Follow the public account “ML_NLP“
Set as “Starred” to receive valuable content promptly!

Reprinted from | Smarter
Recently, a new paradigm of Prompt has been proposed in the NLP field, aiming to revolutionize the original Fine-tuning method. In the CV field, Prompt can actually be understood as the design of image labels. From this perspective, Prompt (predicting the masked characters in text, similar to cloze tests) is a task that lies between Image Captioning (iteratively predicting each character) and one-hot labels (which can be seen as a special case of prompt, where a single character is transformed into one-hot through a text encoder). Recently, prompts have begun to demonstrate powerful capabilities in Visual-Language Model (VLM) tasks.
This article first introduces the essential differences between prompt and fine-tuning paradigms, then discusses the PET and AutoPrompt methods based on prompts in NLP, and finally introduces the CLIP and CoOp methods that apply the prompt paradigm in VLM tasks.
Additionally, both CLIP and CoOp are discriminative VLM methods based on prompts. Recently, there have been several generative VLM methods based on prompts. The generative VLM based on prompts is very similar to the NLP methods based on prompts, and this article will not elaborate further, but will provide the article links.
Unifying Vision-and-Language Tasks via Text Generation:
https://arxiv.org/abs/2102.02779v1
Multimodal Few-Shot Learning with Frozen Language Models:
https://arxiv.org/abs/2106.13884
(Citing Liu Pengfei’s original words: https://zhuanlan.zhihu.com/p/395115779)
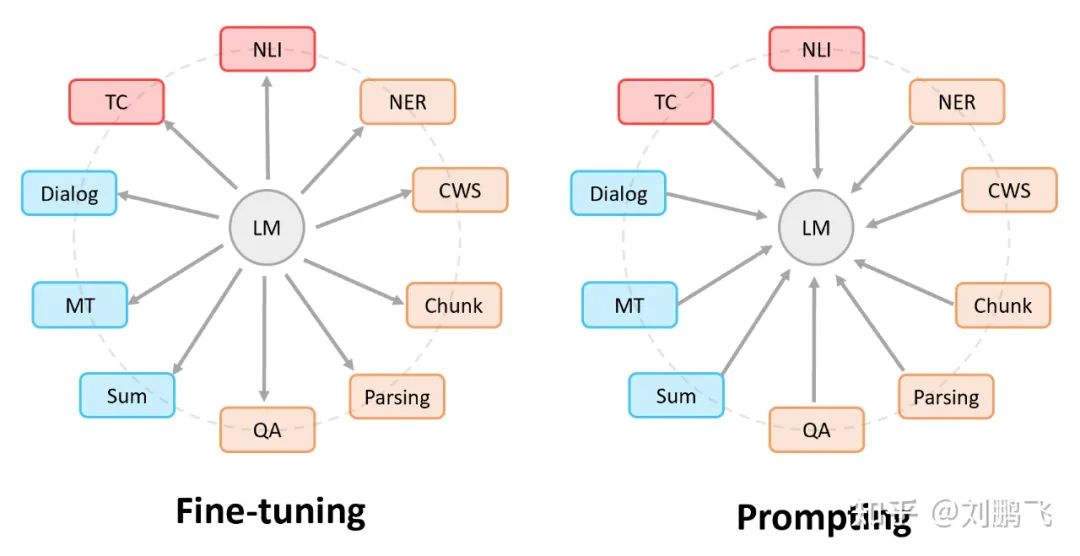
In the figure, the circles represent pre-trained language models, and the rectangles represent various downstream NLP tasks. Thus, we can say: everyone hopes to bring pre-trained language models closer to downstream tasks, but the methods to achieve this differ.
In Fine-tuning: the pre-trained language model “concedes” to various downstream tasks. This is specifically reflected in the introduction of various auxiliary task losses, which are added to the pre-trained model and then continue pre-training to better adapt to downstream tasks. In summary, during this process, the pre-trained language model makes more sacrifices.
In Prompting: various downstream tasks “concede” to the pre-trained language model. This is specifically reflected in the need to reconstruct different tasks to achieve compatibility with the pre-trained language model. In summary, during this process, downstream tasks make more sacrifices.
Next, I will talk about two preliminary works in NLP: PET and AutoPrompt, which have significant implications for Visual-Language Model tasks.
PET is the first method to apply prompt-trained language models to downstream tasks and standardizes the prompt paradigm, providing a demonstration for subsequent research on the prompt paradigm.
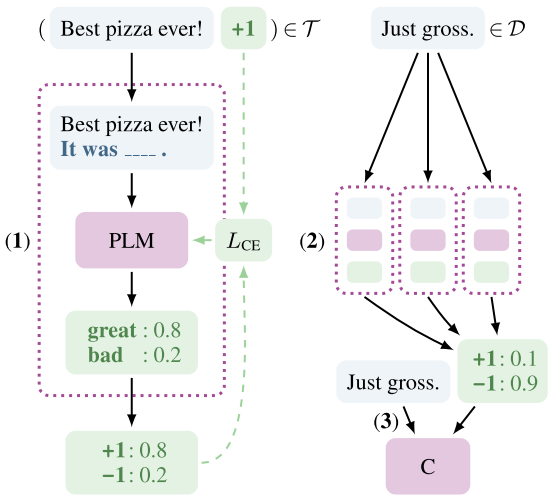
The design process of PET is as follows:
1. Pre-set multiple prompts, which include the text to be predicted (for example, in the image above, Best pizza ever! It was ___. where “It was” is the pre-set prompt that can be replaced with other prompts), and then input multiple prompts into different PLM models for training, ultimately obtaining multiple PET models.
2. Input the text to be predicted into multiple PET models for inference, and combine the results of multiple PET models to obtain soft labels.
3. Input the text to be predicted and soft labels into a classifier for training, resulting in the final text classification model.
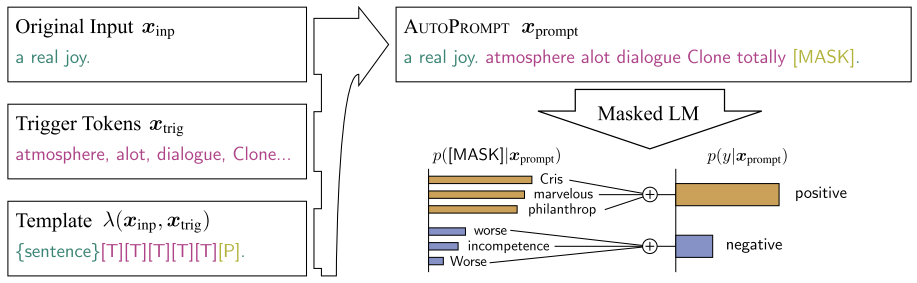
The prompts constructed by PET are manually designed, which may lead to unreasonable prompts. AutoPrompt proposes to automatically learn Trigger Tokens [T] [T] [T] [T] [T] during the prompt construction process. The optimization goal is to add appropriate tokens so that the predicted results increasingly lean towards the correct outcome (for example, in the image above, when the tokens are atmosphere, a lot, dialogue, clone, totally, the probability of being positive increases).
OpenAI collected 400 million image-text pairs from the internet for CLIP training, and achieved excellent results in zero-shot transfer to downstream tasks (for more on zero-shot learning, see my previous article ViLD: A Zero-Shot Detector Beyond Supervised).
Let’s briefly review the usage process of CLIP:
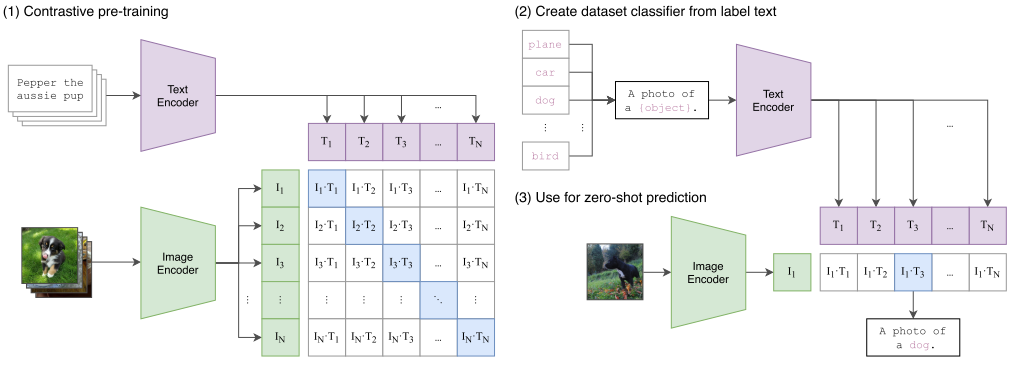
1. As shown in figure (1), CLIP encodes a batch of text into word embeddings through the Text Encoder, encodes a batch of images (corresponding to the text) into feature embeddings through the Image Encoder, and then normalizes the corresponding word embeddings and feature embeddings and performs dot product to obtain the similarity matrix. The larger the dot product value, the more similar the word embedding and feature embedding vectors are. The supervisory signal here is that the diagonal of the matrix is 1, and the other positions are 0. The Text Encoder uses Transformer, while the Image Encoder uses either ResNet50 or ViT architecture, both trained from scratch.
2. Then, the pre-trained CLIP is transferred to downstream tasks, as shown in figure (2). First, the labels of the downstream tasks are constructed into a batch of labeled texts (for example, A photo of a {plane}), which are then encoded into corresponding word embeddings through the Text Encoder.
3. Finally, perform zero-shot prediction on unseen images, as shown in figure (3). The image of a dog is encoded into a feature embedding through the Image Encoder, which is then normalized and dot-multiplied with the batch of word embeddings encoded in (2), and the position with the maximum value in the resulting logits corresponds to the final predicted label.
From the process of CLIP, it can be seen that the usage of prompts in CLIP and PET is very similar, where “A photo of a” is a manually designed prompt.
CoOp is clearly inspired by AutoPrompt and has discovered that CLIP is actually an application of prompts in visual-language models. Therefore, CoOp further improves upon CLIP.
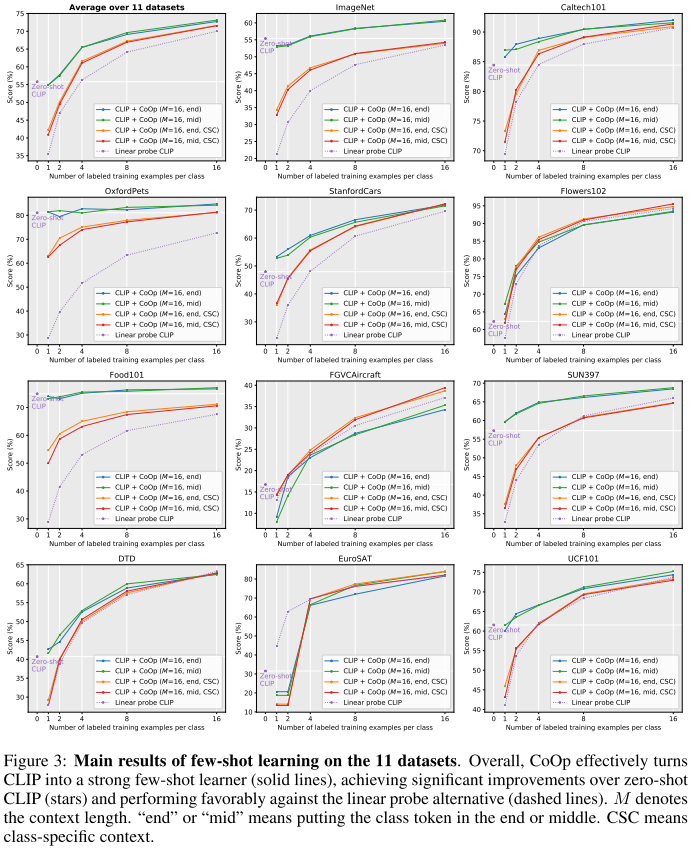
CoOp first experiments on four datasets and finds that more reasonable prompts can significantly improve classification accuracy, especially after using the CoOp proposed in this article, the final classification accuracy far exceeds the manually designed prompts of CLIP.
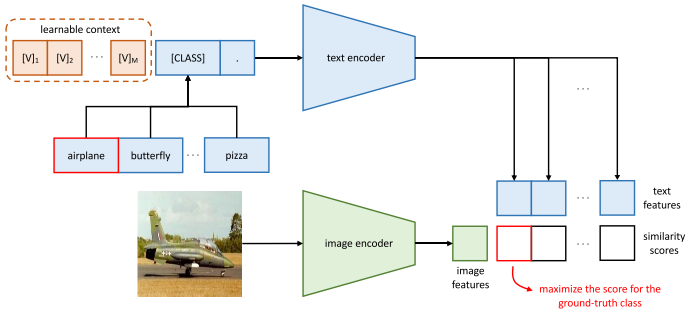
The main difference from CLIP is that CoOp introduces context optimization in the second stage of CLIP. Specifically, CoOp designs the prompt as:
where each vector has the same dimension as the word embedding and can be understood as a learnable context, and all categories share parameters corresponding to the context.
The learnable context is concatenated with the word embeddings of different categories and sent into the text encoder for training, with the optimization goal being to maximize the prediction score of the prompt corresponding to the image. After training, the parameters of the learnable context are fixed.
The authors also tried two variants:
One is that prompts can insert learnable contexts both before and after the class to increase the flexibility of the prompts.
The other is to design class-specific contexts (CSC), where the prompt parameters for all categories are independent, which performs better in some fine-grained classification tasks.
From the experiments on 11 datasets, it can be seen that CoOp surpasses CLIP in all cases, and in some datasets, it significantly exceeds CLIP. This proves that learnable prompts are superior to manually designed prompts. The two variants proposed by CoOp perform better on some datasets.
CoOp vs Prompt Ensembling
Comparing CoOp with the Prompt ensembling proposed in PET, CoOp also demonstrates superiority.
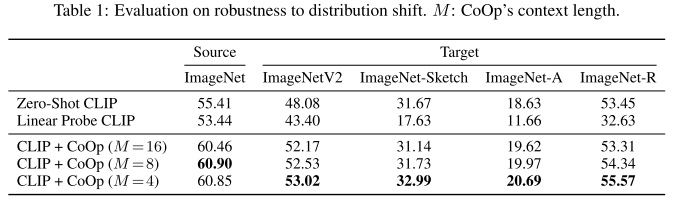
From the above experiments, it can be seen that CoOp has better robustness to noise than CLIP.
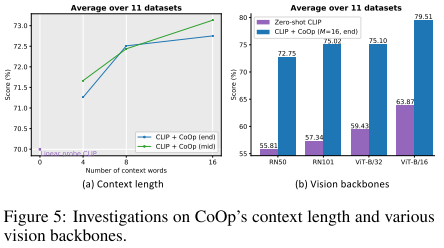
From the above experiments, it can be seen that the longer the context length, the better the CoOp performs; the larger the backbone model, the better the CoOp performs.
Random vs. Manual Initialization
This comparative experiment is quite insightful, indicating that the initialization of learnable context prompts is not that important; random initialization can achieve accuracy comparable to fine-tuned initialization.
Because CoOp is class-level adaptive, it cannot dynamically adjust prompts based on different input images. If it could dynamically adjust prompts based on input images, achieving instance-level adaptation, it might yield remarkable results. The role of learnable context is similar to denoising, allowing the network to fit noise, making the focus area of the prediction cleaner. It feels that learnable context and the object query in ViT serve very similar functions, both learning information arbitrarily and updating parameters solely based on the final supervisory signal. Future exploration can focus on how to control the learning of learnable context to enhance the performance of prompt-based VLMs. The generative VLM can also explore how to design prompts more reasonably.
Additionally, pure CV direction prompts, similar to how ViT splits images into patches (where each patch can be regarded as a character), can also design patch prompts for model training. This can be divided into generative (similar to ViT) and discriminative (similar to self-supervised) methods.
Recommended Reading:
H.T. Kung's Useful Research Suggestions
What is Transformer Positional Encoding?
17 Implementations of Attention Mechanism in PyTorch, including MLP, Re-Parameter series of popular papers
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: