
Follow our public account to discover the beauty of CV technology

This article shares the AAAI 2024 paper FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning, detailing the use of diffusion models for generating complex characters in any style.
Detailed information is as follows:

-
Authors: Yang Zhenhua, Peng Dezhi. -
Affiliation: South China University of Technology DLVC Laboratory, Alibaba Paper Link: https://arxiv.org/abs/2312.12142 -
Project Link: https://yeungchenwa.github.io/fontdiffuser-homepage/ -
HuggingFace Demo Link: https://huggingface.co/spaces/yeungchenwa/FontDiffuser-Gradio


Article Summary
Font generation is an imitation task aimed at creating a font library that mimics the style of reference images (style images) while preserving the content of source images (content images), as shown in Figure 3. Although existing methods have achieved satisfactory performance, they still struggle with complex characters and characters with significant style variations.
To address these issues, we propose a diffusion-based Image-to-Image font generation method called “FontDiffuser,” which innovatively models the font imitation task as a noise-to-noise paradigm. In our method, we introduce a Multi-Scale Content Aggregation (MCA) module that effectively combines global and local content cues at different scales, enhancing the retention of complex strokes in intricate characters.
Furthermore, to better handle style transformations with significant differences, we propose a Style Contrastive Refinement (SCR) module, a novel style representation contrastive learning strategy that separates style from images using a style extractor and supervises the diffusion model through a carefully designed style contrastive loss.
Extensive experiments demonstrate that FontDiffuser achieves state-of-the-art performance in generating diverse characters and styles, consistently excelling in complex characters and large style variations compared to previous methods.
Research Motivation

Existing Issues
Current font generation methods, while achieving satisfactory performance, still face severe issues such as stroke missing, artifacts, blurriness, structural layout errors, and style inconsistency when dealing with complex characters and characters with large style variations (especially Chinese characters), as shown in Figure 4.
Cause Analysis
-
Most methods adopt a GAN-based framework, which may encounter training instability due to its adversarial training nature. -
These methods mostly perceive content information through high-dimensional features at a single scale, neglecting the fine-grained details needed to retain source content (especially complex characters). -
Many methods use prior knowledge to assist in font generation, such as stroke or component composition of characters; however, acquiring these fine-grained details can be costly for complex characters. -
In past methods, the target style is often learned through a simple classifier or discriminator for feature representation, making it challenging to learn suitable styles, which hinders style transformation when significant variations occur.
Adopted Strategies
-
We propose a diffusion-based Image-to-Image font generation method named FontDiffuser, which models font generation learning as a noise-to-denoise paradigm capable of generating unseen characters and styles. -
(1) We introduce a Multi-Scale Content Aggregation (MCA) module that utilizes global and local content features at different scales. -
(2) We introduce a novel style representation contrastive learning strategy that enhances the generator’s ability to imitate styles through the Style Contrastive Refinement (SCR) module.
FontDiffuser Model Framework
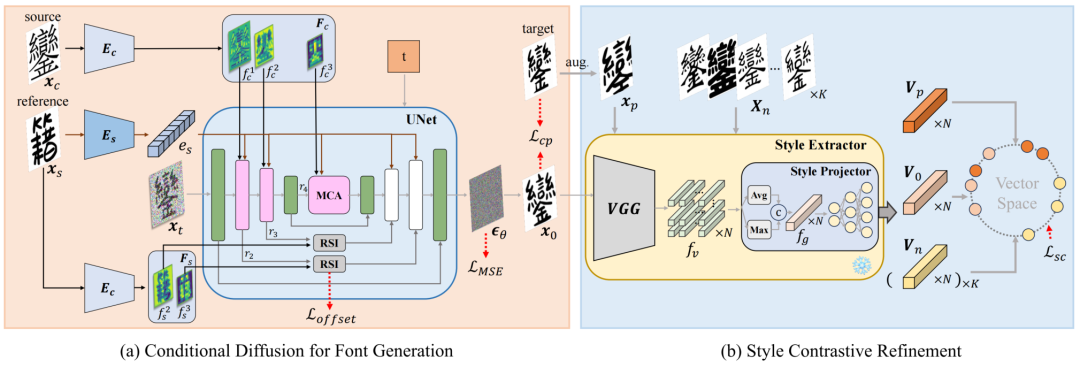
FontDiffuser model framework is shown in Figure 5, which includes conditional diffusion font generation model and style refinement contrast module. In the conditional diffusion font generation model part, our goal is that, given a source image (content image) and a reference image (style image), the model’s output should match the character content of the source image while maintaining consistency with the style of the reference image; in the style refinement contrast learning module, the main goal is to separate and identify the styles from a set of images during training, ultimately providing supervision information for the conditional diffusion model through the style contrast loss function.
Conditional Diffusion Font Generation Model
Our conditional diffusion model predicts noise, representing both the source image (content image) and the reference image (style image). Specifically, to enhance the retention of details for complex characters, we designed the Multi-Scale Content Aggregation (MCA) module, injecting global and local content cues into the model’s UNet; we also designed a Reference-Structure Interaction (RSI) module to facilitate structural deformation from the reference image (style image).
-
Multi-Scale Content Aggregation (MCA) Module
Generating complex characters has always been a challenging task; many existing methods rely solely on single-scale content features, neglecting complex details such as strokes and radicals. As shown in Figure 6, large-scale features retain significant detail information, while small-scale features lack this information.
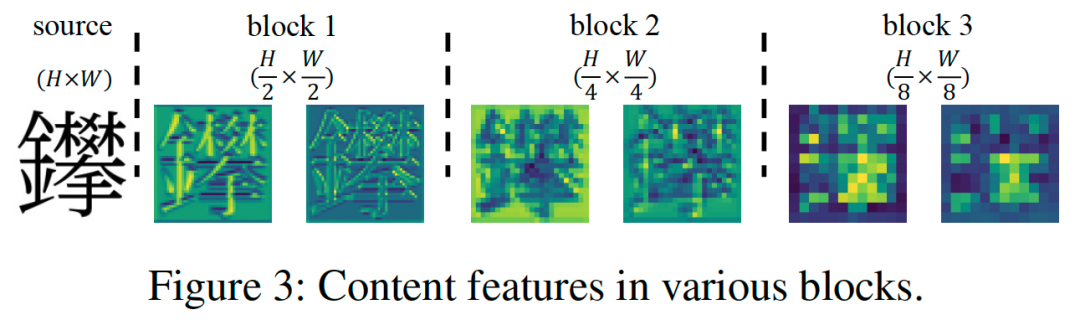
Thus, we designed the Multi-Scale Content Aggregation (MCA) module to inject global and local content features at different scales into the diffusion model’s UNet, as shown in Figure 7. This includes a channel attention mechanism to improve adaptive channel selection capabilities and a Cross-Attention to introduce style features.
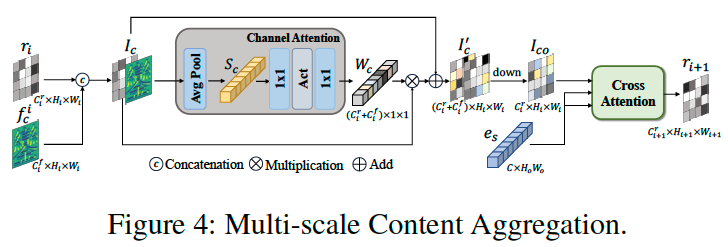
-
Reference-Structure Interaction (RSI) Module
There are structural differences between the source image (content image) and the target image (such as font size). To address this issue, we propose the Reference-Structure (RSI) interaction module, which uses Deformable Convolutional Networks (DCN) to perform structural deformation on the skip-connection parts of the UNet. The specific process can be expressed using the following formula.
Style Refinement Contrast Learning Module
Regardless of the style differences between the source image (content image) and the reference image (style image), one of the goals of font generation is to achieve the desired style imitation effect. One feasible solution is to find suitable style feature representations and further provide supervision information for our generator. Therefore, we propose the Style Contrastive Refinement (SCR) module, which is a font style representation learning module that can separate styles from a set of sample images and supervise our conditional diffusion model using style contrast loss, ensuring that the generated styles are consistent with the targets at both global and local levels, as shown in Figure 5(b) and expressed in the formula below.
Training Loss Function
Our training adopts a two-phase strategy from coarse to fine, specifically including:
-
Phase 1
We primarily use standard MSE diffusion loss to optimize FontDiffuser without using the SCR module. This ensures that our generator possesses the basic ability to reconstruct fonts:
Where,
represents the total loss for Phase 1. is the VGG encoded layer features, and is the selected layer number. is used to penalize the content misalignment between the generated VGG features and the corresponding target features. The offset loss is used to restrict the offset in the RSI module.
More Visualization Results
More Visualization Results

Medium Difficulty Characters

Easy Difficulty Characters

Cross-Language Generation (Chinese to Korean)

Experiments
To validate the effectiveness of generating characters of varying complexity, we categorized Chinese characters based on the number of strokes into three complexity levels (easy, medium, hard) and tested our method on each level. Sample Chinese characters of different complexities are shown below:

Quantitative Results
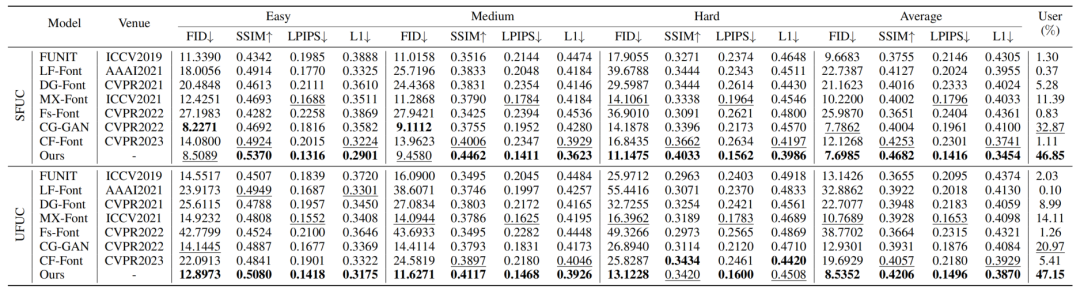
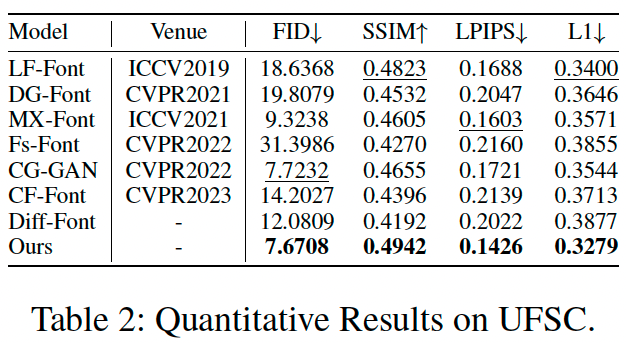
Qualitative Results
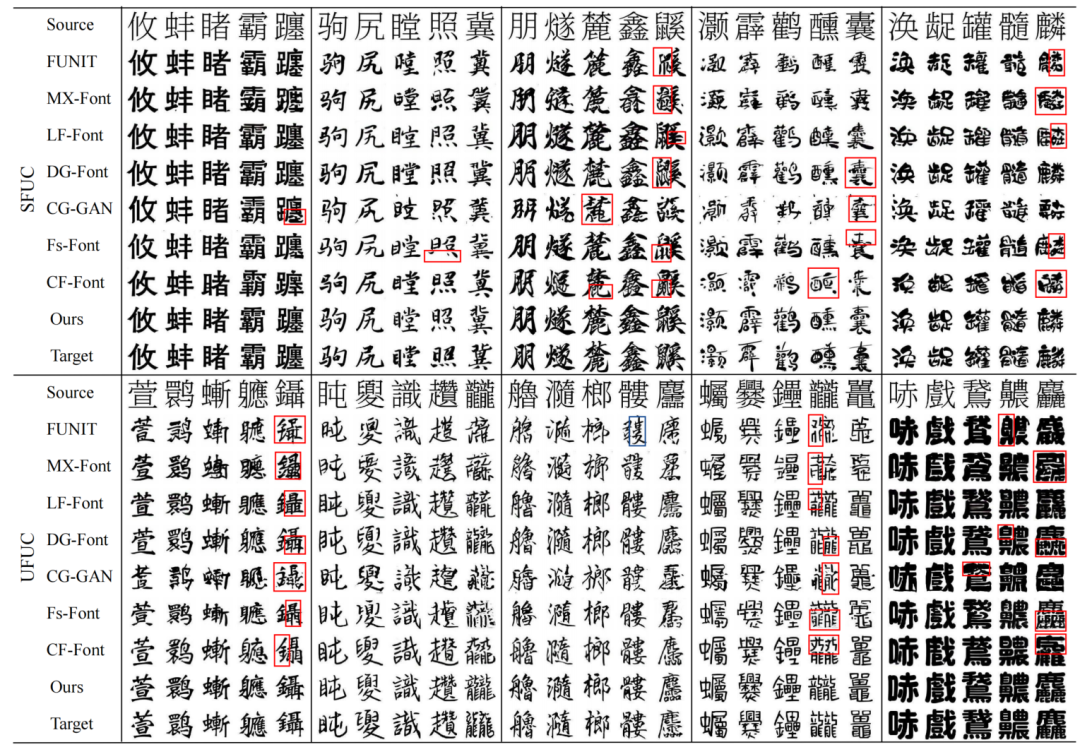
Cross-Language Generation (Chinese to Korean)
FontDiffuser can also generate Korean characters with only a Chinese dataset for training, as shown in Figure 11 below:

Conclusion Analysis
Our method outperforms existing methods on characters of varying complexity levels, demonstrating FontDiffuser’s applicability in cross-language font generation tasks (such as Chinese to Korean), highlighting its strong cross-domain capabilities.
Ablation Study
-
Effectiveness of Different Modules
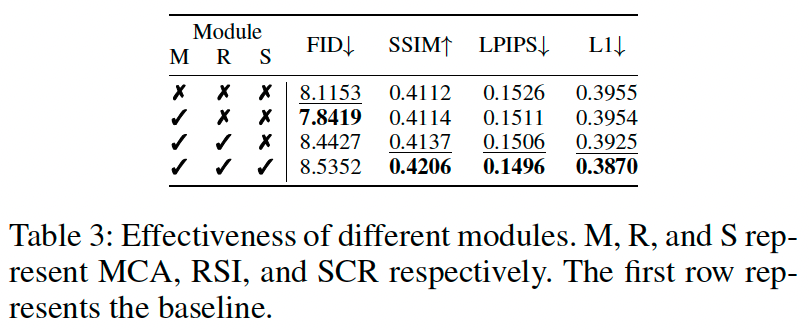

-
Effectiveness of Data Augmentation in SCR Module
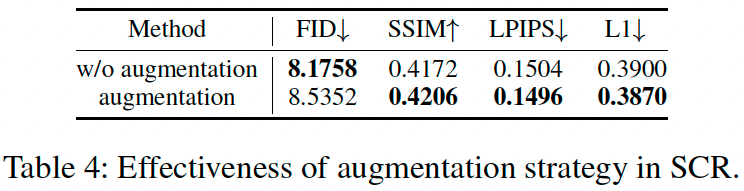
-
Performance Comparison of Interaction Methods Based on Cross-Attention and CNN in RSI Module

Summary
In this article, we propose a diffusion-based Image-to-Image font generation method called FontDiffuser, which excels in generating complex characters and handling significant style transformations.
Additionally, we introduced a novel style feature contrast learning strategy, proposing an SCR module that supervises our diffusion model using style contrast loss. Furthermore, we adopted the RSI module to utilize structural features from the reference image to facilitate structural deformation.
Extensive experiments demonstrate that FontDiffuser outperforms existing methods across three complexity levels of characters. Moreover, FontDiffuser has proven its applicability in cross-language font generation tasks (such as Chinese to Korean), highlighting its strong cross-domain capabilities.
Demo

END
