
Follow our public account to discover the beauty of CV technology
This article introduces the latest 4D generation diffusion model proposed by teams from the University of Toronto, Beijing Jiaotong University, the University of Texas at Austin, and the University of Cambridge. This method can achieve spatio-temporal consistent 4D content generation in just a few minutes.
Diffusion4D(Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models) has organized and filtered approximately 81K 4D assets, utilizing 8 GPU cards with a total of 16 threads, spending over 30 days rendering around four million images, including static 3D object rotations, dynamic 3D object rotations, and dynamic 3D object foreground videos.
This method is the first framework to use a large-scale dataset to train video generation models for generating 4D content. Currently, the project has open-sourced all rendered 4D datasets and rendering scripts.

-
Project link: https://vita-group.github.io/Diffusion4D/ -
Paper link: https://arxiv.org/abs/2405.16645
1. Research Background
Past methods have made breakthroughs in 4D (dynamic 3D) content generation using 2D and 3D pre-trained models, but they mainly relied on score distillation sampling (SDS) or generated pseudo-labels for optimization. Using multiple pre-trained models for supervision inevitably leads to spatio-temporal inconsistencies and slow optimization speeds.
The consistency of 4D content generation includes both temporal and spatial consistency, which have been explored in video generation models and multi-view generation models. Based on this insight, Diffusion4D embeds spatio-temporal consistency within a single model and obtains cross-view supervision across multiple timestamps at once.
Specifically, using a carefully collected and filtered high-quality 4D dataset, Diffusion4D trained a diffusion model capable of generating dynamic 3D object rotation views, and then used existing 4DGS algorithms to obtain explicit 4D representations. This method achieves generation based on text, a single image, and 3D to 4D content.
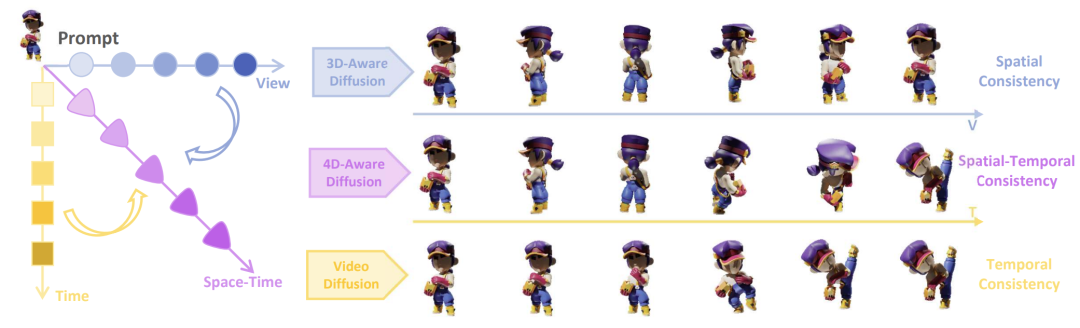
2. 4D Dataset
To train the 4D video diffusion model, Diffusion4D collected and filtered a high-quality 4D dataset. The open-sourced Objaverse-1.0 contains 42K moving 3D objects, while Objaverse-xl includes 323K dynamic 3D objects. However, these datasets contain a large number of low-quality samples, so researchers designed filtering methods such as motion degree detection and boundary overflow checks, selecting a total of 81K high-quality 4D assets.
For each 4D asset, 24 static view images were rendered (first row of the above image), 24 dynamic view rotation images (second row), and 24 frontal dynamic images (third row). In total, over four million images were obtained, with a total rendering consumption of approximately 300 GPU days. More details about the dataset can be found on the project homepage. Currently, all rendered datasets and original rendering scripts have been open-sourced, and more usage methods for the datasets are worth exploring!
3. Method
With the 4D dataset in hand, Diffusion4D trained a 4D-aware video diffusion model.
Previous video generation models typically lack 3D geometric prior information, but recent works such as SV3D and VideoMV have explored using video generation models to obtain multi-view static 3D objects. Therefore, Diffusion4D chose VideoMV as the base model for fine-tuning training, enabling the model to output dynamic rotation videos.
Additionally, modules such as motion magnitude control and 3D-aware classifier-free guidance were designed to enhance motion degree and geometric quality. Thanks to the stronger coherence advantages of the video modality, the output results exhibit strong spatio-temporal consistency.
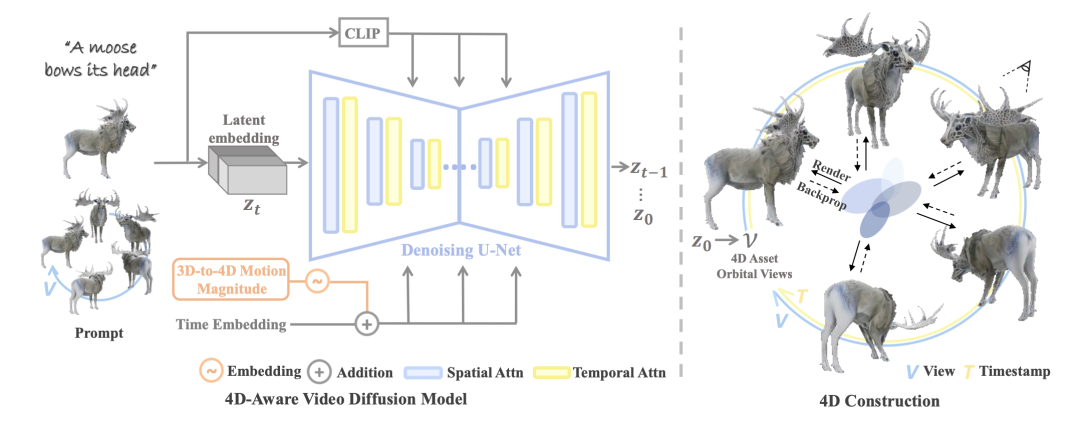
After obtaining dynamic view rotation videos, Diffusion4D utilized existing 4D reconstruction algorithms to model the videos into 4D representations. Specifically, it adopted the representation form of 4DGS and used a two-stage optimization strategy with coarse-grained and fine-grained approaches to obtain the final 4D content. The two steps from generating rotation videos to reconstructing 4D content only take a few minutes, significantly faster than the past methods that required hours using SDS optimization.
4. Results
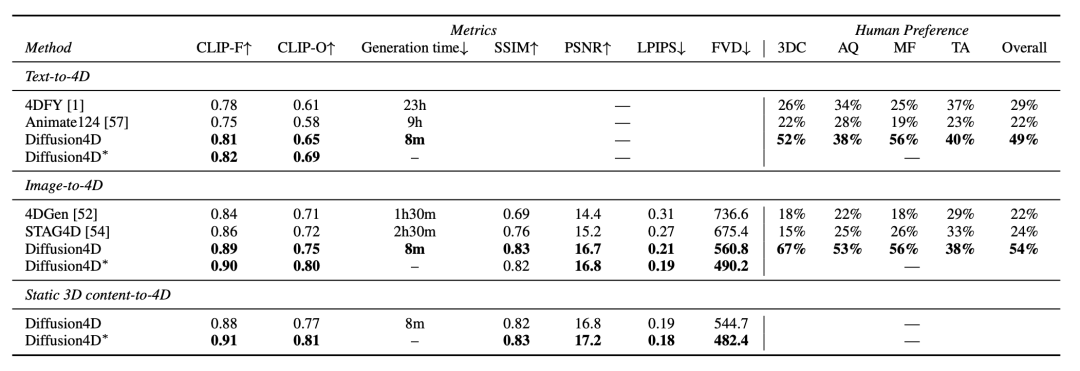
Depending on the modality of the prompt information, Diffusion4D can achieve generation from text, images, and 3D to 4D content, significantly outperforming previous methods in quantitative metrics and user studies. In terms of generation quality, Diffusion4D exhibits better detail, more reasonable geometric information, and richer motion. More visual results can be referenced on the project homepage.
5. Conclusion
Diffusion4D is the first framework to utilize video generation models for 4D content generation. By using over 81K datasets and a carefully designed model architecture, it achieves fast and high-quality 4D content. In the future, there is still significant exploration space for maximizing the value of 4D datasets and generating multi-object, complex scene 4D content!
For the latest AI progress reports, please contact: [email protected]

END
Welcome to join the “Video Generation“ group chat👇 Please note:Generation