Contemporary AI is surging forward. This article analyzes the evolution of application engineering architecture in the AI era from the characteristics of AI, the challenges it poses to development, and the differentiation of AI applications and scenarios.
In the current era of generative models, understanding and utilizing AI-related technologies is something that front-end and back-end developers will inevitably face.
All products deserve to be reimagined with AI.The fundamental reason is that the current form of AI, namely generative models, changes and creates new product forms with AI assistance, rather than merely supplementing existing product forms like previous technologies.
In simple terms, developers now have more capabilities than ever.
1. Characteristics of Contemporary AI
Contemporary AI is surging forward, possessing a powerful reasoning capability that is general and applicable to various fields and modes. Various theoretical practices have exploded in growth over the past two years, and people’s understanding of contemporary AI is basically at the same starting line, which is one of the key reasons for the allure of contemporary AI.
For AI, a large amount of research has shown that human consciousness is non-algorithmic. From Gödel’s incompleteness theorem to Turing’s uncomputable problems, it has been confirmed that artificial intelligence based on Turing machines, i.e., contemporary AI based on language models and pre-trained large models, cannot establish the concept of ‘self’.
Therefore, contemporary AI still relies on the theoretical framework of Turing, solving Turing-computable problems, and thus requires a well-sustainable application architecture to constrain, guide, and manage it.
2. Challenges for Development
Returning to reality, the existing experience and knowledge of front-end and back-end developers cannot quickly overcome this threshold. Moreover, large model algorithms, training acceleration, heterogeneous computing, etc., are not the domains and strengths of front-end and back-end developers.
However, from the recent surge of AIGC-related practical articles, it can be seen that many practitioners are not algorithm experts, indicating that front-end and back-end developers can indeed accomplish this. In other words, the barrier to developing applications based on existing large models can still be crossed.

3. AI Application Engineering
The so-called AI-oriented development process involves continuously inputting prompts into large models to reason and obtain our expected results under the control of context.
The efficiency of the reasoning process and the quality of the results depend not only on the stability of the large model but also significantly on our practical experience, which is the technology of asking questions or guiding AI.

Imagine we are conversing with a person rather than AI; how should we establish context and guidance through dialogue to meet our needs, even if that need is unreasonable? A book titled The Art of Deception specifically introduces the concept of social engineering for such scenarios.
Similarly, the corresponding concept for AI is the currently popular prompt engineering, where someone previously attempted to have ChatGPT act as a grandmother telling a story about Windows activation codes, resulting in a usable MAK KEY. This process of prompt engineering, akin to human social engineering, completely subverts traditional programming knowledge.
4. AI Scenario Differentiation
Unlike the generalized concept of AIGC content generation, AI needs to differentiate into various characteristics in different scenarios. Below are three typical categories of intelligent scenarios:
Unlike traditional knowledge scenarios, in the AI era, we can also have knowledge summarization, extraction, summarization, classification, and content processing conversion scenarios.
For example, structuring knowledge into graphs (such as mind maps, flowcharts, architectural diagrams, etc.), adding detailed content (like examples, annotations), etc.
4.2 Interaction-Intensive
For instance: role-playing, social assistance, scenario consulting, decision support, and comprehensive coordination of office tasks emphasize human-computer interaction scenarios where large models play different roles.
In addition to generating large amounts of unstructured text, there are also low-code, no-code, and mixed development scenarios related to code generation, code testing, code translation, and code review.
It is evident that the intelligent scenario problems we face are quite complex, and it is challenging to solve these ever-changing demands through human pre-thought solidification, as the freedom of these scenarios is too great. Compared to the mere dozen keywords of general programming languages, human thinking is free and difficult to constrain. In this context, using conversational prompts in AI applications to solve complex problems is nearly uncontrollable.
Therefore, how to engineer AI applications into a controllable form to address current issues like large model hallucinations and drifts is a crucial problem worth pondering and the core of our discussion. We need to introduce new theoretical guidance to generate new architectures to solve these problems.
Next, we will explain typical algorithms and practical architectures for large models in the industry:
The core capability of using large models is reasoning. Below are several well-known AI reasoning solutions in the industry.
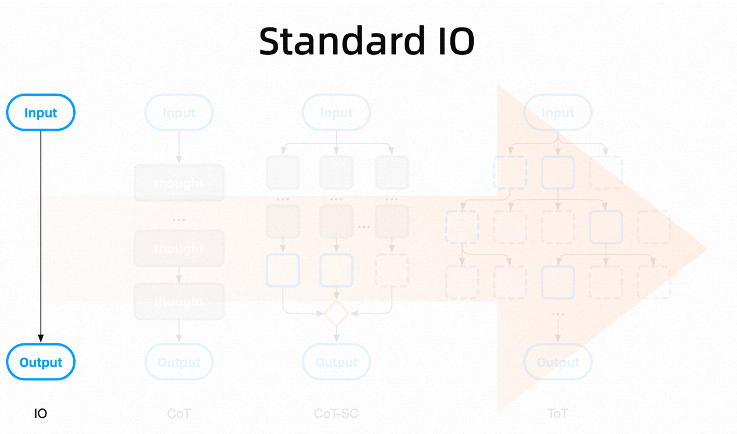
When there is no reasoning process, if we ask the large model a question, it will directly provide an answer. This zero-process reasoning is called Standard IO. In most cases, Standard IO cannot solve our problems in one step; we need to identify and further guide it, making it almost unusable for complex tasks and thus generally used as a comparative reference in various optimization experiments.
5.1.2 Chain of Thought (CoT)
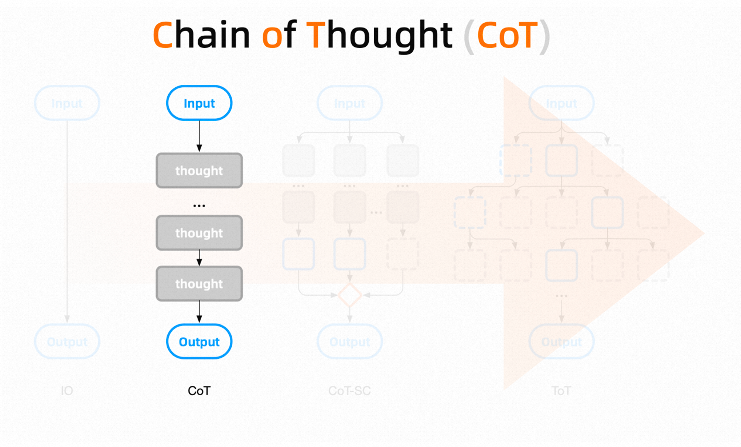
In 2022, the publication of the famous Chain of Thought (CoT) paper played a key role in how AI handles complex tasks. It involves breaking a complex task into multiple manageable sub-tasks, allowing the large model to think step by step, making each small task’s prompt and reasoning controllable.
It can be simply understood as, “Instead of directly asking the large model to give a result, we let the large model reason step by step to produce inferences and ultimately provide a result.” This technique often achieves good results under Zero-Shot/Few-Shot scenarios. CoT has become a necessary paradigm in AI application engineering, akin to a process-oriented development model that we will continue to use.
At this point, we must mention Chains, a module provided by the renowned large model application development framework Langchain. As the name suggests, the architecture of chains can be understood as the implementation and extension of CoT, from the basic LLMChain to common scenarios such as: APIChain, Retrieval QAChain, SQL Chain, etc.
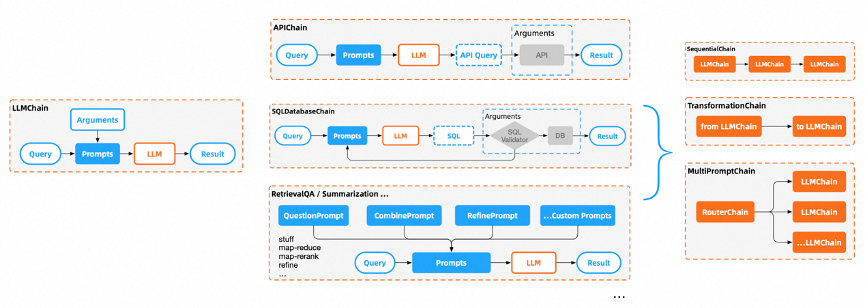
In the Chains architecture, each process from Prompt to Answer is standardized into different types of LLMChain.
The entire flow from demand to result is abstracted into a series of linked LLMChains, resembling structured and functional programming that we are familiar with.
This is good news; if prompts and answers are water and soil, then with the theoretical guidance of CoT and the architecture of Chains, it is like channeling a river, solidifying the previously uncontrolled reasoning process of AI into Chains and their connections, returning everything to the process we recognize.
But is this really the future of AI application development? Is the approach of Chains, which relies on human thought and solidifies the reasoning process, all that AI can offer?

At this point, we can ponder a question:
In the field of AI, are we using the gold of AI to make hoes? Is your intuition that AI’s capabilities and applications are not limited to this? Is it that traditional architectures or programming paradigms have restricted our imagination?
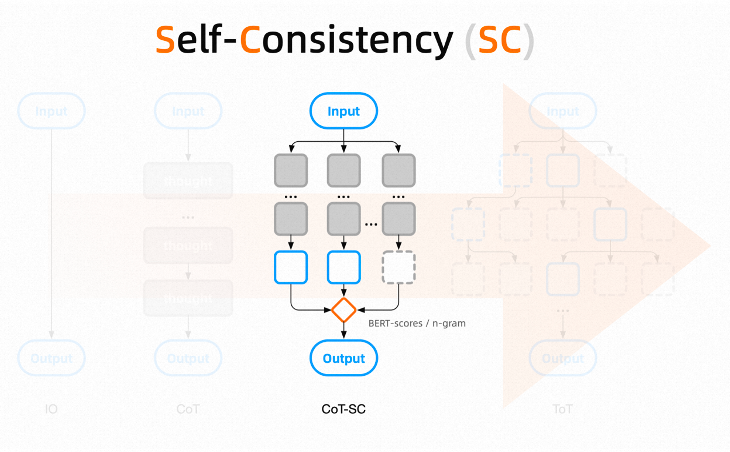
5.3.1 CoT Self-Consistency (SC)
In May 2023, the SelfCheckGPT paper mentioned a mechanism called Self-Consistency, which made significant contributions to hallucination detection. It can be simply understood as, “For a question, let multiple individuals participate in multi-step thinking and answering, and ultimately have another person score to select the best answer.”
For a question, generating multiple CoTs at once and voting on the inferences of each CoT can yield the most accurate inference, with the voting done by an evaluation function, commonly using BERT Score or n-gram.
5.3.2 Tree of Thought (ToT)
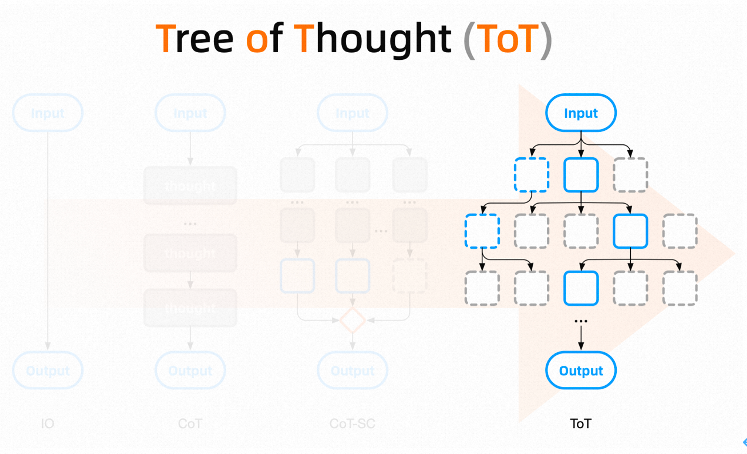
Also this year, the Tree of Thoughts (ToT) paper was published. If CoT is a chain, then ToT is a tree composed of multiple CoT chains. ToT reveals that AI can autonomously extend through the reasoning decision process, which is a significant breakthrough.
CoT emphasizes the process of breaking down tasks into sub-tasks, while ToT emphasizes that breaking down tasks generates multiple thinking processes. Ultimately, the entire ToT forms a tree structure of thought, allowing us to conveniently use breadth-first (BFS) or depth-first (DFS) search to solve complex problems, where the thinking paths, or the inference states of CoT, can be evaluated using Self-Consistency or other more advanced methods.
The tree structure formed by the large model’s self-reasoning decision-making is completed based on AI’s drilling down into scenarios and logical coherence, essentially replacing the entire process of understanding, analyzing, executing, and verifying that humans previously had to perform in repeated iterations until arriving at the correct result.
6. Augmented Language Models (ALM)
At this point, we have gained limited automated reasoning and hallucination detection capabilities, but the potential of large models goes beyond this. In early 2023, Turing Award winner Yann LeCun introduced the concept of Augmented Language Models (ALM) in a paper, highlighting three components of ALM:
-
Reasoning: Decomposing potentially complex tasks into simple sub-tasks that can be solved by the language model itself or by calling other tools.
-
Behavior: The tools called by ALM will impact the virtual or real world and observe the results.
-
Tools: Language models can call external modules through rules or special tokens, including retrieval systems for external information or tools that can control robotic arms, etc.
The context length of the large models we can currently use is too small to keep up with the expanding scale of applications. Therefore, large models should have the ability to acquire data from external sources or impact the outside world to expand context; this external environment is what we refer to as the environment.
For example, “The large model operated the robotic arm to pick up a cup of coffee” [16]. For this Act, the tools are the robotic arm, the action is to pick up, and the action input is the coffee on the table, while “the coffee is in the robotic arm” and “there is no coffee on the table” are the observations [16].

This example of WebGPT [17] is very much like a GPT version of Bing; it is a relatively pure Act-type large model. When a question is posed to WebGPT, it will search the web and provide suggested results. Users can filter and sort these results, after which WebGPT processes and generates the answer.

Previously, acting and reasoning were treated separately, and even when combined, they were not viewed through an architectural lens. In October 2022, the proposal of ReAct finally connected reasoning and acting together and has since become the de facto standard in the industry. So what does the application engineering practice look like for this architecture?
Since the initial version of AutoGPT was released in April of this year, it has quickly gained popularity in the AI application circle. One reason is that AutoGPT’s performance seems to be closer to our aspirations for AI application architecture:
For AutoGPT, we only need to set a goal for it and grant it resources and the ability to interact with those resources, along with a set of rules that limit its behavior. It can then gradually approach the goal through a process of self-questioning and answering, ultimately completing the task through result evaluation.
In contrast to Chains, which rely on human thought and solidify the reasoning process, AutoGPT appears to allow AI to self-generate the reasoning process. Compared to the Chains architecture, the reasoning and acting processes of AutoGPT are automated, effectively negating human advantages in prompt engineering.
However, this unrefined, raw self-questioning and answering method, while it can help us solve certain complex problems, is much less efficient in reasoning decision-making compared to the human thought and solidified reasoning decision-making process, particularly in terms of effectiveness and flexibility in solving real-world decision tasks. Its limited ability to engage with the real world and lack of benchmarks lead to these uncertainties. Therefore, further optimization is required to approach our ideal design for AI application architecture.
The industry has long recognized the importance of the reasoning decision-making process in application architecture and has conducted benchmarks for effectiveness and flexibility for applications like Auto-GPT. From LangChain Agents to Huggingface’s recently announced Transformers Agent, still in the experimental phase, and Unity ML-Agents in game development, I have learned about a more refined AI application architecture based on scenario differentiation, referred to as the Agents architecture:
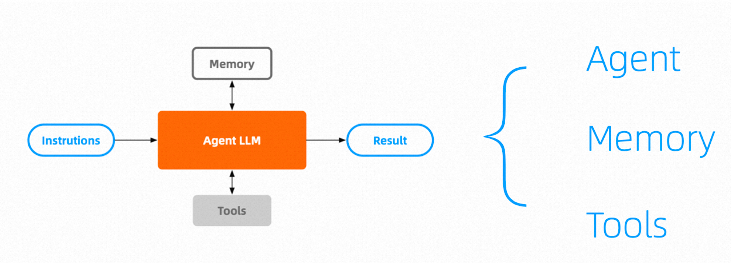
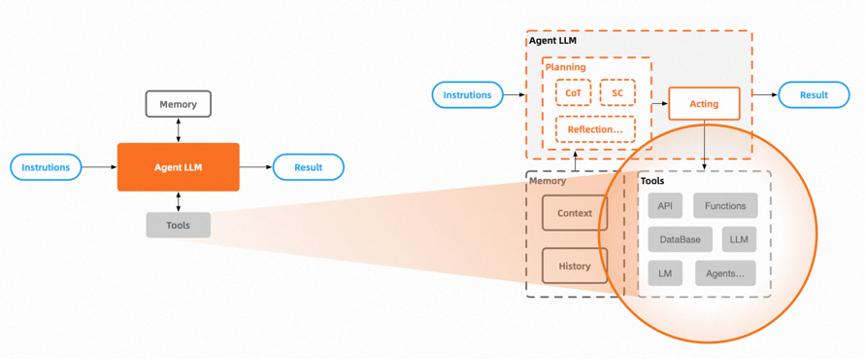
A typical Agents architecture includes the following components:
An optimized large model dedicated to reasoning and acting, with its core capability being task planning and reflection for continuous improvement, requiring strong reasoning and decision-making abilities.
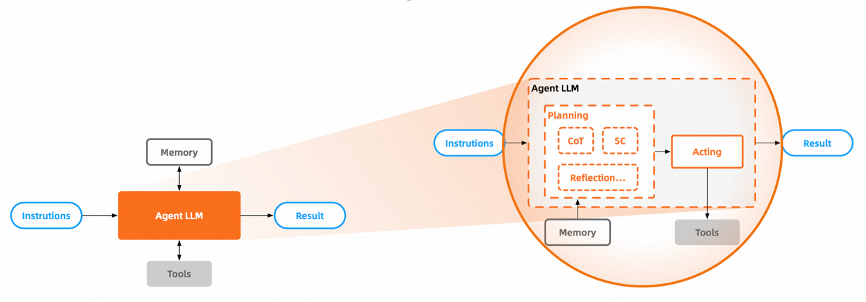
Task planning: Decomposing large tasks into smaller, manageable sub-goals for efficient execution of complex tasks.
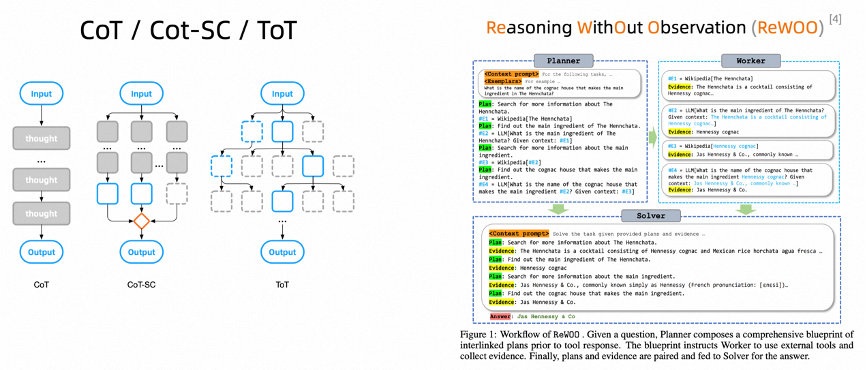
As previously mentioned regarding reasoning, XoT (CoT, Cot-SC, ToT) are all typical examples. Additionally, I introduce ReWOO, which is also a planning-based solution. The idea is that when a problem is posed, various plans to solve the problem are formulated, leaving the results of the plans empty (termed a blueprint). Each plan is treated as an act executed by a worker, and the results are filled into this blueprint, ultimately leading to a result from the large model. Unlike general solutions, it does not require step-by-step execution, highlighting a good solution for “planning” capabilities.
7.1.2 Reflection and Continuous Improvement
Reflection and continuous improvement simply refer to providing improvement plans for the large model, helping it learn from previous mistakes to better complete future tasks.
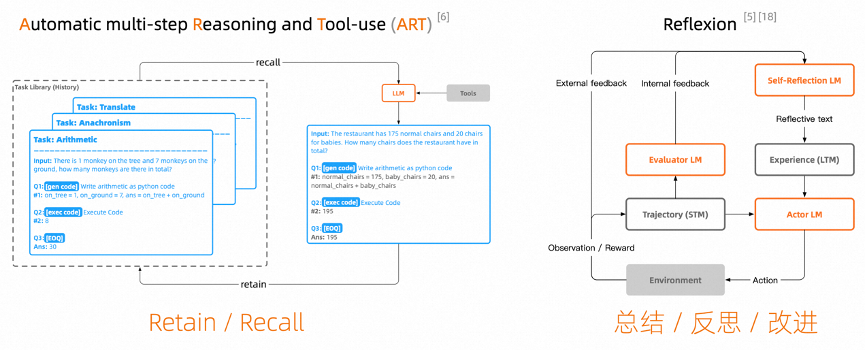
ART[6] & Reflexion[15] [8]
For ART, this is a supervised solution that can store previously conducted reasoning processes and recall them for future use. The process can be described as follows: a Task Library stores various types of CoT for different tasks. When an ART instance is queried, it finds the most suitable task example from the Task Library to pose alongside the user’s question to the large model, with the final result reviewed and corrected by a human brain, and the outcome persisted in the Task Library.
On the other hand, Reflexion replaces the human brain part with a language model, converting it into a framework where the large model self-learns to optimize its behavior through trial, error, and self-reflection to solve decision-making, programming, and reasoning tasks.
Notable examples in the industry include ReAct, BabyAGI, etc., with ReAct being the current de facto standard with far-reaching influence. OpenAI has also recently announced Function Call based on the GPT3.5 turbo / 4.0 model for tuning and planning.
Memory includes Context and History [13].
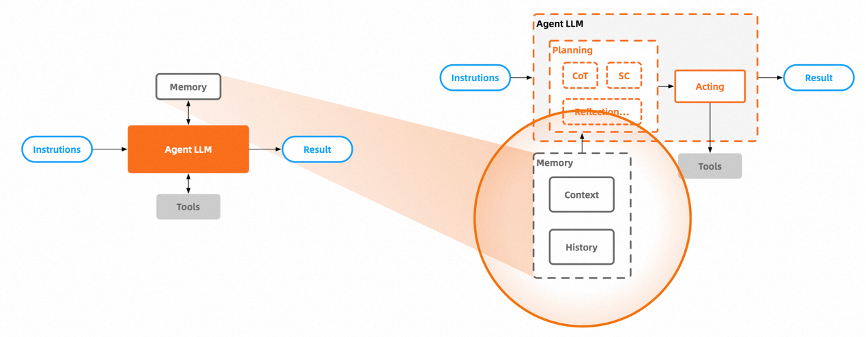
Context is something we are familiar with, similar to human STM (Short-term memory), providing the Agent with contextual capabilities. The current prompt engineering of large models is based on context.
History, akin to human LTM (Long-term memory), provides the Agent with the ability to store and recall associated data.
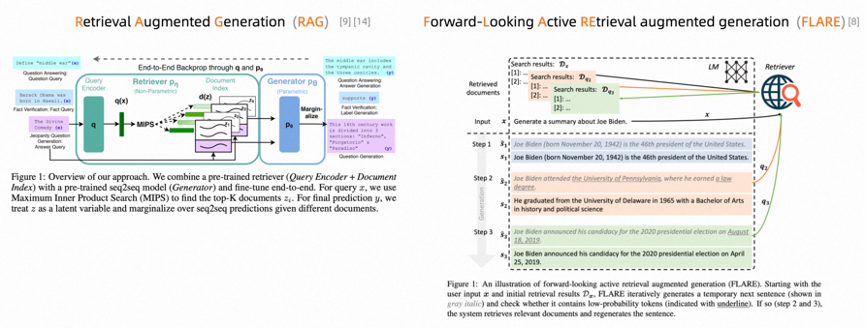
Retrieving data like WebGPT is a very common scenario. Unlike traditional content retrieval, we also have some large model-enhanced retrieval solutions, such as RAG, FLARE, etc.
In practice, it is common to choose databases that support fast maximum inner product search (MIPS) using approximate nearest neighbor (ANN) algorithms to complement these solutions. There are many vector databases available in the market, which are currently popular areas. Interested readers can explore Alibaba Cloud’s Tail-based VectorDB and the cloud-native vector data warehouse, AnalyticDB PostgreSQL version, but I won’t elaborate further here.
A set of tools or all external resources that an Agent can utilize, which represents the Agent’s callable and executable capabilities. These can be functions, APIs, or any other large models, including another Agent application, etc. [13]
ChatGPT plugins and OpenAI API Function Calls are the best examples of Tools applications.
The current common approach for the internet is to provide APIs in different fields along with documentation on their usage, allowing the Agent’s reasoning to determine whether the required API exists in the Tools.
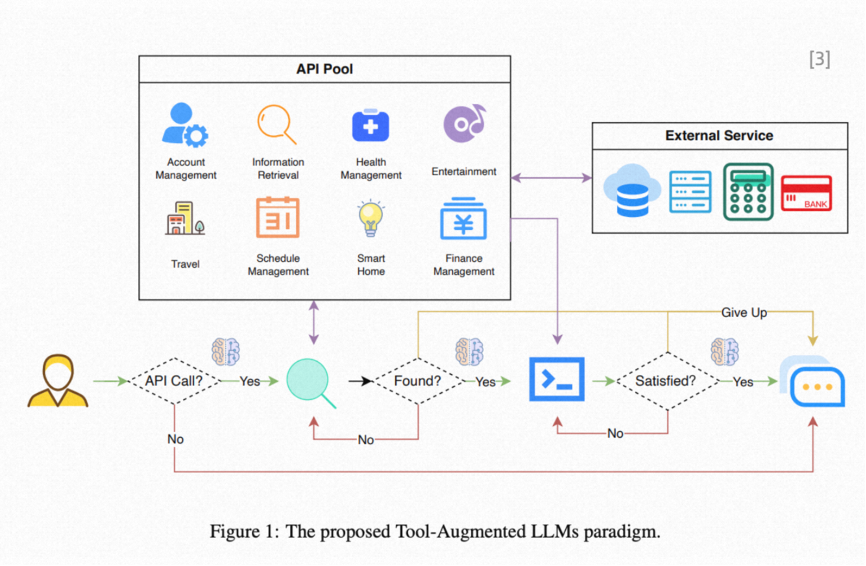
API Bank: Augment Tool[3]
API Bank is a benchmarking tool that provides a feasible API calling approach in its paper:
-
Step1. Provide the Agent with an API Manual. The Agent can search and summarize the required API usage from the API Manual using keywords in its various planned tasks. The usage instructions can be guided using the schemes proposed in prompt engineering, utilizing Few-Shot or Zero-Shot CoT to guide the Agent.
-
Step2. Provide the Agent with API and input checkers. Once the Agent has mastered the API usage, it can generate the required parameters for the API and call it to obtain results. This process requires continuous checking of whether the input parameters are correct and evaluating whether the output results meet expectations.
8. Thoughts on the Future
Compared to Chains, Agents truly unleash the potential of AI and are the advanced architecture that is about to become popular. In my understanding of Agents, they resemble an implementation architecture of Turing machines rather than the application layer architecture we usually discuss.
Let’s recall that the Turing theoretical architecture supports the Von Neumann architecture or similar Harvard architecture.
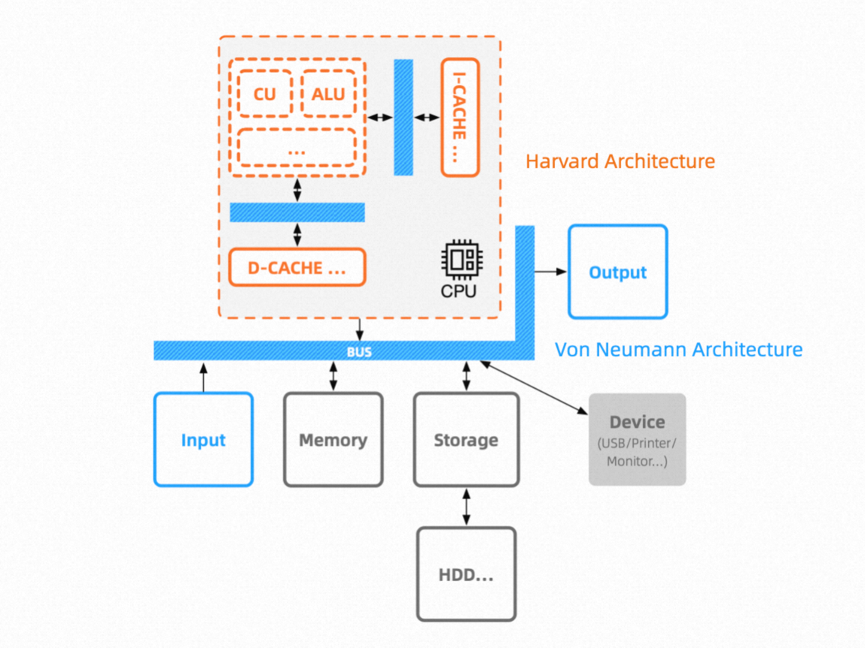
Factually, in the actual development of devices based on Von Neumann or Harvard architectures, we care about how to use corresponding protocols to address read and write bus operations for different devices, such as UART, I2C, SPI bus protocols. These are things we need to learn and master, but we generally do not concern ourselves with units like CU and ALU in the CPU.
Another fact is that the internal CPU employs a multi-bus Harvard architecture, while outside the CPU, it is based on a single bus Von Neumann architecture. Moreover, System-on-Chip (SoC) further integrates components related to high-speed computation in different scenarios, such as DSP and ARM.
The continued development of computer architectures that seek common ground while reserving differences will further abstract these units with high-speed storage and buses. Similarly, AI applications will also be akin to this, where Agents will continually encapsulate related planning, reflection, and improvement capabilities as their core competencies.
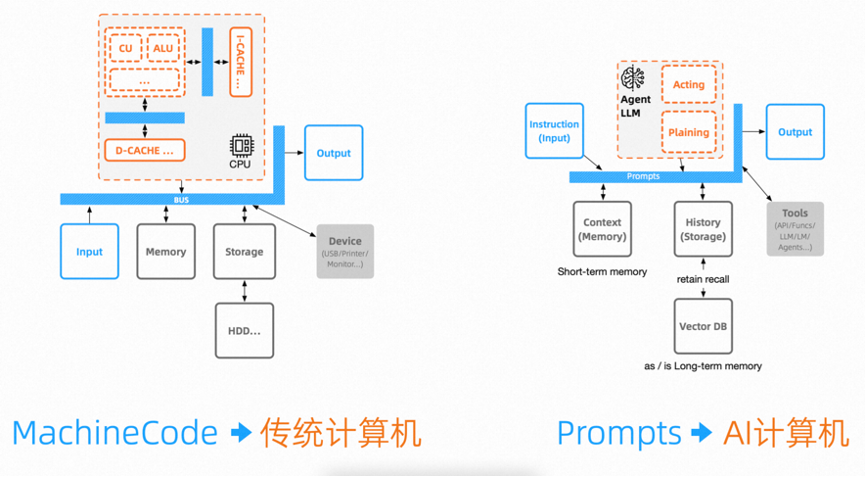
Therefore, future AI applications are likely not programs running on traditional computers, but standardized demands directly executed on AI computing virtual instances with Agents specialized in planning capabilities as the CPU. The application architectures we discuss today will eventually sediment into the core architecture of AI computers.
AI computers with Agents specializing in planning and decision-making capabilities will replace the traditional evaluation system for computing units based on core counts and GHz frequencies with assessments based on planning and decision-making capabilities. The peripheral devices that AI computers rely on, namely Tools, will delve deeper into various professional fields to provide more specialized execution capabilities.
Ultimately, AI computers will be Turing complete, elevating the iterative products of engineering from the engineering field to the industrial field through AI self-bootstrapping.
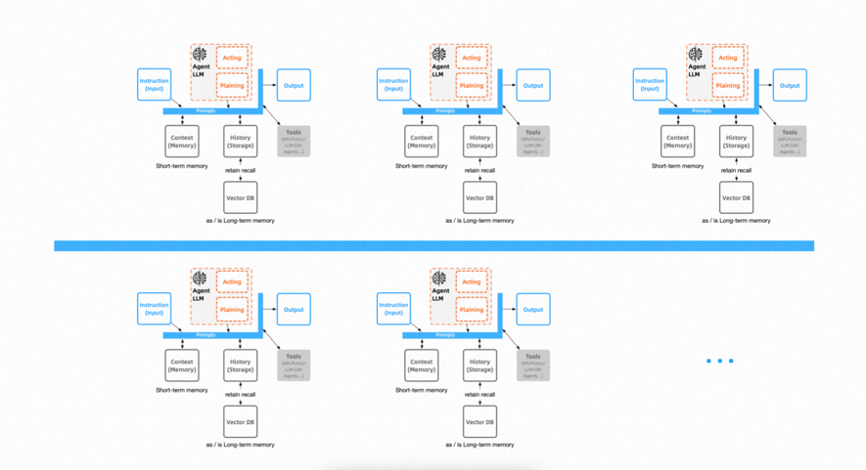
AI vendors will also transition from current Multi-Agents solutions like MetaGPT and AgentVerse to manufacturers of AI computers and related clusters or other integrated solutions. Technicians may become involved in the development of AI computer architecture or shift from single responsibilities to become ‘high-level roles’ that integrate demand design and development. The era of one-person companies may arrive sooner than expected.
[1] Augmented Language Models: a Survey (https://arxiv.org/abs/2302.07842)
[2] ReAct: Synergizing Reasoning and Acting in Language Models (https://arxiv.org/abs/2210.03629)
[3] API-Bank: A Benchmark for Tool-Augmented LLMs (https://arxiv.org/abs/2304.08244)
[4] ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models (https://arxiv.org/abs/2305.18323)
[5] Reflexion: Language Agents with Verbal Reinforcement Learning (https://arxiv.org/abs/2303.11366)
[6] ART: Automatic multi-step reasoning and tool-use for large language models (https://arxiv.org/abs/2303.09014)
[7] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (https://arxiv.org/abs/2303.08896)
[8] Active Retrieval Augmented Generation (https://arxiv.org/abs/2305.06983)
[9] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (https://arxiv.org/abs/2005.11401)
[10] Tree of Thoughts: Deliberate Problem Solving with Large Language Models (https://arxiv.org/abs/2305.10601)
[11] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (https://arxiv.org/abs/2201.11903)
[12] ReAct: Synergizing Reasoning and Acting in Language Models (https://react-lm.github.io/)
[13] LLM Powered Autonomous Agents (https://lilianweng.github.io/posts/2023-06-23-agent)
[14] Huggingface RAG Model (https://huggingface.co/docs/transformers/model_doc/rag)
[15] What do large language models mean for productivity? (https://www.bennettinstitute.cam.ac.uk/blog/what-do-llms-mean-for-productivity/)
[16] Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (https://say-can.github.io/)
[17] WebGPT: Browser-assisted question-answering with human feedback (https://arxiv.org/abs/2112.09332)
[18] Can LLMs Critique and Iterate on Their Own Outputs? (https://evjang.com/2023/03/26/self-reflection.html)
[19] Auto-GPT: An Autonomous GPT-4 Experiment (https://github.com/Significant-Gravitas/Auto-GPT)
[20] LangChain Agents (https://docs.langchain.com/docs/components/agents/)
[21] The Latest & Greatest AI Prompting Framework – Tree Of Thoughts (https://www.linkedin.com/pulse/latest-greatest-ai-prompting-framework-tree-max-karpushko)
[22] Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions (https://arxiv.org/abs/2306.02224)
[23] Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents (https://arxiv.org/abs/2306.03314)
[24] LangChain Chains (https://python.langchain.com/docs/modules/chains/)
Alibaba Cloud Developer Community, the Choice of Millions of Developers
Alibaba Cloud Developer Community, with millions of quality technical content, thousands of free system courses, rich experiential scenarios, active community activities, and industry expert sharing and communication. Welcome to click 【Read the Original】 to join us.