
HuggingGPT is a recent representative in the hot direction of Agents, enabling LLMs like ChatGPT to utilize various models from the HuggingFace community (including but not limited to text-to-image, image-to-text, speech-to-text, and text-to-speech), allowing LLMs to drive other intelligent agents for multimodal capabilities.
The original paper and Chinese introduction are as follows:
-
Original Paper
HuggingGPT:https://arxiv.org/abs/2303.17580
-
Chinese Introduction
Introduction to HuggingGPT
The working principle is shown in the figure below:
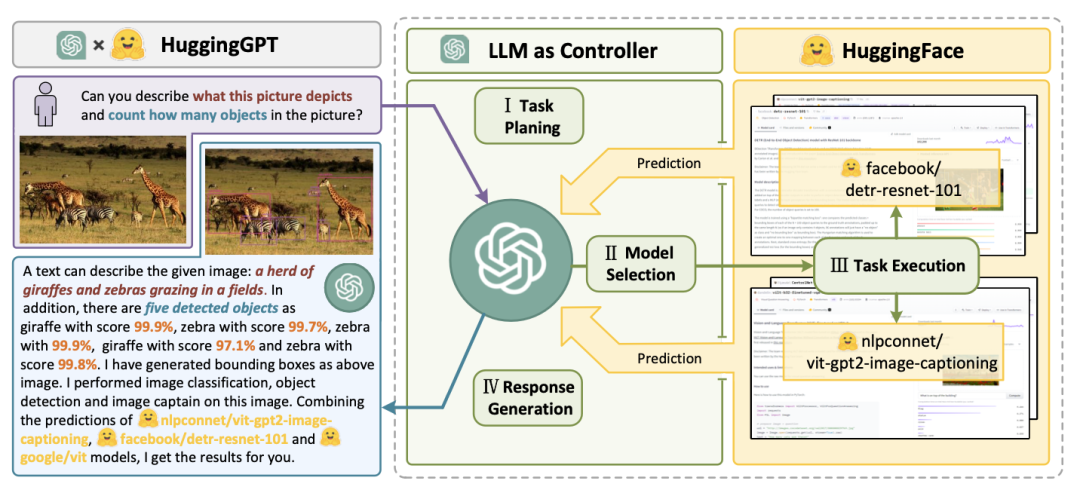
LLM acts as a controller to understand user needs and then, in conjunction with HuggingFace community models, decomposes user tasks into four steps: Task Planning, Model Selection, Task Execution, and Response Generation. This is a relatively complex workflow, and a typical task execution process is shown below:

During the reading of the original text, I found that the Prompt design of HuggingGPT is also quite “hard-core”; although expressed in natural language, it is filled with intricate engineering design thoughts. Let’s analyze the entire process filled with craftsmanship in the Prompt.
Step 1: Task Planning
In this stage, ChatGPT analyzes user requests, understands their intentions, and decomposes them into solvable sub-tasks. So, what does its Prompt look like?
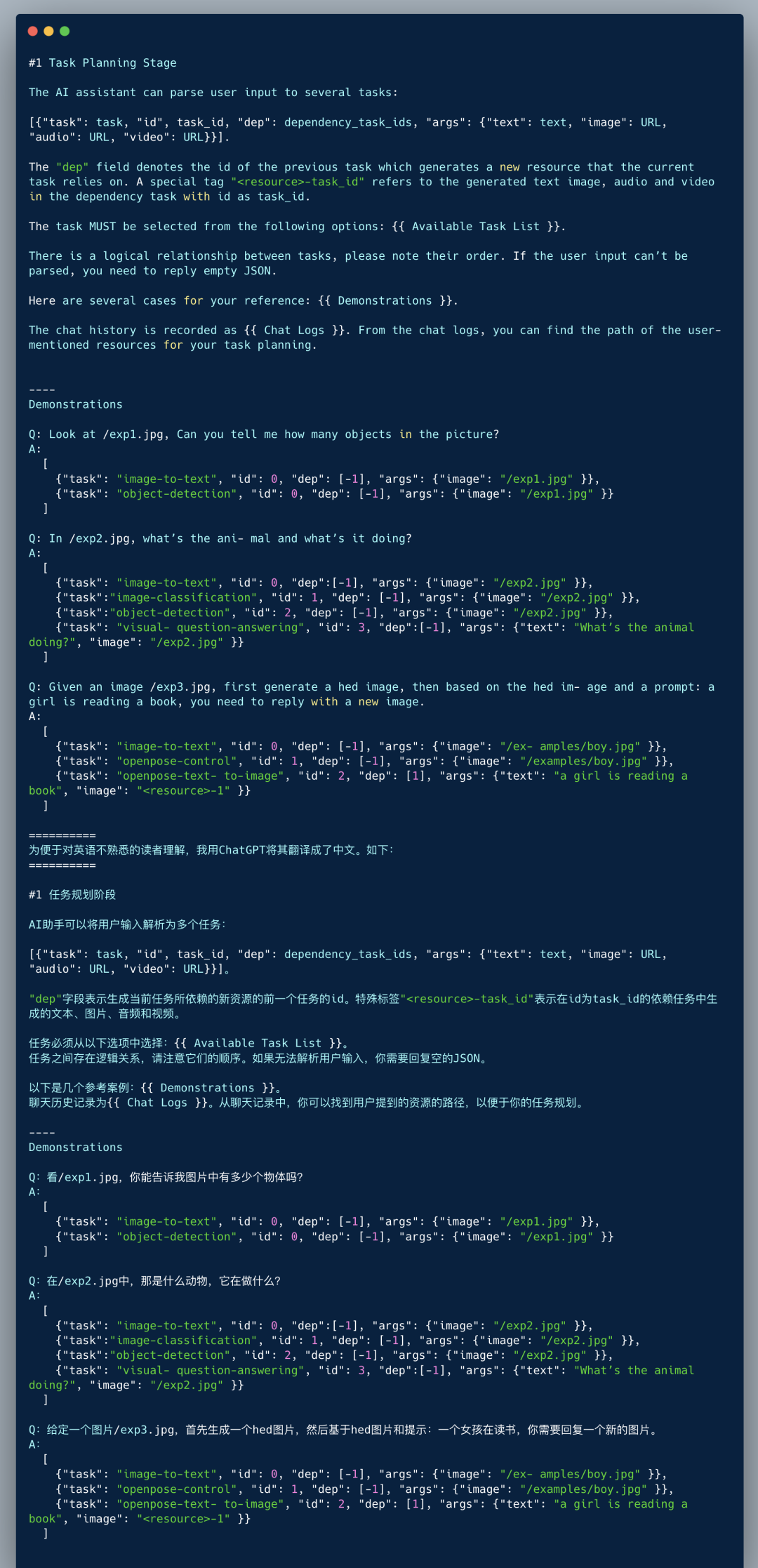
In the above Prompt design, HuggingGPT comprehensively uses “specification-based instruction” and “demonstration-based parsing” methods.
“Specification-based instruction” refers to the normative constraints on the Task, which must follow the format below, containing four elements: task content (task), task id (id), task dependencies (dep), and parameters (args):
[{“task”: task, “id”: task_id, “dep”: dependency_task_ids, “args”: {“text”: text, “image”: URL, “audio”: URL, “video”: URL}}]
This design, on a superficial level, is a requirement for the format of the output during the task decomposition process; on a deeper level, it is a system design for model scheduling, reflecting a profound understanding of how the entire system operates. Particularly, the dep and args here, from a programmer’s perspective, are typical system interface designs.
During the training process, the large model has undergone instruction fine-tuning and reinforcement learning based on human feedback, already possessing a certain level of instruction compliance capability. To further help it understand what to do, the Prompt provides several “examples” (Demonstrations). This will stimulate the large model’s in-context learning or few-shot learning ability, resulting in better understanding and generation. This is what is referred to as demonstration-based parsing in the article.
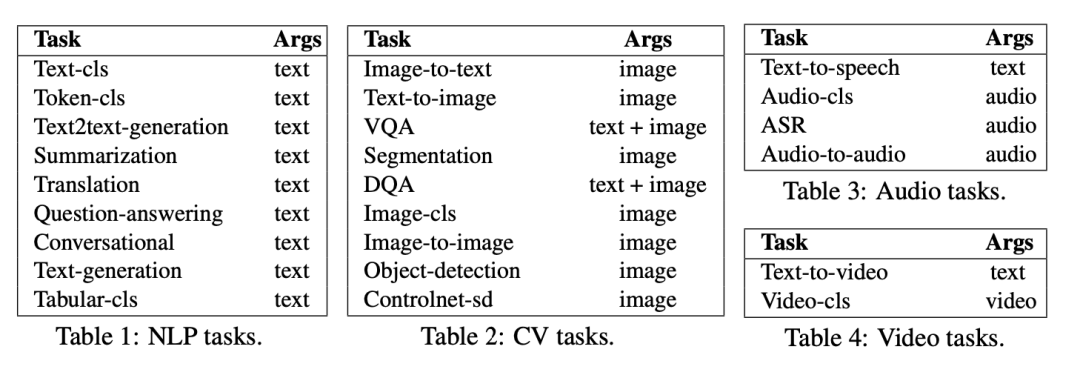
In addition, the Prompt also provides the LLM with an Available Task List and Chat Logs, offering the large model a list of available HuggingFace models and conversation history, providing more accurate contextual information. The Available Task List should include various types of tasks related to natural language processing, computer vision, speech, and video:
Step 2: Model Selection
To run the sub-tasks planned in Step 1, ChatGPT needs to select an appropriate model from those hosted on HuggingFace. The Prompt for this stage is as follows:
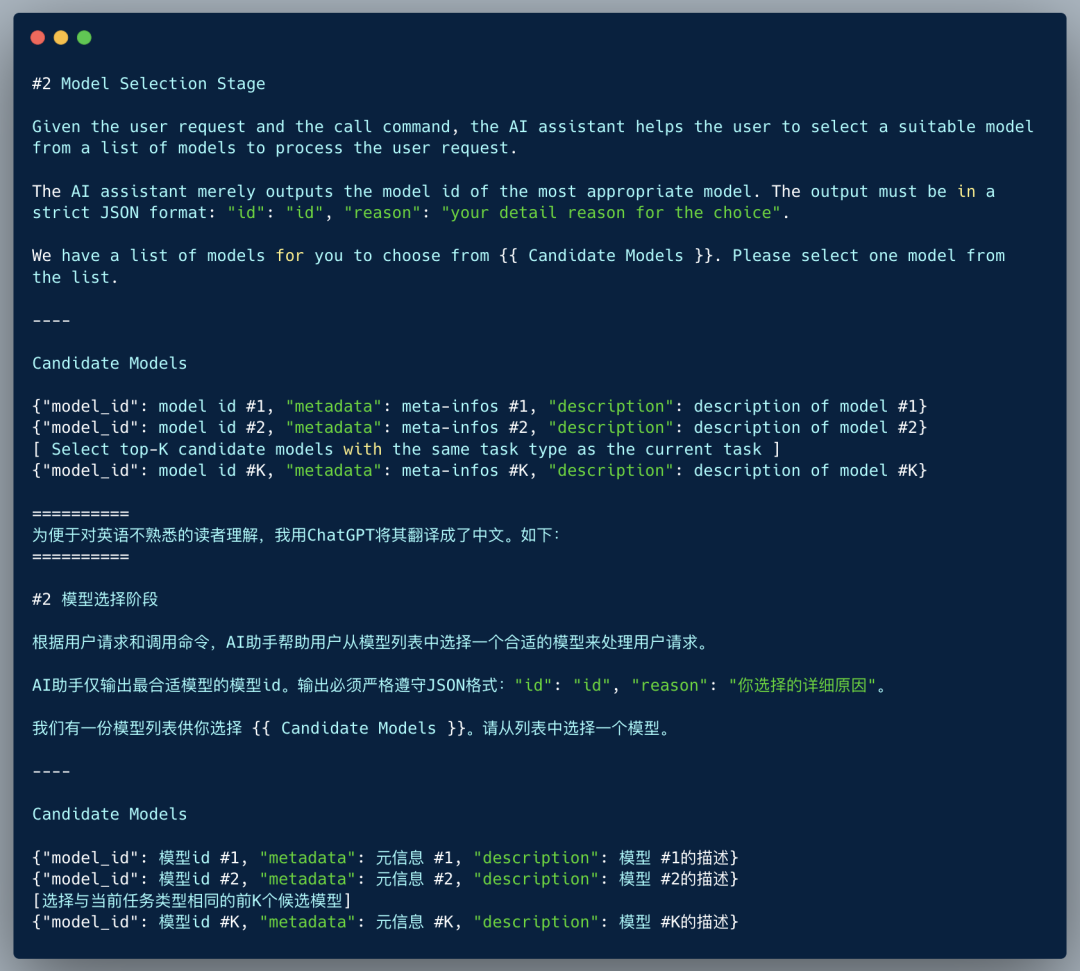
The Prompt at this stage is straightforward, but like the first stage, it provides the LLM with clear information about the “Candidate Models”.However, the data for this “Candidate Models” is not static; it undergoes detailed processing, which includes:
-
Model Description Acquisition. Information about each model’s functionality, architecture, domain, license, etc., needs to be obtained from the HuggingFace website to feed into the LLM for model selection.
-
Model Initial Screening. Due to length limitations in the Prompt, not all model descriptions from the HuggingFace community can be included, so an initial screening of models is necessary. The first condition for initial screening is the task type, where the task field from Step 1 indicates the task category, such as “image-to-text”. This task category can be matched with the functionality or classification in the model descriptions to obtain all model descriptions under that task type. The following figure shows the number of models corresponding to different Tasks on the HuggingFace official website.
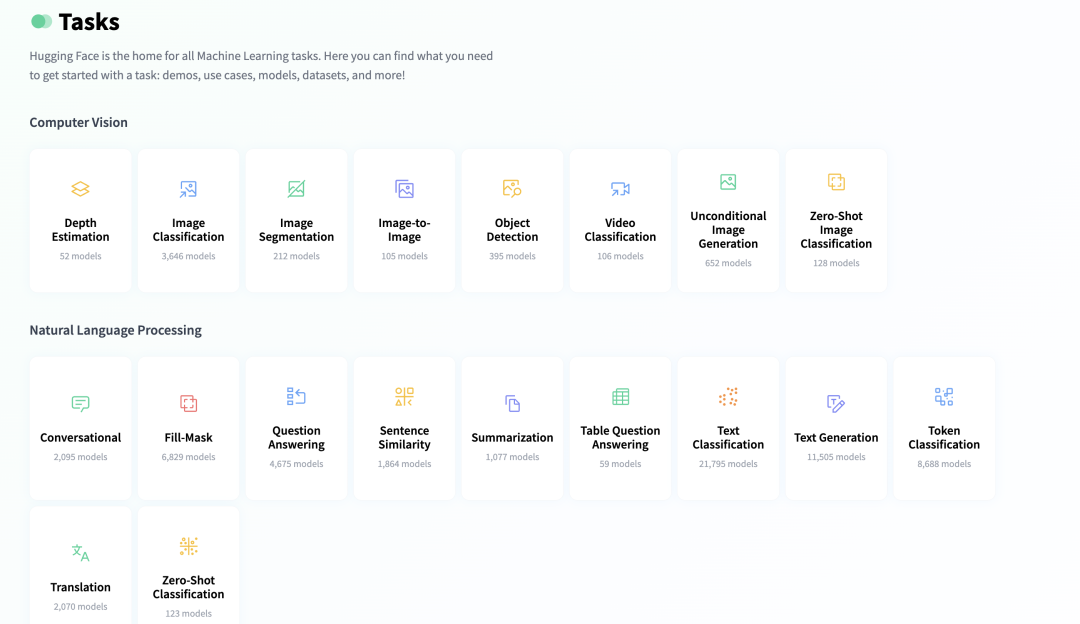
-
Model Fine Screening. After the initial screening, there may still be many models. For example, there are over 10,000 text generation models, and since the token limit for gpt-3.5-turbo is 4096, it is impossible to include all model descriptions in this category. Therefore, further fine screening is needed. The article mentions that this is achieved by selecting the TopN based on the number of downloads, as download volume largely reflects the quality and popularity of a model, which can serve as a standard for further screening.
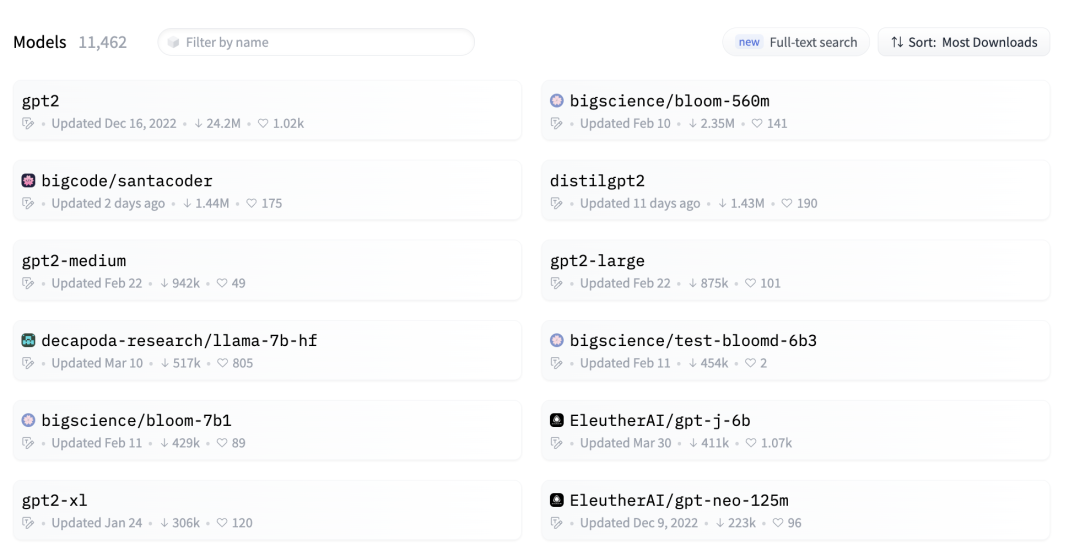
After fine screening, the model descriptions can be placed in a Prompt to provide the large model with contextual learning, thus selecting the appropriate model.
From the above process, it can be seen that this greatly reflects the engineering aspect of Prompt Engineering. To obtain the final executing Prompt, many constraints are considered, and programming is used to dynamically generate the Prompt.
Step 3: Task Execution
Task execution involves invoking the selected model, executing algorithms, and finally returning results to ChatGPT. This process is not executed by the LLM, so no Prompt design is needed.
Step 4: Response Generation
Finally, ChatGPT gathers the results from various models and generates an answer for the user. The Prompt for this process is:
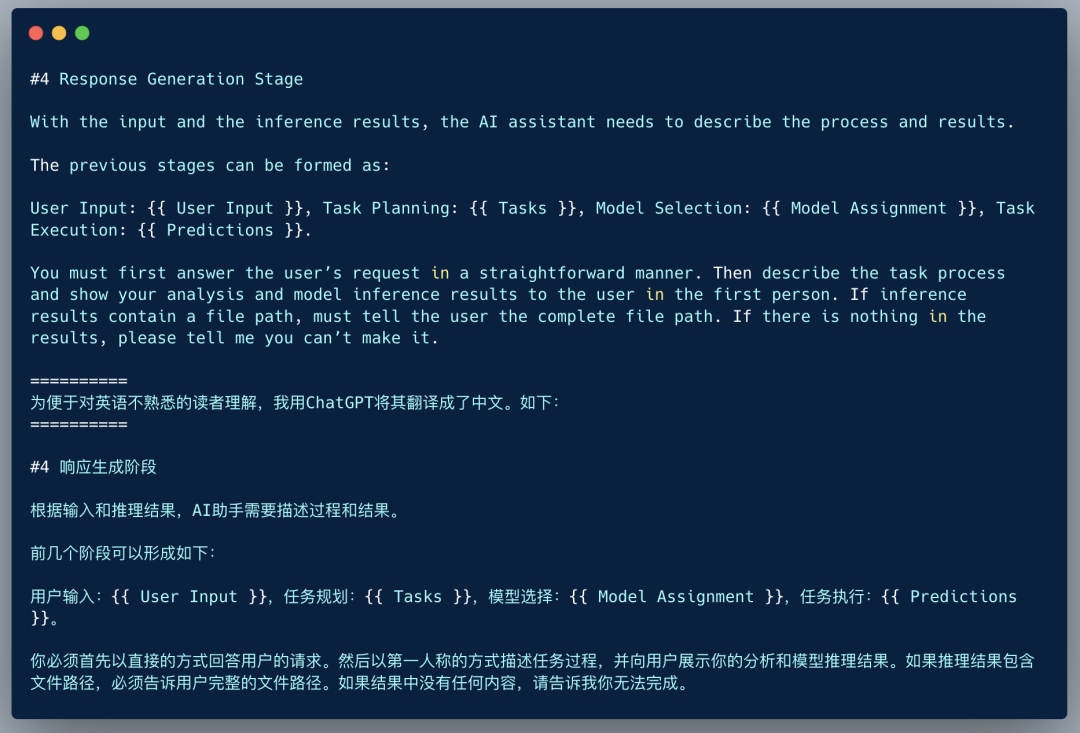
Let’s enjoy another example (more examples can be found in the original paper):
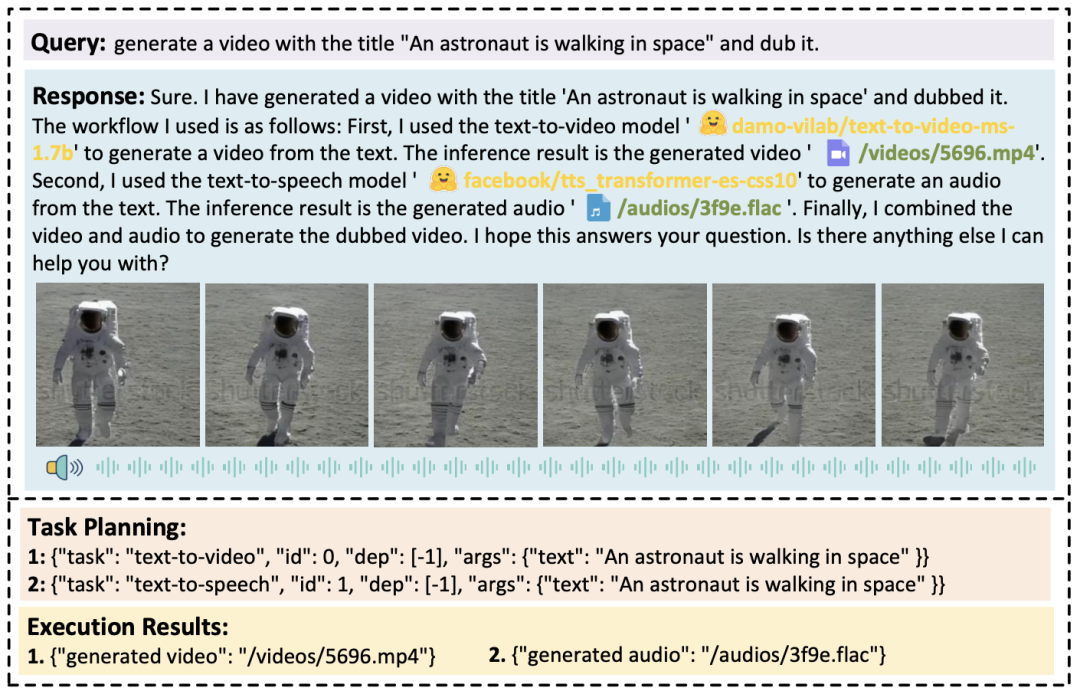
Conclusion
The entire HuggingGPT’s very “hard-core” Prompt design effectively illustrates the “engineering” in Prompt Engineering. It includes the following aspects:
-
Prompt Flow Design. HuggingGPT is not a single task node but a workflow divided into four steps. Therefore, it cannot be resolved with just one Prompt; multiple Prompts need to be designed to support the entire workflow. In addition to designing each step’s Prompt, the connection between different task nodes must also be well-designed.
-
Dynamic Prompt Generation. In Step 2, “Model Selection”, the Prompt is dynamically generated, where the “Candidate Models” part is obtained through a series of processes including model description acquisition, initial screening, and fine screening. This process involves system design and programming implementation, similar to traditional software development, where SQL statements for querying and modifying data are dynamically generated through a large but sophisticated engineering process.
-
Static Techniques in Prompts. In Task 1, “Task Planning”, the Prompt is static, utilizing commonly used Prompt techniques such as “specification-based instruction” and “demonstration-based parsing”. Each dynamic Prompt given to the LLM can also be seen as a static Prompt, so how to make the Prompt more expressive can integrate various techniques mentioned in our previous articles. References include:
Exploring Hard-Core Prompts: The “Contract” with Auto-GPT
AI Daily @20230413: Prompt Engineering 02 – Principles
AI Daily @20230412: Prompt Engineering