▲Click above Leifeng Network to follow


The Four Major Boundaries: Data Boundary, Semantic Boundary, Symbolic Boundary, and Causal Boundary
Written by | Cong Mo
Currently, deep learning in natural language processing has its limitations. So where are the boundaries of its effectiveness? This is a question we should ponder deeply.
Recently, at the Fourth Language and Intelligence Summit Forum held at Beijing Language University, Professor Liu Qun, Chief Scientist of Speech and Semantics at Huawei Noah’s Ark Lab, provided a detailed analysis of what is known and unknown in NLP during the deep learning era.
He discussed the paradigm shift in natural language processing from rule-based and statistical methods to deep learning, exploring which problems deep learning methods have solved in natural language processing and which problems remain unsolved.
Professor Liu believes that the unsolved problems are ultimately caused by the four major boundaries of deep learning: the data boundary, semantic boundary, symbolic boundary, and causal boundary. To find breakthroughs on these unresolved issues, we need to explore new solutions starting from these boundaries of deep learning.
This report is titled “Natural Language Processing Based on Deep Learning: Where Are the Boundaries?” It is a retrospective view of the entire field from the pinnacle of NLP.
Let’s take a look at the main content of Professor Liu’s report:

Thank you for this opportunity to communicate with everyone. Today, I will not talk about my specific work, but rather share some insights and reflections from my years of research in machine translation and natural language processing, discussing some issues from a more abstract level. These ideas may not be fully developed, and I hope you will point out any inaccuracies!
I believe everyone has a deep understanding of the paradigm shift in natural language processing. Taking machine translation as an example, many years ago, everyone used rule-based methods, where the basic idea was to rely on humans to write rules and teach machines how to translate. Later, people gradually discovered that this approach was unfeasible because humans cannot exhaustively write all the rules, nor can they write a large number of very detailed rules.
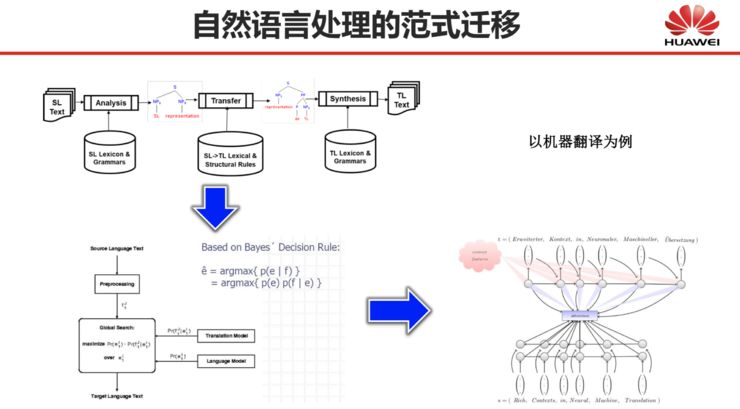
Therefore, everyone later turned to statistical machine translation methods, which involved giving the machine a bunch of corpora to learn translation rules on its own. However, what it learned were still some symbol-level rules, but with probabilities assigned. After a certain point, statistical machine translation encountered some bottlenecks and it became difficult to improve further.
With the introduction of deep learning methods in recent years, the level of machine translation has significantly improved, allowing machines to translate not merely at the symbol level, but to map the entire reasoning process into a high-dimensional space and perform computations in that high-dimensional space. However, we can only understand the input and output, but do not know how the computations occur in high-dimensional space, nor can we clearly articulate what the machine has learned automatically.
Next, I will attempt to explore several questions: First, what problems has deep learning solved in natural language processing? Second, what natural language processing problems remain unsolved by deep learning? Third, where are the boundaries of natural language processing based on deep learning?
The field of natural language processing has many difficult problems that researchers previously struggled to solve. After the emergence of deep learning methods, some problems have been effectively addressed, or although not completely resolved, they have provided a good framework. These problems mainly include: Morphological issues, syntactic structure issues, multilingual issues, joint training issues, domain transfer issues, and online learning issues. Here, I will mainly discuss the first four issues and will not elaborate on the latter two.
Morphological Issues
Morphological issues refer to the study of the composition of words. In Chinese, it manifests in word segmentation, while in English and most other languages, it is primarily reflected in morphological analysis. Among them, word segmentation has been a very headache-inducing problem in Chinese information processing, including machine translation, and we have spent a lot of effort to solve it.
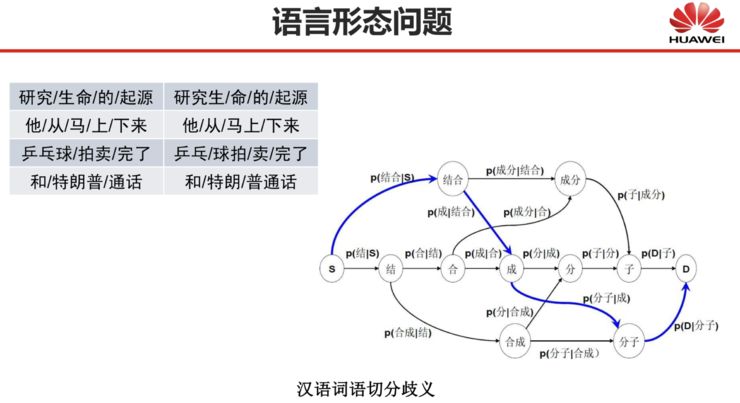
In both rule-based and statistical machine translation methods, morphological analysis is the first issue that machine translation needs to solve.
For Chinese, due to the poor translation effect based on characters, word segmentation is a necessary problem to solve. This means that if word segmentation is not done or done poorly, even using statistical methods, the results will be very poor. However, word segmentation itself faces many issues because Chinese words are not clearly defined units, leading to a lack of unified standards for segmentation and difficulty in determining the granularity of segmentation.
Many languages other than Chinese also have morphological issues. For instance, English has a relatively simple morphological problem because English words change less. However, many other languages have many variations, such as French, which has forty to fifty variations, and Russian, which has even more. Additionally, in agglutinative languages like Turkish and Persian, a single word can have thousands of variations, meaning that many affixes can be added to one word, which poses significant challenges for natural language processing, especially machine translation.

Moreover, for these morphologically rich languages, the analysis difficulty is also high, generally requiring linguists to accurately describe the morphology of words. At the same time, morphology itself is a layer of structure, and all statistical machine translation is built on some structural basis, such as word layer, phrase layer, syntactic layer, or methods based on words, phrases, or syntax. If we want to add another layer of morphological structure to these structures, modeling for statistical machine translation becomes very difficult.
During the era of statistical machine translation, processing complex morphological languages was very difficult. A relatively famous method called Factored Statistical Machine Translation, which translates based on factors, involves breaking a word down into many factors and translating each factor separately before summarizing them. However, I dislike this method because I find it inelegant, overly redundant, and not very effective.

However, the issue of linguistic morphology is no longer a significant problem under the neural network framework. Researchers in this field have not discussed Chinese word segmentation much anymore. Although there are some interesting articles on how to achieve better segmentation under the neural network framework, for machine translation, Chinese word segmentation no longer poses a fundamental challenge, because now machine translation can basically operate without word segmentation, and most Chinese machine translation systems are based on characters, achieving performance similar to that of word-based systems.
For morphologically complex languages, a model based on subwords or character-based machine translation models has been proposed, which also performs very well. I believe this is a unified and elegant solution.
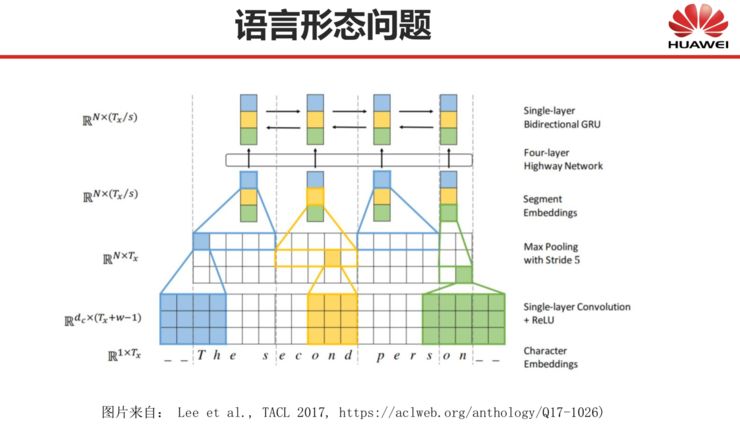
A paper by Zhang Jiajun from Automation introduces the solution idea of the subword-based model scheme, as shown in the following diagram. The first line is standard Chinese, the second line is after word segmentation. Now, general systems can operate based on characters, as shown in the third line, but we can also perform word segmentation, such as the fifth line, which segments “繁花似锦” into “繁花”, “似”, and “锦” as three subword parts.

The character-based model operates at the letter level, modeling and translating each letter for English, and it also performs very well. Therefore, I believe that under the neural network framework, morphological issues are not significant problems anymore.
Syntactic Structure Issues
Next, let’s look at syntactic structure issues.
Whether in rule-based or statistical machine translation frameworks, syntactic analysis plays an important role in the quality of machine translation. In statistical machine translation, phrase-based methods have achieved great success, so most statistical methods do not perform syntactic analysis.
However, for languages like Chinese and English, which have significantly different grammatical structures, performing syntactic analysis yields much better results than not doing it, so syntactic analysis is still very important. However, syntactic analysis is very difficult. On one hand, it increases model complexity, and on the other, errors in syntactic analysis can affect translation performance.
Currently, under the neural network machine translation framework, neural networks can effectively capture sentence structures without needing syntactic analysis, and the system can automatically acquire the ability to translate complex structured sentences.
From around 2005 to 2015, I was engaged in statistical machine translation research, specifically studying how to incorporate syntactic methods into statistical approaches. Over the years, we proposed many methods and wrote numerous papers, and the models in the following diagram summarize the methods we previously proposed.
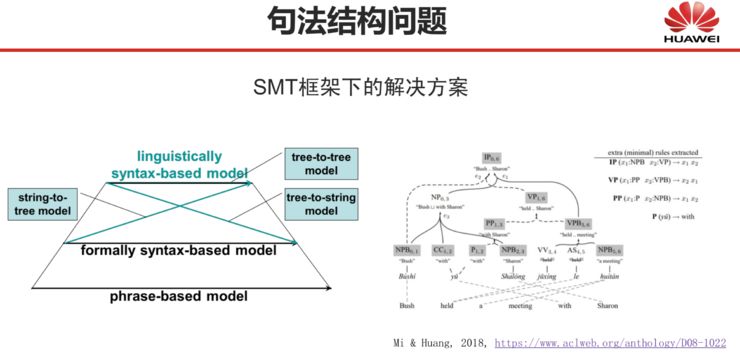
Our work mainly focused on tree-to-tree and tree-to-string methods. Many scholars from the US and Europe are working on string-to-tree methods, while tree-to-tree methods have been less studied. Additionally, we also conducted research on forest methods, which aim to avoid syntactic analysis errors. However, these issues are largely non-existent under the neural network framework.
For example, “The second Canadian company was removed from the list of transporting rapeseed to China due to the discovery of pests” is a nested structure with several layers, but the machine translation result “The second Canadian company was removed from the list of transporting rapeseed to China due to the discovery of pests” translates well structurally. The next example also translates structurally without any errors.

The neural network machine translation methods do not utilize any syntactic knowledge; they achieve such good results solely based on the complex structures learned from the network, making syntactic analysis less meaningful for machine translation. Of course, syntactic structure is not entirely meaningless; many are still studying it, but I believe it is no longer a major difficulty in machine translation.
Multilingual Issues
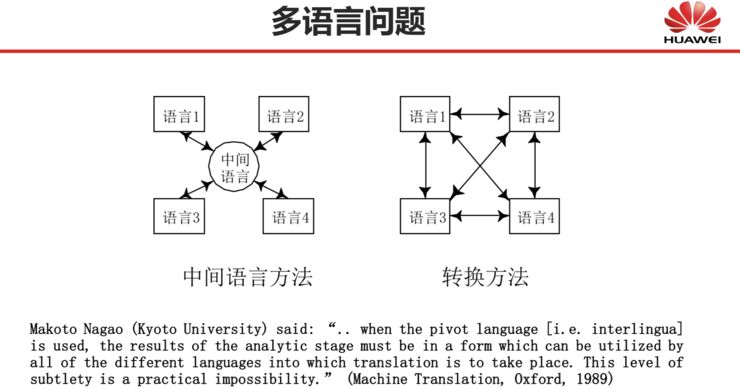
Once, a goal for us machine translation researchers was to achieve multilingual translation during the rule-based era. At that time, many were working on multilingual translation, even intermediate language translation. As shown in the following diagram, intermediate language translation is actually an ideal solution because translating between multiple languages through an intermediate language can save a lot of costs: If using an intermediate language, the number of systems developed grows linearly with the number of translation languages; otherwise, the number of systems grows quadratically with the number of translation languages.
However, during the rule-based machine translation era, the intermediate language approach was unfeasible. As Japanese machine translation expert Professor Makoto Nagao once said, when we use an intermediate language, the output results of the analysis phase must adopt a form: this form must be usable by all different language machine translations. However, achieving such subtlety is practically impossible.
In the era of statistical machine translation, the common approach was the Pivot method, which involves translating all languages into English first before translating into another language. This allows for the possibility of multilingual machine translation.
However, this method also has issues, such as leading to error propagation and performance degradation. On the other hand, another idea we had for multilingual translation was to leverage the inter-augmentative characteristics of many languages, as many languages share similar features; thus, if we cannot utilize this enhancement, this method is not ideal.
In the era of neural network machine translation, Google directly utilized the intermediate language method to create a complete and large system that allows for mutual translation between all languages and encodes all text together. Although this system is not yet perfect, it is very close to the ideal of Interlingua.
Subsequently, Google launched Multilingual BERT, which encodes 104 languages into a single model, something that was previously unimaginable.

Although these two methods have not yet completely solved the multilingual issues, their overall framework is very elegant, and their performance is excellent, so I believe there is still much work to be done in these areas.
Joint Training Issues
In the era of statistical machine translation, because each module was independently trained, the problem of error propagation was very severe, so joint training became an effective means of improving performance.
However, joint training itself also significantly increases model complexity, making development and maintenance difficult. At the same time, due to the dramatic expansion of search space, system overhead also increases significantly. Not only that, but because there are too many modules, only a limited number can be jointly trained, so it is impossible to include all modules in joint training.
In the neural network machine translation framework, end-to-end training has become the standard mode, with all modules forming an organic whole, training towards the same objective function simultaneously, effectively avoiding error propagation and improving system performance.
What Other Natural Language Processing Problems Remain Unsolved by Deep Learning?
Due to the application of deep learning, many tasks that used to require great effort are no longer necessary. However, deep learning still faces many issues, including resource scarcity, interpretability, trustworthiness, controllability, long text issues, and lack of common sense.
Resource Scarcity Issues
Resource scarcity issues are widely recognized, but this problem is far more serious than most people imagine. Generally speaking, for common languages, machine translation can perform well; however, in the real world, there are thousands of languages. A report once counted over 7000 languages, although there aren’t as many languages with writing systems, most languages are resource-scarce languages, and most professional fields are actually also resource-scarce fields.
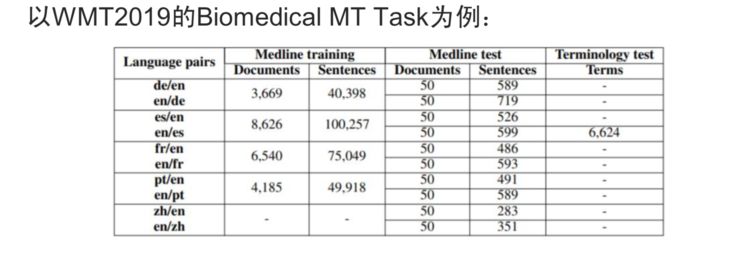
For example, the WMT 2019 evaluation in the medical field had a corpus that included over 3000 documents and over 40,000 sentences. In the field of machine translation, millions of sentences are considered a small quantity, and commercial systems generally have tens of millions of sentences of training corpus. However, here there are only over 40,000 sentences, indicating a serious resource scarcity problem, resulting in very poor translation quality, which is basically unacceptable. Additionally, from the data perspective, Spanish has over 100,000 sentences, French has over 70,000, while Chinese has none, which means it is basically impossible to collect translation data in the medical field for Chinese.
In the industry, most of the problems we want to solve lack labeled corpora, requiring us to label them ourselves, but there is often insufficient funding to label many corpora. Therefore, the resource scarcity problem is more severe than we imagine.
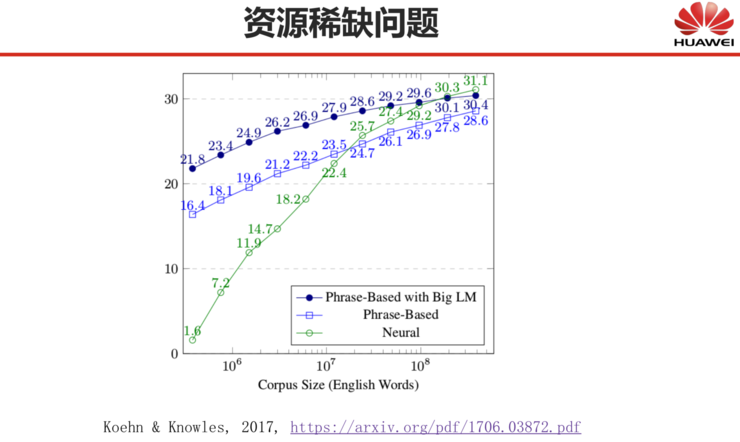
Resource scarcity significantly impacts neural network machine translation. As shown in the graph below, the upper two lines indicate statistical machine translation methods, while the lower line indicates neural network machine translation methods. We can see that neural network methods only perform better than statistical methods when there is a large amount of corpus; when the corpus is not large enough, their performance is not better than statistical methods.
Interpretability and Trustworthiness Issues
We input something into the neural network, and it outputs a result; however, we do not know the computational process in high-dimensional space, which raises interpretability issues. However, I believe the severity of this issue depends on the situation; sometimes we need interpretability, but not all the time. For instance, when the human brain makes decisions, sometimes it may just be a sudden inspiration, and even the individual may not be able to explain how it came about.
A more important issue arising from interpretability is trustworthiness. In critical fields such as medicine, for example, if a system provides a cancer diagnosis without giving a reason, patients are unlikely to proceed with treatment. Therefore, in these critical applications, interpretability is very important, as this issue can lead to trust issues.
One trust issue in machine translation is translation errors. For instance, important names, places, and organizations should not be mistranslated. Taking the translation of a US government work report as an example, if the machine translates the US President (Trump) as President Bush, that is a serious error.
The second trust issue is when the translated meaning contradicts the original meaning. This is also common in machine translation and difficult to avoid, as such contradictory expressions have very similar statistical features in the corpus, often stating the same thing, making it easy for machine translation to produce results that contradict the original meaning.
The third trust issue is when machine translation makes naive and entirely avoidable mistakes, which directly leads to a lack of trust.
Controllability Issues
Since the system’s performance is sometimes unsatisfactory or consistently makes errors, we hope the system becomes controllable, meaning we know how to modify it to avoid making such mistakes.
In rule-based machine translation methods, we can correct errors by modifying rules; in statistical machine translation methods, although the modification approach is more indirect, the statistical data is interpretable, allowing us to incorporate a phrase table for corrections. However, in neural network machine learning methods, we can hardly make modifications.
For important names, places, organizations, and terminologies, we hope the machine translates them strictly according to given methods, without arbitrary translations. I previously led students in early comparative work on this aspect while in Ireland, and the current citation count is still relatively high. We have made some improvements to this work, which can relatively well address the controllability issue in machine translation, but this work is still applicable only to this specific case and cannot generalize to solve the controllability issues present in the entire natural language processing field.
Long Text Issues
Current neural network machine translation has made significant progress in handling long texts. Earlier neural network translation systems were often criticized: they performed well on short sentences but poorly on long sentences. However, this situation has improved significantly; general long sentences translate well, but small errors like omissions are still unavoidable.
Now, language models trained on long texts, such as BERT and GPT, typically use text units of hundreds to thousands of words, so handling texts within this range is not a major issue, and GPT can generate texts under a thousand words very fluently.
Currently, machine translation can handle relatively long texts, but it cannot be said that the long text issue is resolved; it still presents many challenges:
-
One is the discourse-based machine translation issue. Not only us, but many peers in academia are also researching this issue. Discourse-based machine translation experiments have shown that the context that significantly improves translation quality includes only the first 1-3 sentences; longer contexts can even reduce the translation quality of the current sentence. Logically, longer contexts should lead to better machine translation results, so why does it translate worse instead? This is unreasonable.
-
The other is the pre-trained language model issue. Currently, the training length for machine translation is generally hundreds to thousands of words; however, the actual text being processed may exceed a thousand words, such as an eight-page English paper, which is at least two to three thousand words long. Therefore, pre-trained language models encounter many issues when processing longer texts. In such cases, the language model consumes enormous computational resources, and the time and space required for computation grow quadratically or cubically with sentence length, so existing models have many unresolved issues in supporting longer texts.
Lack of Common Sense Issues
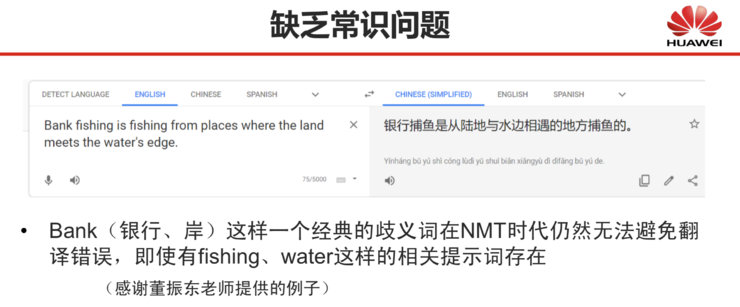
Here, I provide an example from the recently deceased Mr. Dong Zhendong (as shown in the figure below): “bank” is a classic ambiguous word in translation, meaning both “bank” and “shore”. In what context to translate into which meaning is easy for humans to understand, but even with related prompt words like fishing and water, Google Translate still translates it as “bank”. In the era of neural network machine translation, such common sense errors remain prevalent.
Another example is the text generation by GPT.GPT has performed very well in text generation, but even so, it still makes many common sense errors. Taking the classic case below as an example, the human input sentence is: “In a study, scientists discovered a group of unicorns living in a remote, undeveloped valley in the Andes mountains; more surprisingly, these unicorns can speak fluent English,” where “the unicorns can speak fluent English” is absurd and entirely impossible in real life. However, the GPT system generated a story based on this sentence.

The story is beautifully written, but it contains errors. For instance, the first sentence is incorrect: “Scientists named them Ovid’s Unicorn based on their unique horns; these unicorns with silver horns were previously unseen by scientists.” This sentence itself is contradictory; how can unicorns have four horns? This is a clear logical error.Therefore, the common sense issue remains a very serious problem in machine translation.
So, which problems in natural language processing can be solved, and which cannot? This involves the issue of boundaries. I believe deep learning has several important boundaries: the data boundary, semantic boundary, symbolic boundary, and causal boundary.
Data Boundary
The data boundary is one of the constraints limiting the current development of machine translation technology. This is relatively easy to understand, as it refers to the lack of data, which current methods cannot resolve.
Semantic Boundary
Artificial intelligence has achieved great success in many fields, with the most significant successes in projects like Go and electronic sports. Even before deep learning and statistical methods, it was successful on the Winograd system. Why has it achieved such great success?
I believe this is because these fields can accurately model objective world problems, allowing them to perform well; whereas most current natural language processing systems cannot accurately model the objective world, making it difficult to perform well. Additionally, systems like smart speakers and voice assistant systems have achieved certain results largely because these systems correspond to well-defined tasks, allowing for modeling of the physical world. However, once users’ inquiries exceed these predefined tasks, the systems can easily make mistakes.
The success of machine translation is a relatively special case because the source and target languages have semantically precise correspondences; thus, as long as there is sufficient data, it can achieve good results without needing other support.
Currently, most natural language processing systems merely model the relationships between word symbols without modeling the semantics of the problems being described, i.e., without modeling the objective world. When people understand language, they form an image of the objective world in their minds and then use their language to describe what they want to say.
In fact, the ideal state of natural language processing should be able to describe and model the objective world. However, modeling the objective world is quite complex and not easy to achieve. For example, the property of color can be modeled using three 8-bit numbers, which can combine to produce millions of colors, but the words that describe colors only number in the dozens, and the correspondence between words and color models is difficult to describe accurately.
In the research of machine translation, modeling the objective world is not new; early ontologies, knowledge graphs, and semantic networks represent long-term efforts by human experts to establish universal models of the objective world. One of the significant achievements is the knowledge graph, but it has not yet been effectively applied to deep learning. However, I believe this is a direction worth exploring.
In summary, I believe an ideal improvement direction for natural language processing is to create world models or semantic models; in other words, not only to handle text processing but also to ground it in the real world, modeling the real world, and knowledge graphs are a specific direction worth exploring.
Symbolic Boundary
Psychologists divide human mental activities into the subconscious and consciousness. In my words, psychological activities that can be described using language are called consciousness, while those that cannot be described using language are called the subconscious.
Neural networks essentially exhibit subconscious behavior; they can input and output language expressions but cannot describe the entire reasoning and computation process, which is a significant flaw.
For example, using finite state automata, we can precisely define certain specific representations, such as numerals, years, URLs, etc., but even the best neural networks find it challenging to learn the expressive capabilities of finite state automata accurately. This is one reason many practical natural language processing systems still rely on symbolic rule methods.
Causal Boundary
Humans have a clear understanding of causal relationships in events occurring in the objective world. Therefore, it is easy to distill the essence of issues.
Neural networks cannot achieve this; they make judgments based on what they learn from data without understanding the true causal relationships, meaning they do not know which factors are the true causes of events and which are auxiliary judgments, making it easy to make erroneous judgments.
In fact, inferring true causal relationships solely based on statistical data is very difficult. True causal relationships can only be determined through carefully designed experiments. For example, determining the efficacy of a drug typically requires decades of experimentation by the US and Chinese drug authorities to establish a causal relationship, which is quite challenging.
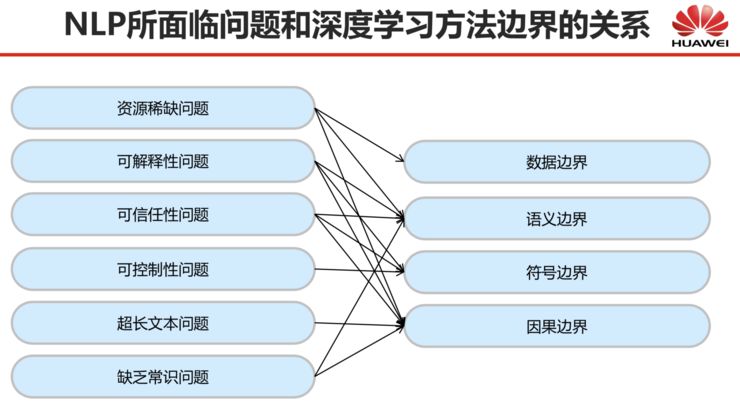
Today, I have discussed several issues that natural language processing based on deep learning still faces, and I believe these issues are ultimately caused by the four boundaries I mentioned earlier, and they are not caused by just one boundary but rather by the combined interference of multiple boundaries. To illustrate this, I will use a relationship diagram to describe this correspondence, as shown in the following image.
Audience Question: In the era of statistical machine translation, there were common tasks like word segmentation analysis, syntactic analysis, and semantic analysis. Are there similar common tasks in the neural network machine translation era?
Liu Qun: Clearly, there are.One is the pre-trained language model; it essentially processes language as a common task, and the significant success it has achieved is partly due to this processing approach.
The second is the knowledge graph; it is also a common task. The research in this field has been ongoing for many years and is very meaningful, so we are also considering ways to combine knowledge graphs with natural language processing for research.
Additionally, in voice dialogue systems like mobile assistants and smart speakers, this common task can also be reflected. For example, the multiple skills in the system, including controlling home appliances and playing music, can “conflict” if processed individually, so these issues need to be handled as common tasks, making it quite complex. Therefore, research on dialogue systems in this aspect of common tasks is quite worth exploring.
Thank you to Professor Liu Qun for reviewing and confirming the content of this article.

▎Breaking! High-level dialogue between Jack Ma and Elon Musk, Ma Huateng and Shen Xiangyang discuss AI: A complete overview of WAIC 2019
▎After merging with Alibaba Cloud, DingTalk repositions itself
New! “AI Investment Research Alliance” has launched complete videos and major theme white papers from the CCF GAIR 2019 summit, including cutting-edge robotics, intelligent transportation, smart cities, AI chips, AI finance, AI healthcare, and smart education. Members of the “AI Investment Research Alliance” can watch all summit videos and report content for free throughout the year. Scan to enter the membership page for more information, or message assistant Xiao Mu (WeChat: moocmm) for inquiries.