Source: Information Network Engineering Research Center
This article is 1000 words long and is recommended to be read in 5 minutes.
This article will help you understand GAN, DCGAN, WGAN, and SRGAN.
GAN
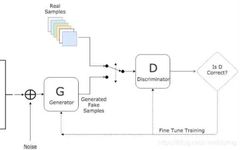
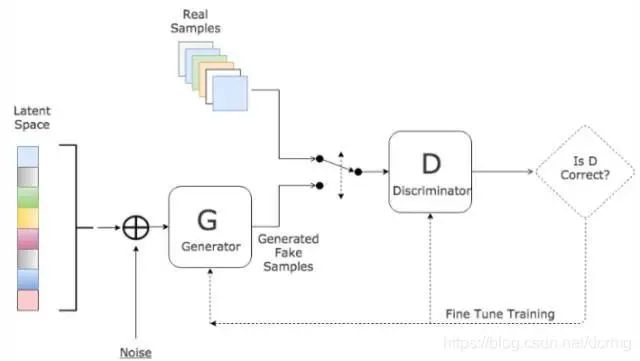
The generative network receives random noise and generates realistic images;
The discriminative network receives an image and generates the probability that the image is real (0 to 1);
In GAN, there are two different networks, and the training method used is adversarial training, where the gradient update information for G comes from the discriminator D, not from the data samples.
GAN is not suitable for handling discrete data forms, such as text.
JS divergence is used as the distance formula.
DCGAN
DCGAN (Deep Convolutional Generative Adversarial Networks) uses deep convolutional generative adversarial networks.
Improvements: 1. Removed the Pooling layer, replacing it with convolutions that include stride. The fully connected layers are also replaced with convolutions. 2. Added BN layers in both D and G networks. 3. The G network uses ReLU as the activation function, with tanh in the last layer. 4. The D network uses LeakyReLU as the activation function. 5. Trained using the Adam optimizer.
WGAN
WGAN utilizes a new distance definition called Wasserstein Distance, theoretically explaining the instability of GAN training, stating that cross-entropy (JS divergence) is not suitable for measuring the distance between distributions with non-overlapping parts. Instead, it uses Wasserstein distance to measure the distance between the generated data distribution and the real data distribution, theoretically resolving the training instability issue.
Wasserstein distance is also known as Earth Mover’s Distance (EMD). Reference: Several commonly used methods to calculate the distance between two probability distributions and their Python implementations.
1. Solved the instability problem in GAN training, no longer requiring careful balancing of the generator and discriminator training levels; 2. Almost resolved the mode collapse issue, ensuring diversity in generated samples; 3. Provided a meaningful value function to separately assess whether the discriminator and generator have converged. (In original GANs, if D performs poorly, we cannot tell if G is generating well or if D is not discerning well.)
1. Removed the sigmoid from the last layer. 2. The loss of the generator and discriminator is not taken in log. 3. Restricted the absolute value of the updated weights within a certain range. 4. Used RMSprop or SGD optimization; using momentum-based or Adam-based optimization algorithms is not recommended.
SRGAN
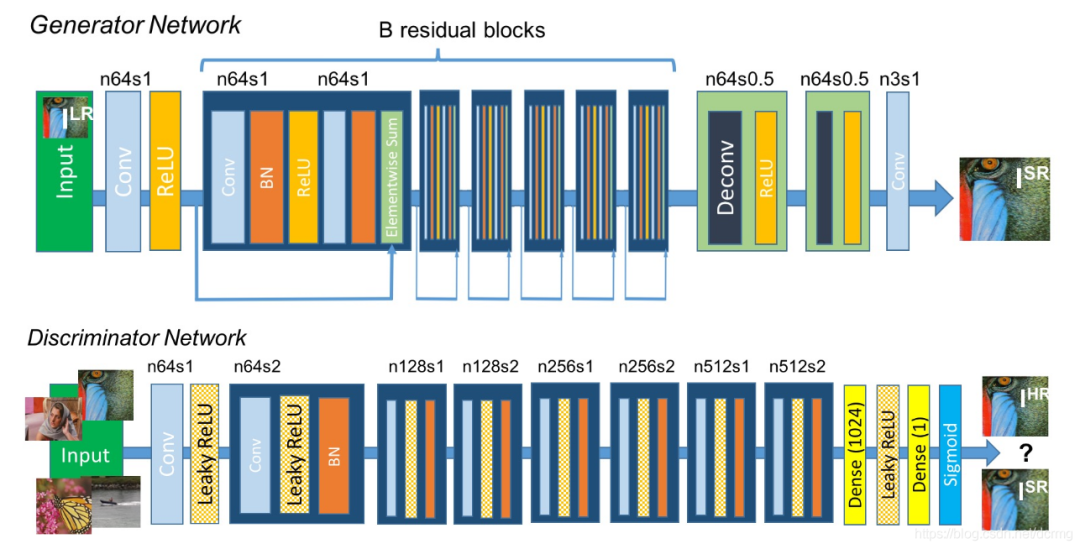
The generator loss function is divided into content loss and adversarial loss;
The content loss includes both the minimum mean square error in pixel space and the Euclidean distance of VGG features.