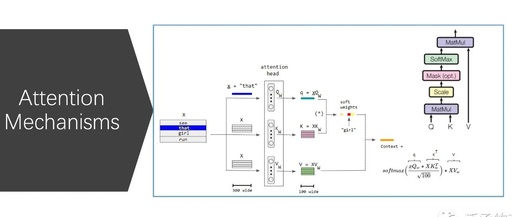
Attention Mechanisms have become the foundational architecture for model design; it’s almost a given that a good model should incorporate some form of attention.
This article summarizes the current state of Attention Mechanisms by introducing 17 mainstream types of attention mechanisms, explaining their basic principles and computational methods, and providing their sources along with corresponding code for further reading:
-
Dot-product Attention -
Scaled Dot-product Attention -
Strided Attention -
Residual Attention Network (RAN) -
Additive Attention -
Channel Attention -
Sliding Window Attention -
Class Attention -
Location-based Attention -
Attention Gate -
Bottleneck Attention -
Neighborhood Attention -
Bilinear Attention -
Routing Attention -
Cross-covariance Attention -
Relation-aware Global Attention -
Locally-grouped Self-attention
For those who want to quickly understand the basic principles of Attention Mechanisms, you can refer to previous articles:
-
Introduction to Attention Mechanisms -
In-depth Look at Attention Mechanisms -
This is the Structure of Transformers
1. Dot-product Attention
Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
https://arxiv.org/pdf/1508.04025v5.pdf
Dot-Product Attention is the most common type of attention mechanism, initially applied in Encoder-Decoder models, with the calculation formula as follows:
Where hencoder represents the hidden states of the Encoder, and hdecoder represents the hidden states of the Decoder. Then, softmax is used to compute the final attention weights.
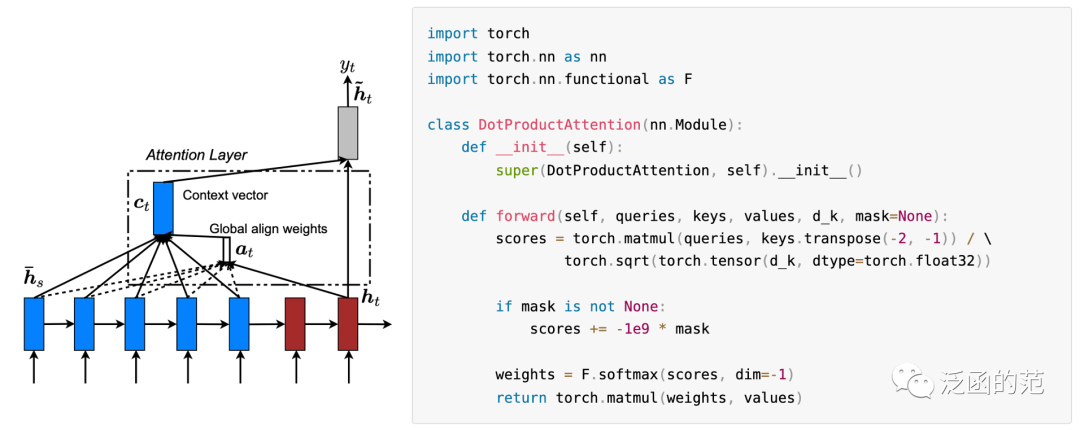
2. Scaled Dot-product Attention
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
https://arxiv.org/pdf/1706.03762v7.pdf
Scaled dot-product attention is commonly used in Transformer models, especially in self-attention mechanisms. The specific attention calculation formula is as follows:
Where Q represents the query vector, K represents the key vector, and V represents the value vector associated with each key. The dot product of Q and K is divided by √dk, and then the softmax function is applied to obtain the attention weights. Finally, the attention weights are multiplied element-wise with the value vector V to produce the weighted sum output, which represents the output after the attention mechanism.
The purpose of scaling the dot product by √dk is to control the size of the attention weights.
Assuming that the components of q and k are independent random variables with a mean of 0 and a variance of 1, the mean of their dot product is 0, and the variance is dk. When dk is large, the values of the dot product are usually large, which may cause the gradients to explode during backpropagation. Dividing by √dk ensures that the variance of the dot product is 1, helping to balance its influence in the attention calculation.

3. Strided Attention
Child R, Gray S, Radford A, et al. Generating long sequences with sparse transformers[J]. arXiv preprint arXiv:1904.10509, 2019.
https://arxiv.org/pdf/1904.10509v1.pdf
Strided Attention was proposed in the sparse Transformer structure, where one head attends to previous positions, and the other head attends to every stride position (usually set to a fixed value).
The self-attention layer maps the input embedding matrix to the output matrix, where i indicates the set of input vectors that the i-th output vector attends to. The output vector is a weighted sum of the input vectors:
Where Wq, Wk, and Wv represent the weight matrices that transform the given input into query, key, and value, respectively, with dk being the dimension of the query and key vectors. The output at each position is the weighted sum of values, with weights determined by the scaled dot product of the key and query.
For autoregressive models, self-attention is defined such that each element can only attend to all previous positions and its own position.
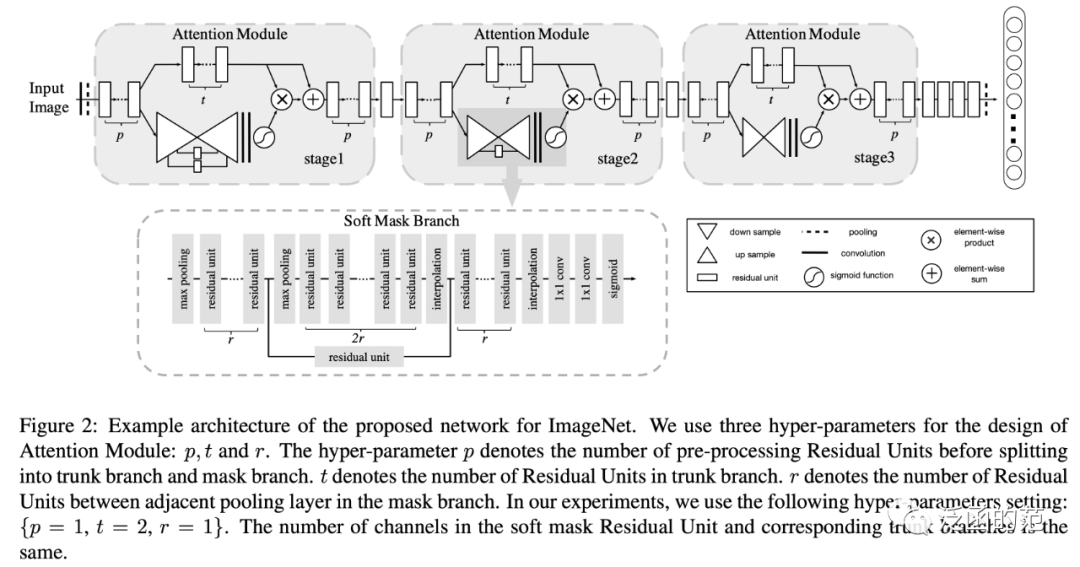
4. Residual Attention Network (RAN)
Wang F, Jiang M, Qian C, et al. Residual attention network for image classification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 3156-3164.
https://arxiv.org/pdf/1704.06904v1.pdf
Inspired by the success of ResNet, Wang et al. combined the attention mechanism with residual connections to propose a very deep convolutional residual attention network (RAN).
In RAN, each attention module can be divided into a masking branch and a trunk branch. The trunk branch processes features and can utilize any state-of-the-art structure (such as pre-activation residual units, Inception, etc.). The masking branch uses a bottom-up and top-down structure to learn a mask of the same size as the output of the trunk branch, which is used for soft weighting of the output features. After two convolutional layers, a sigmoid layer is used to normalize the output to the range [0, 1]. RAN can be represented as:
Where fbottom-up is the bottom-up structure, which uses max-pooling multiple times after the residual unit to increase the receptive field, while ftop-down uses linear interpolation to maintain the size of the output feature map the same as the input. Additionally, there is a skip connection between the two parts (omitted in the formula). The trunk branch can be any structure.
Within each attention module, the bottom-up and top-down feedforward structures model spatial and cross-channel dependencies. RAN can be applied in an end-to-end training manner to any deep network structure. However, this bottom-up and top-down structure fails to utilize global spatial information. Moreover, directly predicting 3D attention is computationally expensive.
For detailed code, see: https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch.git
5. Additive Attention
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
https://arxiv.org/pdf/1409.0473.pdf
Additive Attention, also known as Bahdanau Attention, uses a single hidden layer feedforward neural network to compute attention scores:
Where α and β are the attention parameters. hencoder represents the hidden states of the Encoder, and hdecoder represents the hidden states of the Decoder. We can use the softmax values of the above formula to represent the correlation between source and target language words:

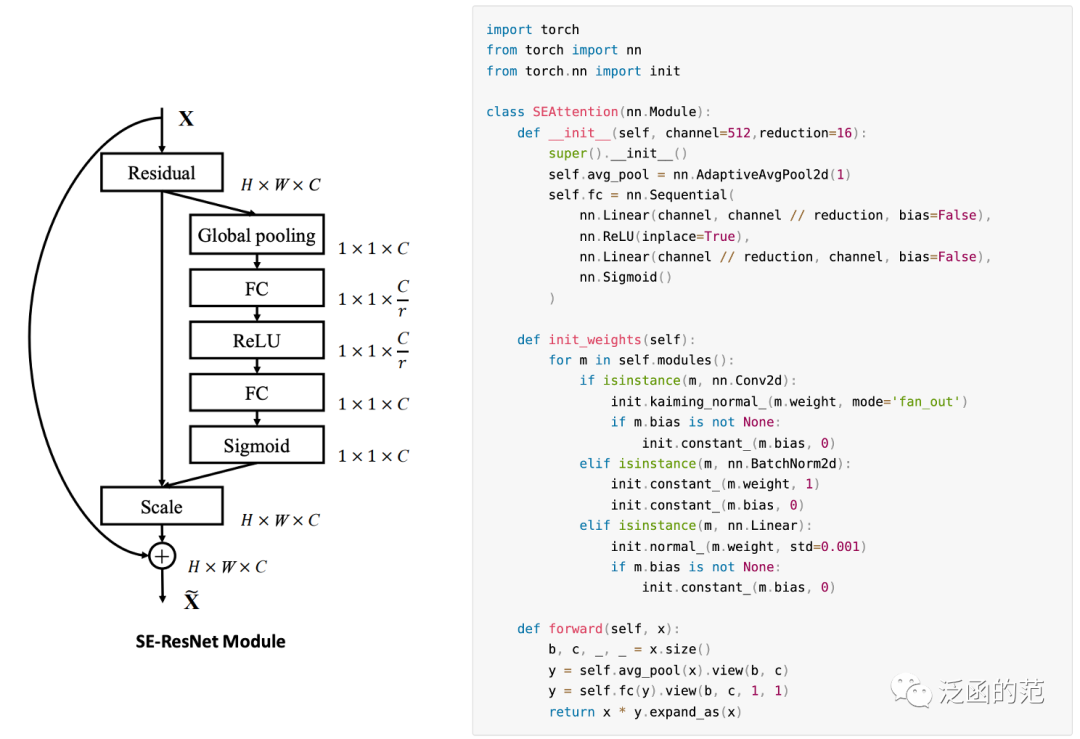
6. Channel Attention
Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
https://arxiv.org/pdf/1709.01507v4.pdf
Channel Attention was first proposed by SENet. The core of SENet is a Squeeze-and-Excitation (SE) module, which collects global information, captures inter-channel relationships, and enhances representational power. The SE module consists of two parts: the Squeeze module and the Excitation module. The Squeeze module collects global spatial information through Global Average Pooling. The Excitation module captures inter-channel relationships using fully connected layers and non-linear layers (ReLU and sigmoid) to output an attention vector. Each channel of the input features is scaled by multiplying it with the corresponding element of the attention vector. The SE module, which takes input X and produces output Y, can be represented as:
Where W1 and W2 are weight matrices, ReLU is the non-linear activation function, sigmoid is the activation function, and GAP represents the Global Average Pooling operation.
7. Sliding Window Attention
Beltagy I, Peters M E, Cohan A. Longformer: The long-document transformer[J]. arXiv preprint arXiv:2004.05150, 2020.
https://arxiv.org/pdf/2004.05150.pdf
Sliding Window Attention was initially proposed as part of the Longformer architecture. Its motivation is based on the time and space complexity of the non-sparse attention in the original Transformer, which is not suitable for handling long inputs. Considering the importance of local context, Sliding Window Attention uses a fixed-size window of attention around each token. Using multiple stacked windowed attention layers can achieve a larger receptive field, allowing the top layer to access all input positions and integrate information from the entire input.
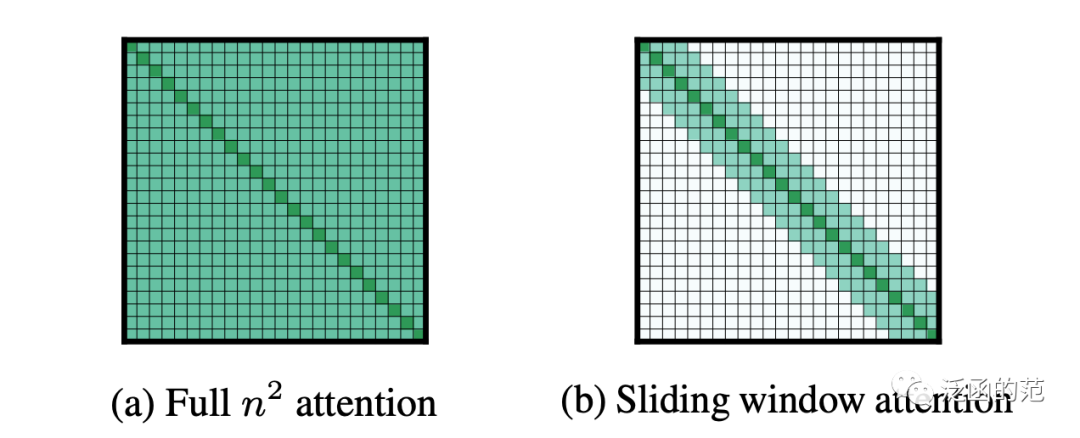
Specifically, given a fixed window size, each token participates in attention calculations for k tokens on each side. The computational complexity of this model is O(n), which is linearly related to the length of the input sequence, in most cases. Similar to how stacked small kernels in CNNs generate high-level features constructed from most of the input (receptive field), models with multiple stacked Transformers will have a larger receptive field.
In this case, for a L-layer Transformer, the size of the receptive field is O(L) (assuming all layers have the same fixed size). In practical applications, different values can be used for each layer to balance efficiency and model representation capability.
For detailed code, see: https://github.com/allenai/longformer.git
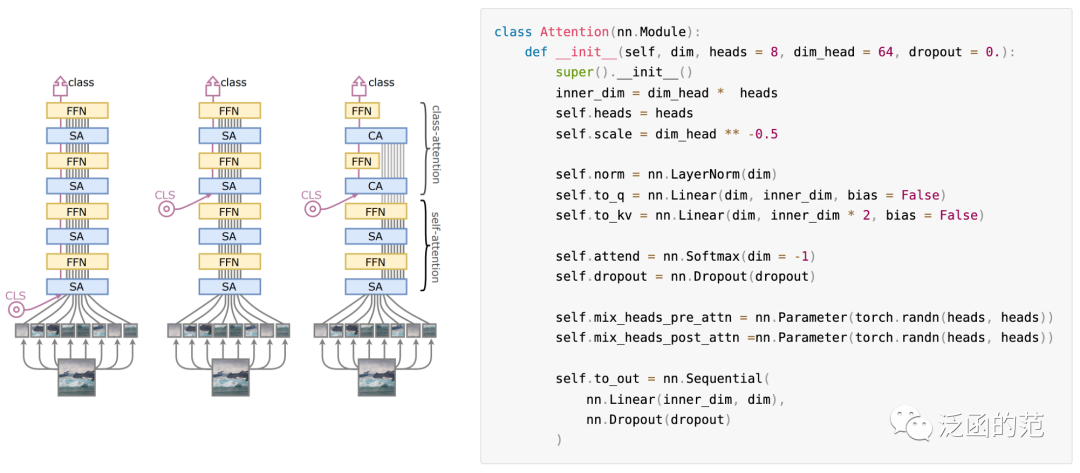
8. Class Attention
Touvron H, Cord M, Sablayrolles A, et al. Going deeper with image transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 32-42.
https://arxiv.org/pdf/2103.17239v2.pdf
Class Attention (CA) is the attention mechanism used in CaiT for visual Transformers, aimed at extracting information from a set of processed patches. It is identical to the self-attention layer but relies on the following attention relationships:
-
i) Class embeddings (initialized as CLS in the first CA) -
ii) Attention between itself and a set of frozen patch embeddings.
Consider a network with h attention heads and p patches, and let d represent the size of the embedding dimension. Multi-head Class Attention uses multiple projection matrices for parameterization, i.e., W1 and W2, with corresponding biases. The computation process of the CA residual block is as follows. First, the patch embeddings (in matrix form) are expanded to h. Then, projection calculations are performed:
The calculation of Class-attention weights is as follows:
Where α is the attention weight. The attention calculation participates in the weighted sum to generate the residual output vector:
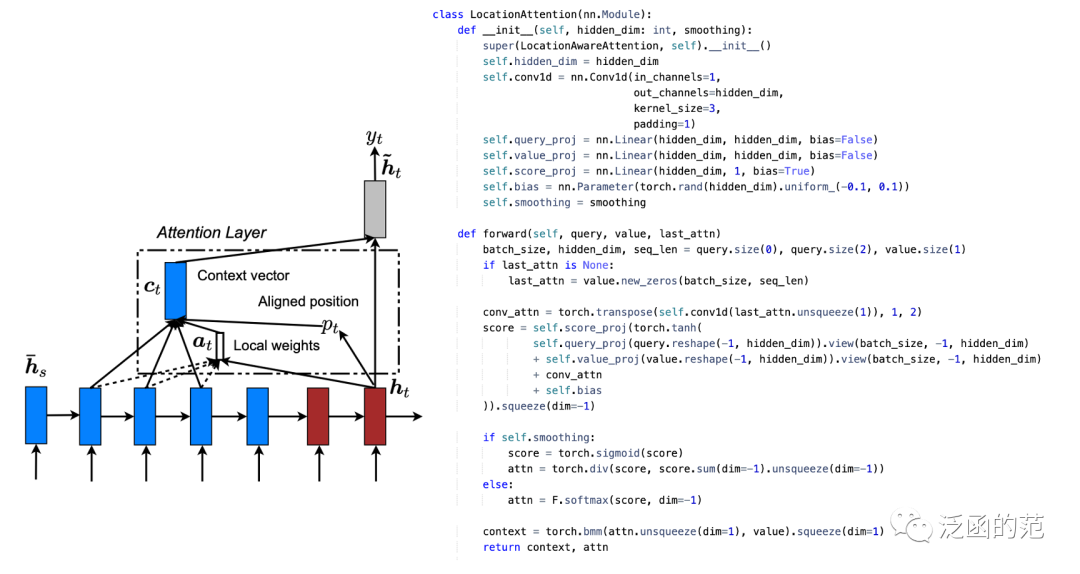
9. Location-based Attention
Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
https://arxiv.org/pdf/1508.04025
Location-based Attention is calculated solely from the target hidden states, computed as follows:
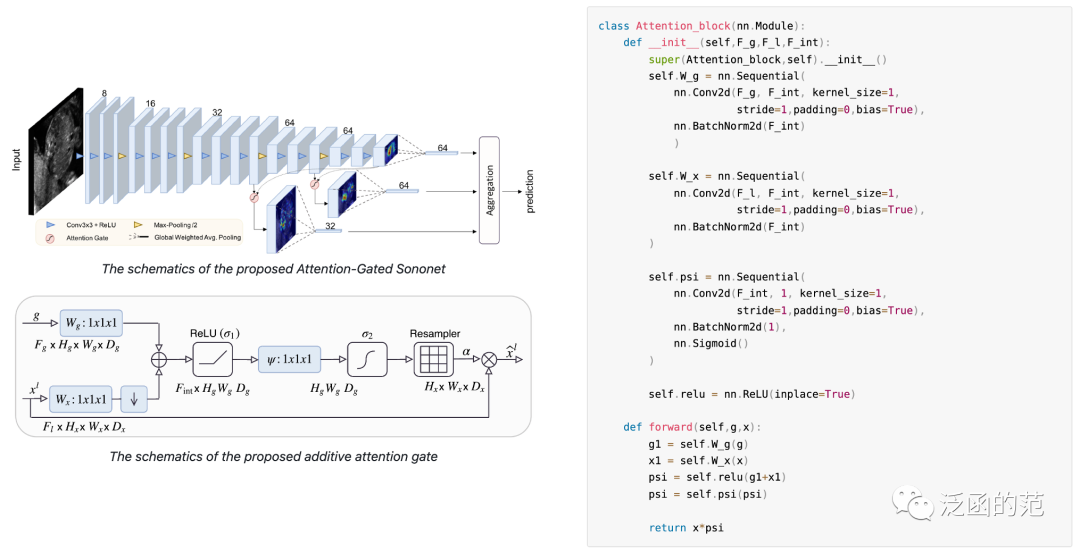
10. Attention Gate
Oktay O, Schlemper J, Folgoc L L, et al. Attention u-net: Learning where to look for the pancreas[J]. arXiv preprint arXiv:1804.03999, 2018.
https://arxiv.org/pdf/1804.03999.pdf
The purpose of the Attention Gate is to focus attention on the target area while suppressing feature activations unrelated to the target. Given input and gating signals, the gating signal collects context information in a coarse manner, and the Attention Gate uses Additive Attention to obtain gating coefficients. The input and gating signals are first mapped linearly to a space of dimension c, and then compressed along the channel dimension to generate a spatial attention weight map. The entire process can be represented as:
Where W1, W2, and W3 are linear transformations achieved through convolution.
The Attention Gate directs the model’s attention to important areas while suppressing feature activations unrelated to the target. Due to its lightweight design, it significantly enhances the model’s representational capability without substantially increasing computational cost and model parameters. It is versatile and modular, making it easy to apply to various CNN models.
11. Bottleneck Attention
Park J, Woo S, Lee J Y, et al. Bam: Bottleneck attention module[J]. arXiv preprint arXiv:1807.06514, 2018.
https://arxiv.org/pdf/1807.06514.pdf
The Bottleneck Attention Module (BAM) was proposed by Park et al. to effectively enhance the representational capability of networks. BAM uses Dilated Convolution to expand the receptive field of the spatial attention submodule while adopting a bottleneck structure to save computational cost.
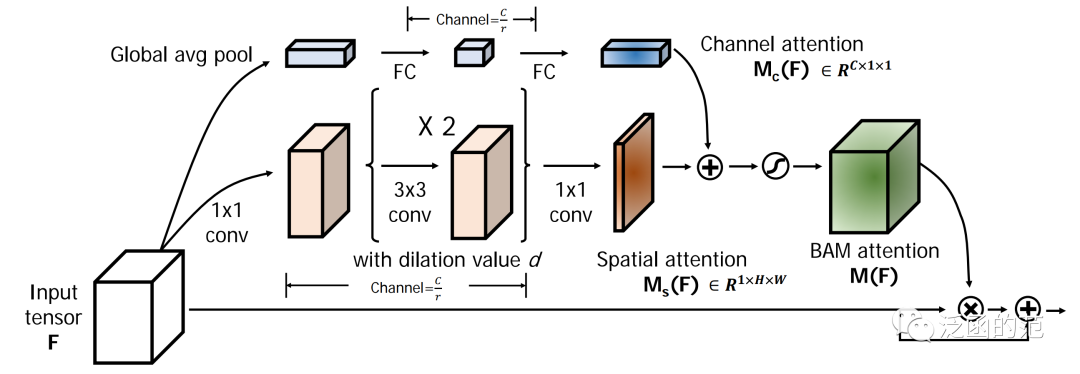
For a given input, BAM calculates channel attention and spatial attention in two parallel branches; then, the two attentions are summed while resizing the outputs of both branches to H. The channel attention branch is similar to the previously mentioned SE block, aggregating global information through Global Average pooling, followed by MLP for channel reduction. To effectively utilize contextual information, the spatial attention branch combines the bottleneck structure with Dilated Convolution. Overall, BAM can be represented as:
Where Wfc and bfc are the weights and biases of the fully connected layer, and Wconv is the convolutional layer used for channel reduction. The Dilated Convolution used effectively utilizes contextual information. The attention maps are expanded to H.
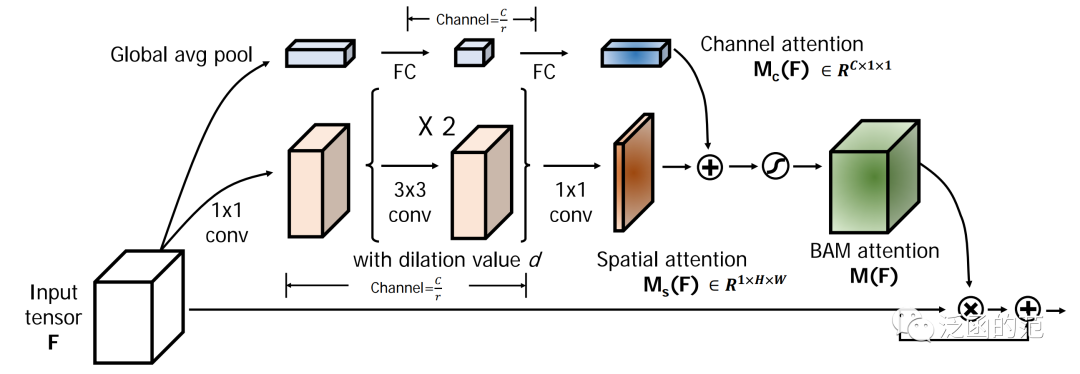
BAM can emphasize or suppress features in both spatial and channel dimensions while enhancing representational capability. The dimensional reductions performed on both channel and spatial attention branches allow it to integrate with any convolutional neural network with minimal additional computational cost. However, while dilated convolutions effectively expand the receptive field, they still fail to capture long-range contextual information and cannot encode cross-domain relationships.
For detailed code, see: https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/BAM.py
12. Neighborhood Attention
Hassani A, Walton S, Li J, et al. Neighborhood attention transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 6185-6194.
https://arxiv.org/pdf/2204.07143v5.pdf
Neighborhood Attention is a type of Restricted Self-Attention, where each token’s receptive field is limited to its nearest neighboring pixels. It is mainly used to replace other local attention mechanisms used in hierarchical visual Transformers.

Neighborhood Attention is conceptually similar to Stand Alone Self-Attention (SASA), both can be implemented by performing a sliding window operation on the <key, value> pairs.
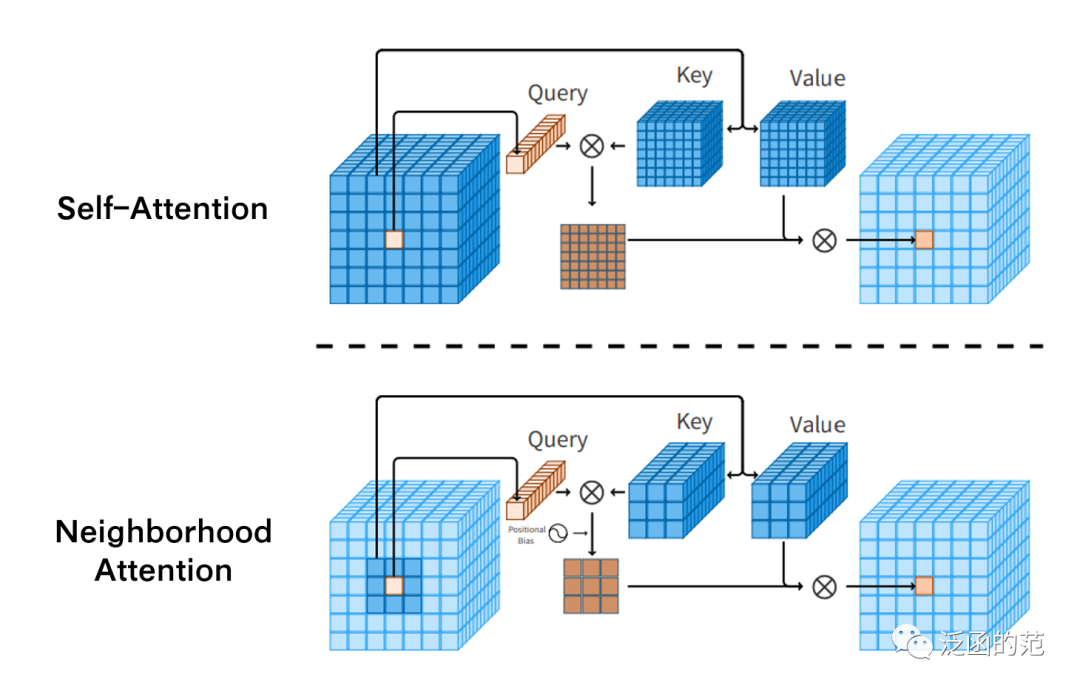
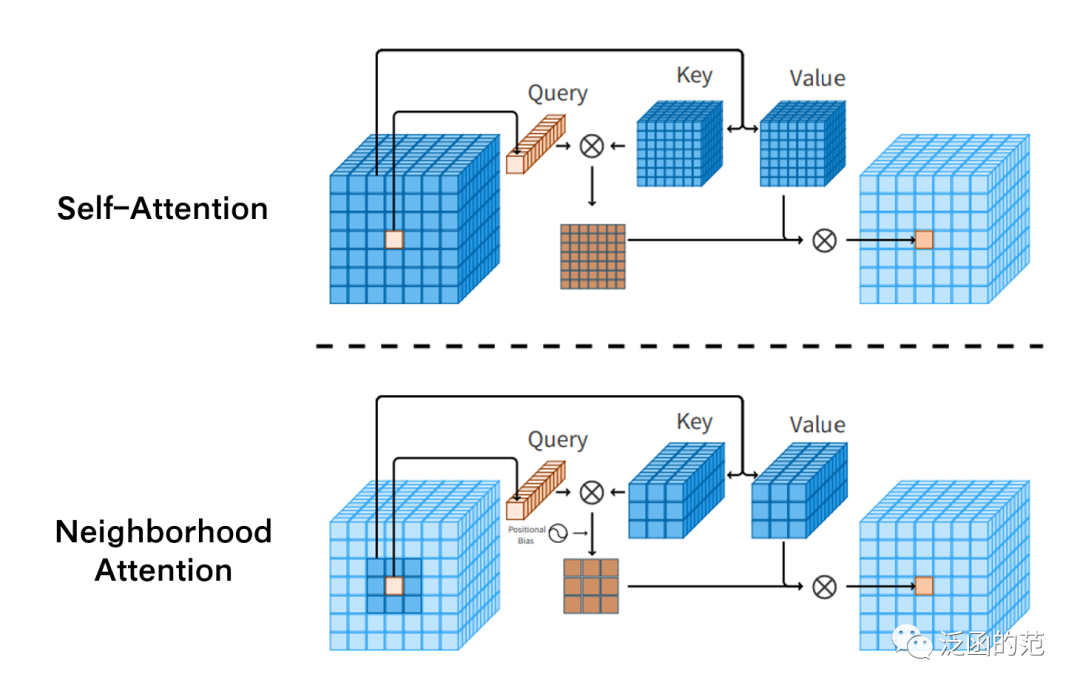
When experimenting with Neighborhood Attention and SASA, the main issues are computational. Extracting key-value operations for each query not only slows down computation but also consumes a lot of memory, making it difficult to apply to large-scale problems.
For detailed code, see: https://github.com/SHI-Labs/Neighborhood-Attention-Transformer.git
13. Bilinear Attention
Fang P, Zhou J, Roy S K, et al. Bilinear attention networks for person retrieval[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 8030-8039.
https://openaccess.thecvf.com/content_ICCV_2019/papers/Fang_Bilinear_Attention_Networks_for_Person_Retrieval_ICCV_2019_paper.pdf
Bilinear Attention (Bi-Attention) employs the Attention-in-Attention (AiA) mechanism to capture second-order statistical information: the external channel attention vector is computed from the output of the internal channel attention.
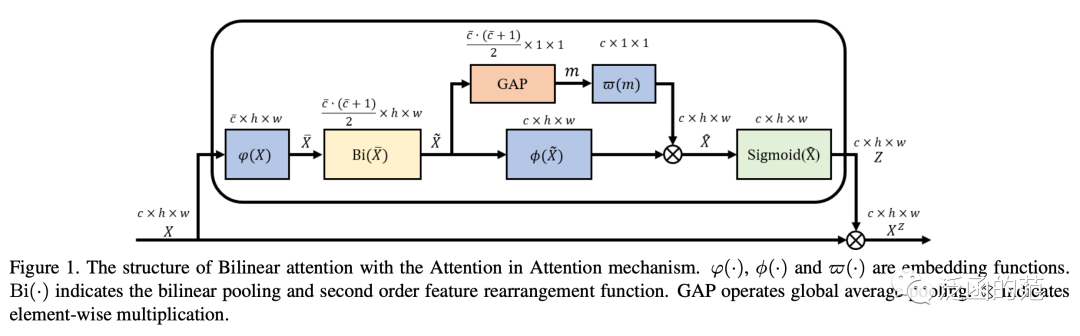
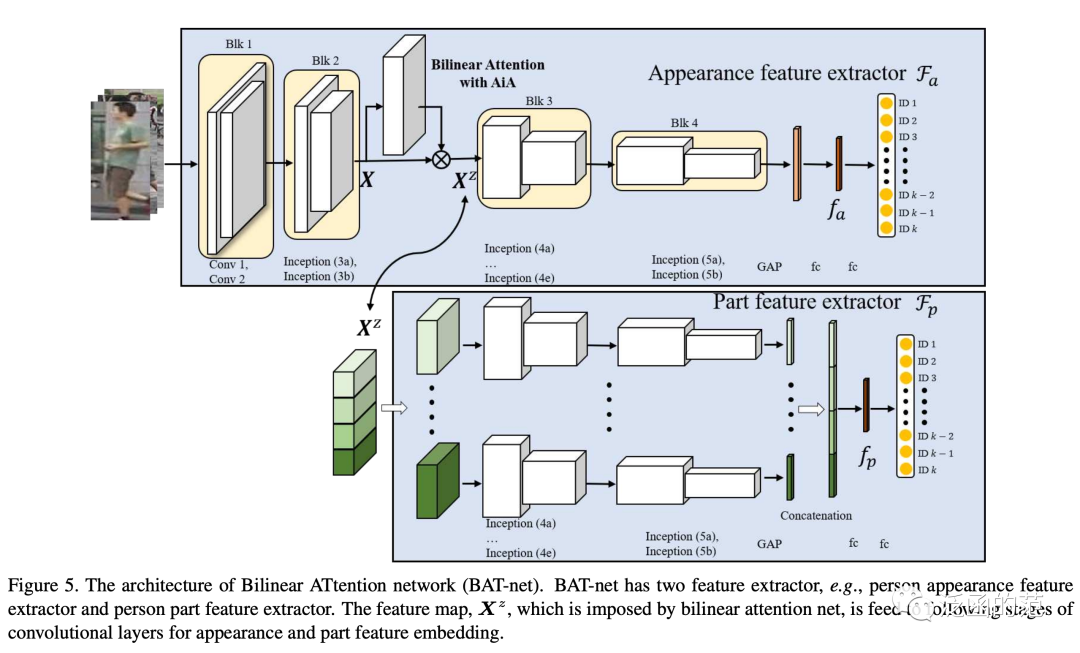
14. Routing Attention
Roy A, Saffar M, Vaswani A, et al. Efficient content-based sparse attention with routing transformers[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 53-68.
https://arxiv.org/pdf/2003.05997v5.pdf
Routed Attention is an attention pattern proposed in the Routing Transformer architecture. Each attention module considers spatial clustering: the current timestep attends only to the context belonging to the same cluster. That is, the query of the current timestep is routed to a limited number of contexts through its clustering.
As shown in the figure, the rows represent outputs, and the columns represent inputs. Different colors indicate the clustering relationships of output tokens.
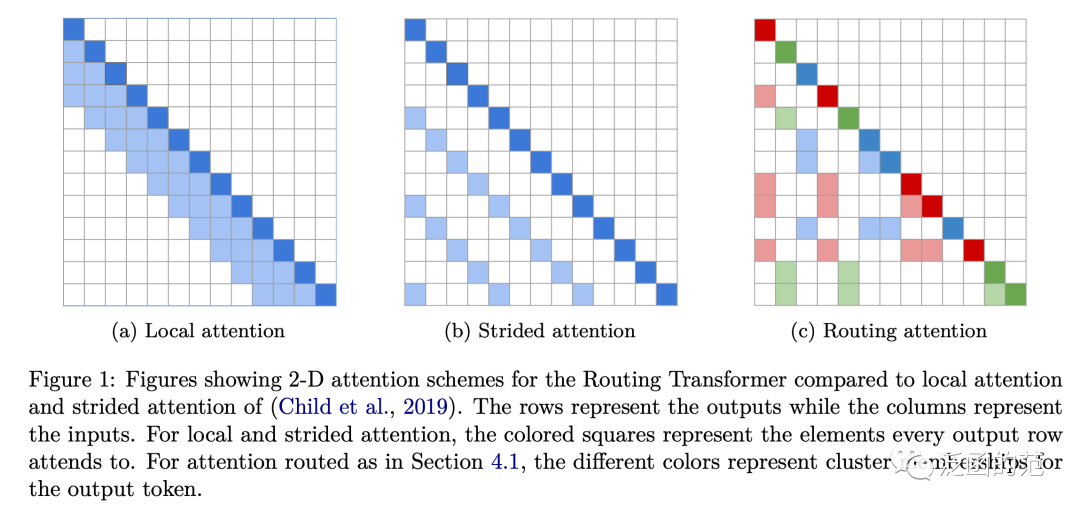
For detailed code, see: https://github.com/lucidrains/routing-transformer.git
15. Cross-covariance Attention
Ali A, Touvron H, Caron M, et al. Xcit: Cross-covariance image transformers[J]. Advances in neural information processing systems, 2021, 34: 20014-20027.
https://arxiv.org/pdf/2106.09681v2.pdf
Unlike traditional Transformers that operate on the token dimension, Cross-Covariance Attention (XCA) operates on the feature dimension.
Using traditional attention symbols for query (Q), key (K), and value (V), XCA is defined as follows:
Where the embedding of each output token corresponds to a convex combination of the features of k tokens in V. The attention weights are calculated based on the cross-covariance matrix. Additionally, the authors normalize the query and key matrices to limit their magnitudes, ensuring that each column of the normalized matrix is a unit vector of length d, and each element in the cross-covariance matrix is within a range.
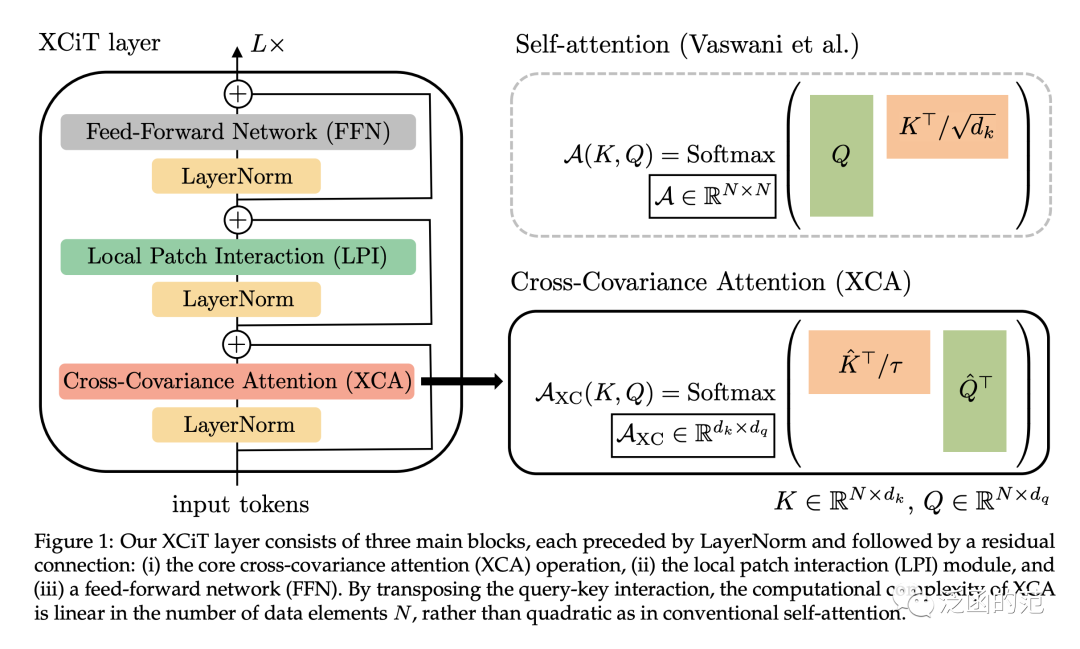
For detailed code, see: https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/xcit.py
16. Relation-aware Global Attention
Zhang Z, Lan C, Zeng W, et al. Relation-aware global attention for person re-identification[C]//Proceedings of the ieee/cvf conference on computer vision and pattern recognition. 2020: 3186-3195.
https://arxiv.org/pdf/1904.02998v2.pdf
Relation-aware Global Attention (RGA) emphasizes the importance of global structural information provided by pairwise relationships and computes attention maps accordingly.
RGA has two forms: spatial RGA (RGA-S) and channel RGA (RGA-C).
RGA-S first reshapes the input to H, and obtains the pairwise relationship matrix as follows:
The relationship vector at position i is formed by stacking the pairwise relationships of all positions:
Spatial relation-aware features can be represented as:
Where GAP represents the Global Average Pooling operation in the channel domain.
Finally, the spatial attention at position i can be represented as:
RGA-C has the same form as RGA-S but treats the input as a set of d-dimensional features.
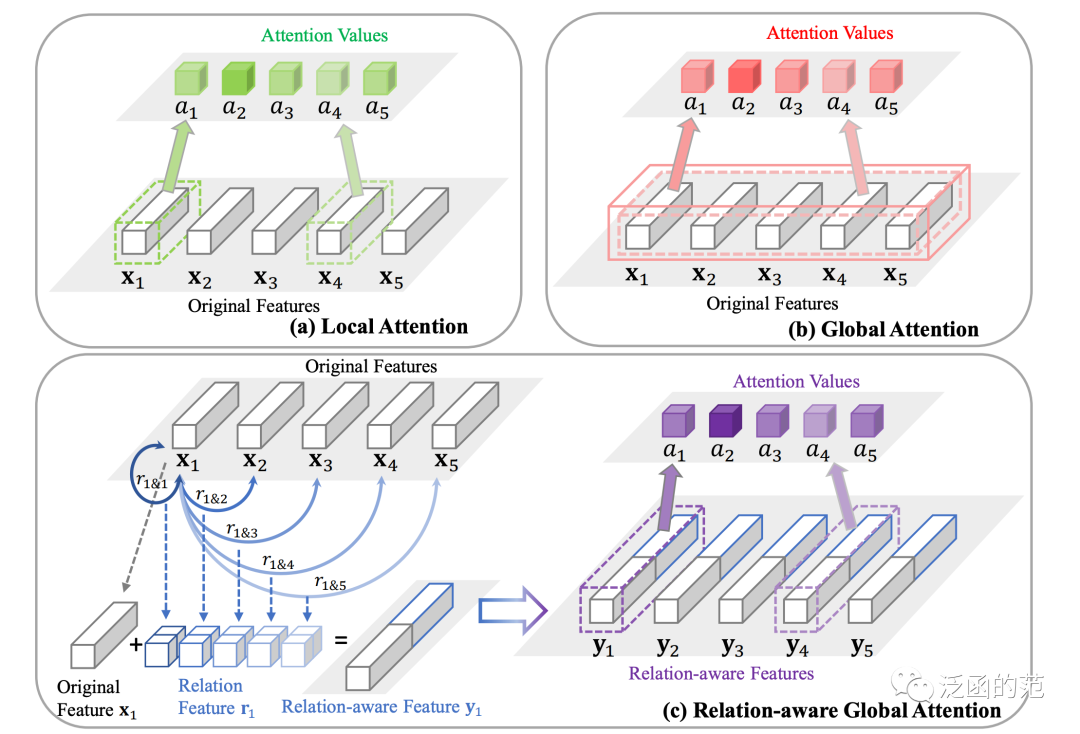
RGA calculates attention scores for each feature node using global relationships, providing valuable structural information and significantly enhancing representational capability. RGA-S and RGA-C are flexible enough to be used in any CNN network; the authors recommend using them consecutively to better capture spatial and cross-channel relationships.
For detailed code, see: https://github.com/microsoft/Relation-Aware-Global-Attention-Networks.git
17. Locally-grouped Self-attention
Chu X, Tian Z, Wang Y, et al. Twins: Revisiting the design of spatial attention in vision transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 9355-9366.
https://arxiv.org/pdf/2104.13840v4.pdf
Locally-grouped Self-Attention (LSA) is a local attention mechanism proposed in the Twins-SVT architecture. LSA first uniformly divides the 2D feature map into multiple sub-windows, allowing self-attention communication only within each sub-window. This design also resonates with the multi-head self-attention design, where communication occurs only between channels within the same head.
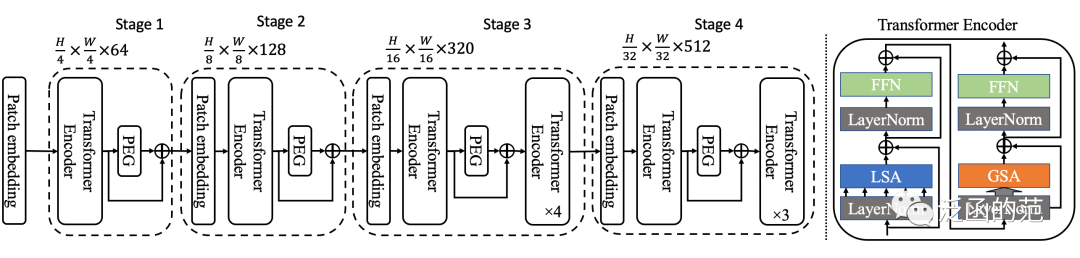
Specifically, a feature map of size H is divided into n sub-windows, where n and m are the dimensions. Each group contains k elements, thus the computation cost of self-attention within this window is O(k2), and the total cost is O(nk2).
If we set n and k, the cost can be computed as O(nk). When n and k are fixed, the overall computational cost is linearly related to k.
Although the locally grouped self-attention mechanism is computationally friendlier, the image is divided into non-overlapping sub-windows. Therefore, we need a mechanism to communicate between different sub-windows, similar to Swin. Otherwise, information will be confined to local processing, reducing the receptive field and significantly impairing performance in our experiments. This is akin to the fact that not all standard convolutions in CNNs can be replaced with depthwise separable convolutions.
For detailed code, see: https://github.com/Meituan-AutoML/Twins.git
Conclusion
This article summarizes 17 mainstream attention mechanisms, introduces their basic principles and computational methods, and provides their sources along with corresponding code for further reading.