolutionize multiple creative fields, including film production, advertising, graphic design, and game development, as well as industries such as social media, influencer marketing, and educational technology (Lohchab H. & Rekhi D., 2024).
As technology continues to advance and competition in the market increases, we look forward to more innovative products like Sora emerging, which will not only drive the development of AI video generation technology but also have a profound impact on multiple industries. At the same time, we need to pay attention to the ethical and social issues that these technologies may bring, ensuring that their development aligns with the needs and values of human society.
In the field of text-to-video artificial intelligence, many challenges remain unresolved. Among them, intellectual property protection is crucial, and systems must maintain transparency regarding the resources used for model training. However, companies like OpenAI are not truly “open” and often reluctant to disclose their resource lists. OpenAI’s Sora is likely trained using video content from stock video repositories, from which content creators on these sites will not gain any potential benefits from this product.
In the “uncanny valley” phenomenon of GANs (generative adversarial networks), an interesting research question is: “How does the perceived trustworthiness of content generated based on GANs change?” (Carnevale, Delgado & Bisconti, 2023). Synthetic generated content may be used for political or other improper purposes. Trust involves multiple criteria, including authenticity, objectivity, source credibility, vividness, perceived significance, information credibility, and overall persuasiveness. Additionally, investigating the psychological dimensions of human-computer interaction within these systems is also crucial (Carnevale, Delgado & Bisconti, 2023). We need to design blockchain solutions or similar technologies to achieve trust and traceability.
As technology continues to evolve and application scenarios expand, we must comprehensively consider the social impacts and ethical responsibilities of technology. While ensuring technological innovation, protecting creators’ rights, promoting transparency, and establishing trust mechanisms are key to the sustainable development of the text-to-video artificial intelligence field. Through in-depth research and technological innovation, we hope to overcome these challenges and open up broader prospects for the application of text-to-video AI.
Concerns have arisen regarding potential misuse of such systems to generate deepfake videos and inappropriate content. Some of this content may be deceptive, harmful, or offensive. Therefore, filters must be carefully configured, especially for political or sexual content, to safeguard human rights. Content filtering will help generate videos according to ethical and legal standards. Additionally, these videos should be watermarked for traceability of their sources. OpenAI and many companies are using content provenance and authenticity (C2PA – https://c2pa.org/) standards to watermark synthetic generated images. However, as of the writing of this article, C2PA has not yet been applied to videos.
As technology continues to evolve, we must remain vigilant about potential risks and take appropriate measures to ensure the safe and legal use of technology. For the generation of deepfake videos and inappropriate content, in addition to strengthening technical filtering and watermarking, we also need to enhance the formulation and enforcement of laws and regulations to combat misuse. At the same time, raising public awareness of these risks and educating them on how to identify and prevent false content is also crucial.
Furthermore, future considerations may involve extending standards like C2PA to the video domain to better track and verify the authenticity and provenance of synthetic videos. By comprehensively applying technological and legal means, we can better balance technological innovation with social responsibility, ensuring the healthy development of text-to-video AI technology.
The computational and environmental costs required for training models, as well as the computational expenses incurred in executing any text-to-video commands, have not yet been disclosed and require further investigation. Throughout the lifecycle of AI systems, from design and development to deployment and ongoing maintenance, integrating energy-saving measures is crucial. This can be achieved by adopting optimized algorithms designed to minimize computational demands and utilizing energy-efficient hardware architectures, such as low-power processors and dedicated AI accelerators. Additionally, techniques such as model pruning, quantization, and distillation help reduce the computational complexity of AI models, thereby lowering energy consumption. Dynamic resource allocation strategies, which adjust computational resources based on demand fluctuations, also contribute to energy-saving efforts. Utilizing edge computing infrastructure can execute AI tasks near data sources, reducing the energy required for data transmission and centralized processing.
Moreover, improving data center efficiency, including enhancing cooling systems, power management practices, and integrating renewable energy, is expected to reduce overall energy consumption. We must broaden the scope of discussion to include not only energy footprints but also water footprints, emphasizing the importance of developing environmentally sustainable solutions. Therefore, data centers should establish comprehensive strategies aimed at improving water efficiency, adopting sustainable water resource acquisition methods, implementing community-based water resource reuse programs, and actively participating in water resource replenishment efforts to create a net positive impact on water resources.
At the same time, as AI technology becomes widespread, we also need to pay attention to its social, cultural, and ethical impacts. This includes ensuring the fairness and transparency of AI technology, avoiding biases and discrimination, and promoting harmonious coexistence between humans and AI. Therefore, we need to strengthen interdisciplinary research and collaboration, including technology experts, ethicists, policymakers, etc., to jointly formulate and implement relevant norms and standards. Additionally, enhancing public understanding and awareness of artificial intelligence technology and improving public scientific literacy is also a crucial part of ensuring the healthy development of artificial intelligence.