“Academic Window” is a paper recommendation column launched by the Academic Research Department of the Graduate Affairs Center of the School of Computer Science and Technology, aimed at recommending and sharing the latest academic achievements and classic papers in various fields of computer science to students. In the future, it will be pushed on this public account, and all students are welcome to follow.
Feature extraction is the foundation of computer vision tasks. A good feature extraction network can significantly enhance the performance of algorithms. In computer vision tasks, the network used for feature extraction from images is referred to as a Backbone, which is the backbone of downstream tasks in computer vision (classification, segmentation, detection, etc.).
This paper recommendation compiles six articles based on CNN and Transformer, all of which propose neural network models that are classics in the field of computer vision and are well worth studying and referencing for students engaged in this direction.
1
VGG
“Very Deep Convolutional Networks
for Large-Scale Image Recognition”
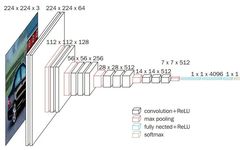
VGG was proposed by the Visual Geometry Group at the University of Oxford. This work studied the impact of the depth of convolutional networks on their accuracy in large-scale image recognition settings. The VGG network won the runner-up in the classification task and the championship in the localization task at the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC14). VGG can be seen as a deeper version of AlexNet, with one improvement being the use of several consecutive 3×3 convolution kernels instead of the larger convolution kernels used in AlexNet. For a given receptive field, stacking small convolution kernels is superior to using large convolution kernels because multiple layers of non-linear layers can increase network depth to ensure learning of more complex patterns, and the cost is relatively low. The structure of VGG is also very simple, mainly consisting of 3×3 convolution layers, 2×2 max pooling layers, and fully connected layers, making it a very easy-to-use neural network model.
Link: https://arxiv.org/abs/1409.1556
2
GoogLeNet
“Going Deeper with Convolutions”
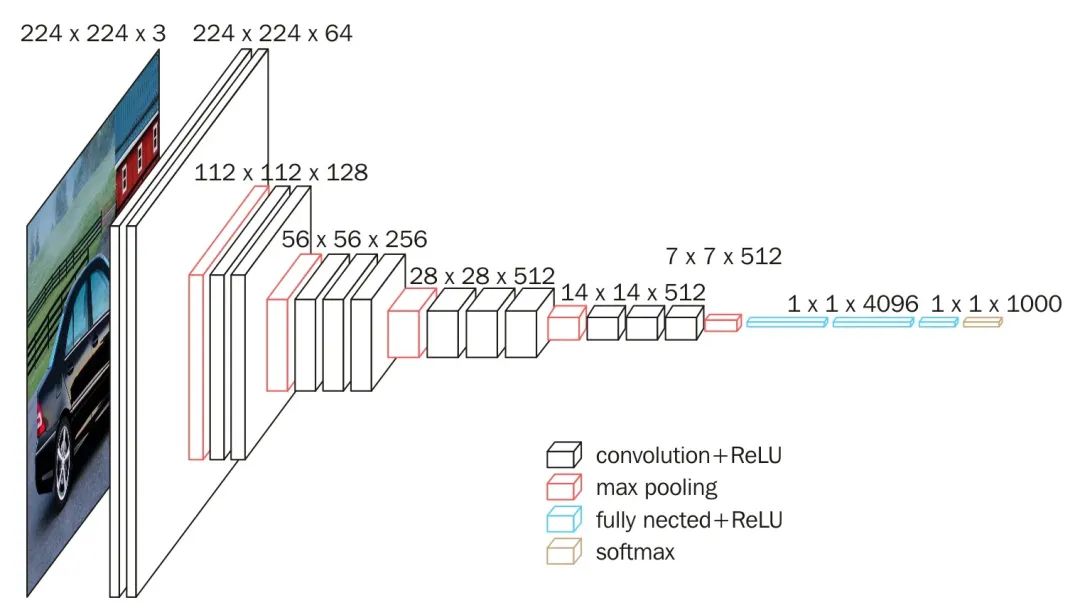
GoogLeNet is a deep neural network model proposed by the Google team in 2014, winning the championship in the classification task at that year’s ImageNet Large Scale Visual Recognition Challenge (ILSVRC14). The biggest highlight of this network is its use of a deep and wide network structure, proposing a multi-scale convolution parallel module named Inception, as shown in the figure below. By using convolution kernels of different sizes (1×1, 3×3, 5×5), it can extract features of different scales from images and fuse these features together. As the scale of the network increases, it inevitably brings about the consumption of computational resources and issues like overfitting. In the Inception module, a 1×1 convolution kernel precedes each scale’s convolution to reduce dimensionality, allowing the network to deepen and widen while keeping computational resource budgets unchanged.
Link: https://arxiv.org/abs/1409.4842
3
ResNet
“Deep Residual Learning for Image Recognition”
ResNet was proposed by Microsoft Research Asia in 2015, winning the championship in both the classification and localization tasks at that year’s ImageNet Large Scale Visual Recognition Challenge (ILSVRC15) as well as the COCO object detection and segmentation tasks.
In general perception, the more convolutional and pooling layers a neural network has, the more feature information it can obtain from images, theoretically leading to better performance. However, actual experiments have shown otherwise. With the continuous stacking of convolutional and pooling layers, no better learning results were achieved. The main reasons for this are the occurrence of gradient vanishing, gradient explosion, and degradation of the neural network.
To solve the issues of gradient vanishing and explosion, ResNet uses Batch Normalization to normalize data features.
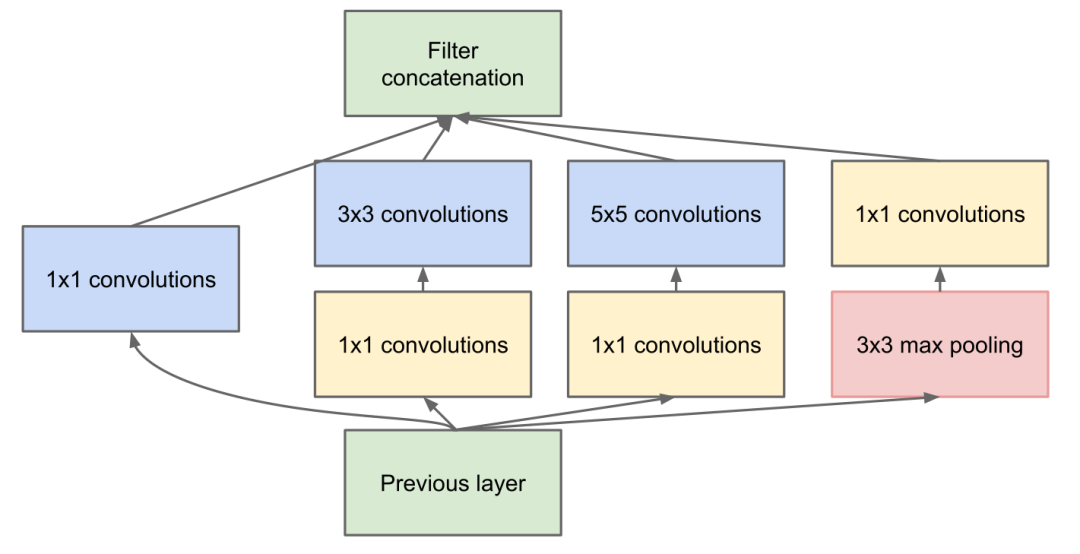
To address the degradation problem of neural networks, ResNet employs a residual structure, which is a shortcut connection method that allows certain layers of the neural network to skip connections to the next layer’s neurons, connecting across layers and weakening the strong connections between each layer, also understood as a shortcut, as shown in the figure below. This residual structure enables the neural network to perform better as the number of layers increases. Although ResNet has been around for seven years, it remains one of the most popular backbone networks today.
Link: https://arxiv.org/abs/1512.03385
4
Vision Transformer
“AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
In 2020, the Google team applied their model used for natural language processing—Transformer—directly to the field of computer vision, proposing the Vision Transformer (ViT). This work demonstrated that the dependence on convolutional neural networks in the visual domain is unnecessary, and that a pure transformer applied directly to image patch sequences can perform well in image classification tasks. ViT achieved excellent results compared to the state-of-the-art convolutional networks at that time. ViT is also a milestone in the cross-domain integration of natural language processing and computer vision.
The Transformer is a sequence-to-sequence model. ViT encodes images into sequences by dividing them into 16×16 patches, passing each patch through a linear layer while embedding positional information and introducing a classification token. The generated sequence is then input into the standard transformer encoder, and the output sequence head gives us the desired classification result.
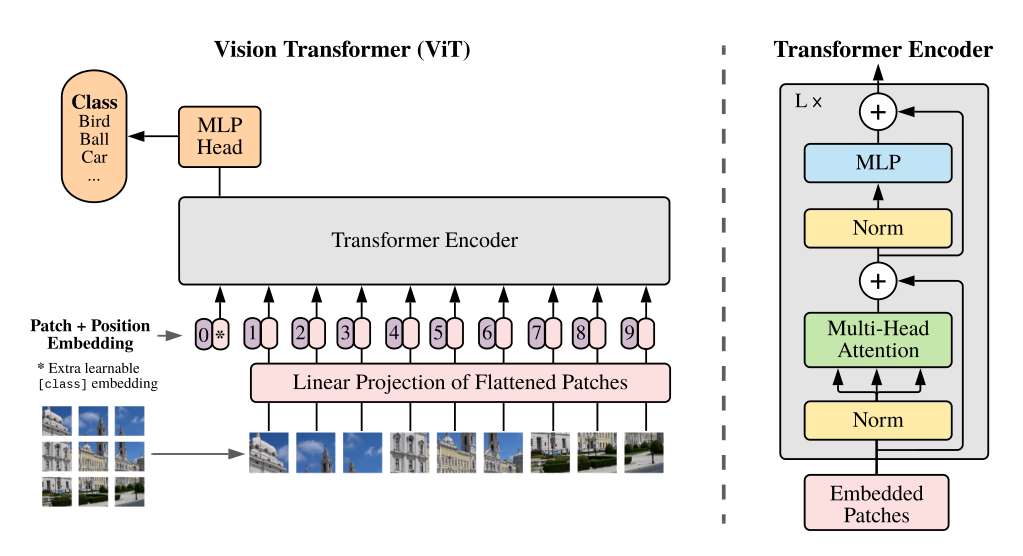
Paper link: (Transformer “Attention Is All You Need”) https://arxiv.org/abs/1706.03762
Paper link: (Vision Transformer) https://arxiv.org/abs/2010.11929
Code link: https://github.com/google-research/vision_transformer
5
Swin Transformer
“Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”
Directly applying the Transformer to the visual domain presents two main challenges: first, the variations of visual entities are significant, and ViT may not demonstrate excellent performance across different scenes; second, the high resolution of images means that the global attention mechanism of the Transformer can lead to significant computational demands, with the computational load increasing quadratically as image size increases. To address these issues, Microsoft Research Asia proposed the Swin Transformer, which features a hierarchical structure and a shifted window mechanism. The sliding window approach limits self-attention calculations to non-overlapping local windows while allowing cross-window connections, thus improving efficiency. This hierarchical structure provides flexibility in modeling at different scales and has linear computational complexity concerning image size.
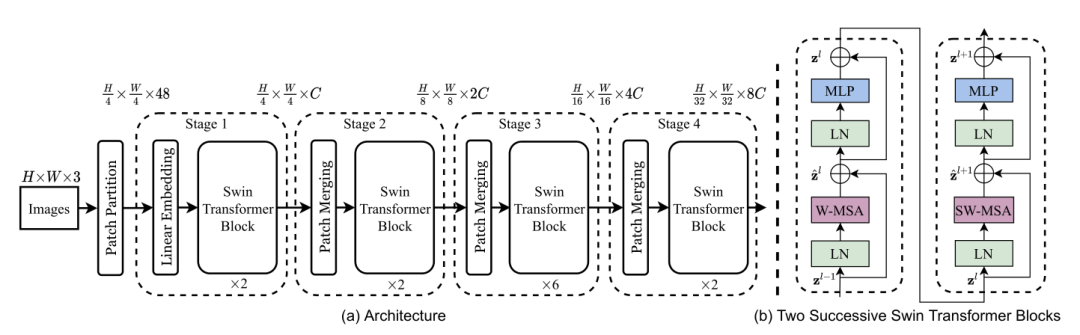
The Swin Transformer divides images into fixed-size windows, then patches the images within the windows, and applies attention mechanism calculations between the patched windows, ensuring that the attention’s time complexity increases linearly with image size. Additionally, the sliding window mechanism allows for information exchange between adjacent windows.
Paper link: https://arxiv.org/abs/2103.14030
Code link: https://github.com/microsoft/Swin-Transformer
6
ConvNeXt
“A ConvNet for the 2020s”
In recent years, with the rise of transformer models in the image domain, transformer-based models have gradually surpassed CNN models in various fields of computer vision. Against this backdrop, Facebook AI Research and the University of California, Berkeley proposed a convolutional neural network for the 2020s—ConvNeXt. ConvNeXt is based on ResNet and makes the following adjustments to the structure of residual convolution blocks, referring to Swin Transformer: (1) using a 7×7 large convolution kernel; (2) replacing the ReLU activation function with GELU; changing Batch Normalization to Layer Normalization; (3) adopting a hierarchical network structure and the same number of feature channels as Swin Transformer; (4) using an inverted bottleneck design for the residual convolution block. This network has surpassed the Swin Transformer model in multiple classification and recognition tasks, achieving optimal performance. The emergence of ConvNeXt undoubtedly confirms that CNNs still have strong competitiveness in the field of computer vision.
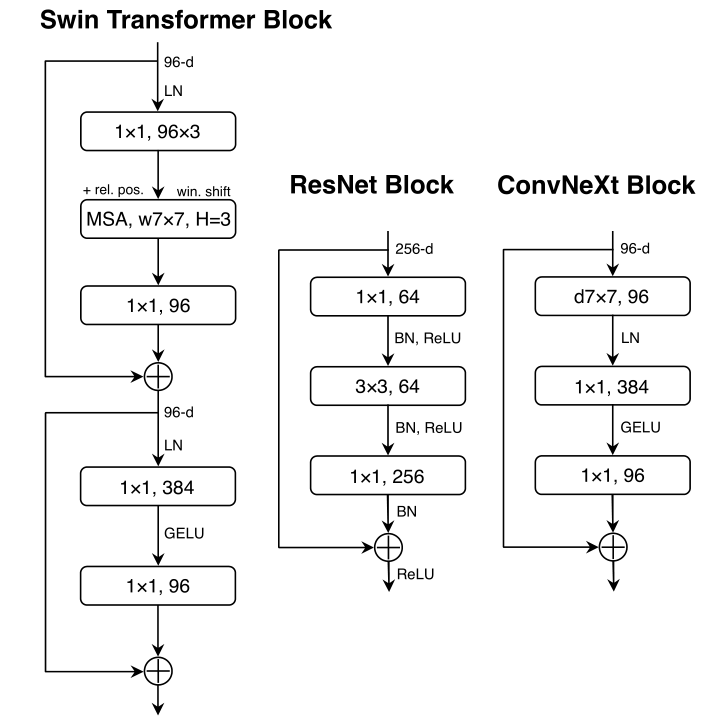
Paper link: https://arxiv.org/abs/2201.03545
Code link: https://github.com/facebookresearch/ConvNeXt

Image and text by Shi Zhebin
Editor: Li Saiwei
Review: Wang Shiting