
In March of this year, Google’s AlphaGo emerged and defeated South Korean player Lee Sedol, causing a frenzy in the fields of deep learning and machine learning, not only in academia but also among the general public. Artificial intelligence has had its ups and downs, but currently, the hottest topic is deep learning, which was proposed by Geoffrey Hinton in 2006, involving multi-layer neural networks.
With the rapid development in recent years, the increasing layers of neural networks have raised high demands for training speed and power consumption, leading to a series of neural network accelerator chips. In the IP/DSP field, there are companies like ChipIntelli and TSMC; in the ASIC field, there are companies like Cambricon and Horizon Robotics; in the GPU field, NVIDIA still dominates; in the CPU field, Intel certainly leads; and there are also FPGA manufacturers like ALTERA and XILINX, which are most suitable for the variability of deep learning networks. With various deep learning network structures such as DBN, CNN, Pooling, LRN, and MLP, there are more requirements for accelerator setups, making variable FPGA-based accelerators more favored and widely recognized by designers.
At the end of last month, Xilinx released a white paper on deep learning based on fixed-point data, greatly facilitating designers in testing and designing deep learning based on FPGA. Below, we will analyze some of the contents of this white paper.
Generally speaking, in AI, machine learning, and deep learning fields, the higher the precision of the input data in deep learning networks, the higher the accuracy of the results. However, this measurement has yielded a counterintuitive conclusion: fixed-point data achieves a similarly high inference accuracy compared to floating-point data, significantly improving performance while reducing power consumption. The latest Xilinx white paper (https://www.xilinx.com/support/documentation/white_papers/wp486-deep-lea…) titled “Using INT8 Optimized Deep Learning on Xilinx Devices” elaborates on the relevant technical details.
Research shows that in deep learning networks, 32-bit floating-point input data is not the only way to achieve optimal accuracy. For many applications such as image classification, INT8 (or even lower precision) fixed-point calculations can provide the same accuracy as floating-point results. The table below from the Xilinx white paper presents the accuracy of fine-tuned CNN (Convolutional Neural Network) based on fixed-point calculations, supporting this claim. (The numbers in parentheses indicate the accuracy without fine-tuning.)
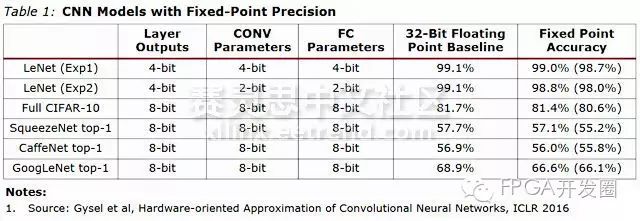
Table 1
From Table 1, it can be seen that in the six common CNN network structures analyzed, the accuracy of fixed-point calculations with reduced precision is comparable to that of 32-bit floating-point calculations. Traditionally advantageous 32-bit floating-point numbers consume more power and resources to implement, especially when creating large-scale parallel CNNs, where the situation is even more severe. Meanwhile, the application of 8-bit fixed-point data offers better performance, lower power consumption, and better resource utilization.
The first two advantages are straightforward, while the Xilinx white paper will detail the third point: better resource utilization efficiency. Research shows that FPGA-based floating-point DSP does not match ultra-large-scale applications, including machine learning. (Additionally, other studies indicate that using GPU optimization during CNN training is significantly more efficient than using FPGA-based floating-point DSP structures.)
Xilinx’s UltraScale and UltraScale+ FPGAs utilize the fixed-point DSP48E2 architecture, optimized for reduced precision integer calculations, employing 27×18 bit multipliers, 48-bit accumulators, and other enhanced architectures. They can perform two INT8 operations per clock cycle in each DSP48E2, a feature that competitors’ FPGA DSP blocks cannot achieve. (For more technical details on packing integer operands and doubling CNN performance, refer to the Xilinx white paper.)
As shown in the following figure, using Xilinx UltraScale and UltraScale+ FPGAs for CNN network training with integer fixed-point data achieves extremely high performance and efficiency.
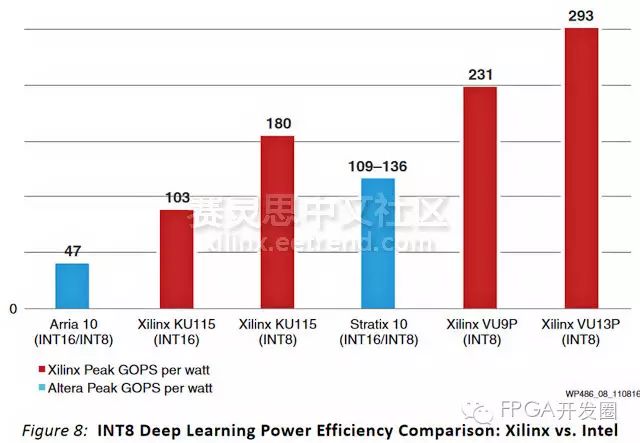
Figure 1
This figure shows that using Xilinx UltraScale and UltraScale+ FPGA fixed-point data for CNN networks can achieve higher GOPS/watt. Compared to Intel’s Arria 10 and Stratix 10 devices shown above, Xilinx devices can improve deep learning training efficiency by 2x to 6x (in units of GOPS/watt), while maintaining similar accuracy levels to 32-bit floating-point implementations.
For more information, please refer to the Xilinx Acceleration Zone Web page, which discusses various aspects of ultra-large-scale cloud acceleration using Xilinx FPGA technology, including the new Xilinx deep learning acceleration development kit based on the Xilinx Kintex UltraScale KU115 FPGA.
Deep learning has become a breakthrough window in the field of machine learning, and research and applications related to deep learning have garnered significant attention in both academia and the public. Therefore, providing convenient and suitable accelerator devices for designers has become particularly important. This time, Xilinx has developed a deep learning suite based on FPGA, which greatly enhances the efficiency and accuracy of deep learning training. It is believed that with the continuous promotion by companies like Xilinx, the implementation of artificial intelligence will become faster and more stable, making significant contributions to today’s IoT and intelligent era.
Technical Tutorial | Zybo Full-Stack Development Beginner’s Guide (Based on Linux Embedded System) Part 2
How to Better Understand and Analyze Deep Convolutional Neural Networks?
Everspin Launches NVMe Storage Accelerator Card ES1GB-N02
[Technical Tutorial] Zybo Full-Stack Development Beginner’s Guide (Based on Linux Embedded System) Part 1
New Breakthrough in I/O Throughput! FPGA Helps Achieve Fourfold Rate Increase
Weekly Cool Creation | Wearable Sports Device Made Based on Minimal FPGA System
Alpha Data Company Launches ADM-PCIE-9V3 Accelerator Card
7Series FPGA High-Speed Transceiver Learning—Overview and Reference Clock
Dry Goods Series | Basys3 FPGA Personal Learning Notes (Part 1)
The “Rising Star of Acceleration”: Xilinx Reconfigurable Acceleration Stack
At the Forefront: Xilinx SDx: Kevin Morris Analyzes the Development of FPGA Development Environments
EtherCAT Master Station Solution Implementation Based on Zynq Platform
[Video] Display of Ten Programmable IIoT Solutions
Preview of Xilinx’s Latest Industrial IoT Solutions at the 2016 SPS IPC Drives Electrical Automation Exhibition
Spectrum Launches M4x PXIe Arbitrary Waveform Generator Card Based on Xilinx FPGA
