Introduction on how to use LangGraph to improve RAG.
Long press to follow “Python Learning Base”, join the reader group, and share more wonderful content.
1. Introduction
LangGraph is the latest member of the LangChain, LangServe, and LangSmith series, aimed at building generative AI applications using LLMs. Remember, all these are independent packages and must be installed separately via pip.
Before diving into LangGraph, it is important to understand two main concepts of LangChain.
1. Chain: A program built around LLMs to perform tasks such as automatic SQL writing or NER extraction chains. Note that chains cannot be used for any other tasks (not even general use cases), and attempting to do so may damage the chain. The steps to follow in a chain are predefined and cannot be flexibly adjusted.
2. Agent: A more flexible version of a chain, agents are typically LLMs that enable third-party tools (like Google Search, YouTube) and decide how to resolve a given query next.
Now, when dealing with real-world problems, a common issue is the desire to find a solution that lies between chains and agents. That is, not hardcoded like a chain, but also not entirely driven by LLMs like an agent.
2. LangGraph
LangGraph is a tool centered on LangChain for creating cyclic graphs in workflows. So, let’s assume the following example:
You want to build a retrieval system based on RAG on a knowledge base. Now, you want to introduce a situation where if the output of RAG does not meet specific quality requirements, the agent/chain should retrieve data again, but this time change the prompt by itself. And repeat this process until the quality threshold is reached.
Using LangGraph can achieve this cyclic logic. This is just one example; using LangGraph can accomplish much more.
Note: You can think of it as introducing cyclic logic into the chain, making it a cyclic chain.
LangGraph is crucial for building multi-agent applications like Autogen or MetaGPT.
As the name suggests, LangGraph has all the components of a general graph, such as nodes, edges, etc., which we will understand through an example.
3. Improving RAG with LangGraph
In this example, we wish to reduce the final output of the RAG system in the database to no more than 30 characters. If the output length exceeds 30 characters, we want to introduce a loop to try again with a different prompt until the length is less than 30 characters. This is a basic logic for demonstration purposes. You can even implement complex logic to improve RAG results.
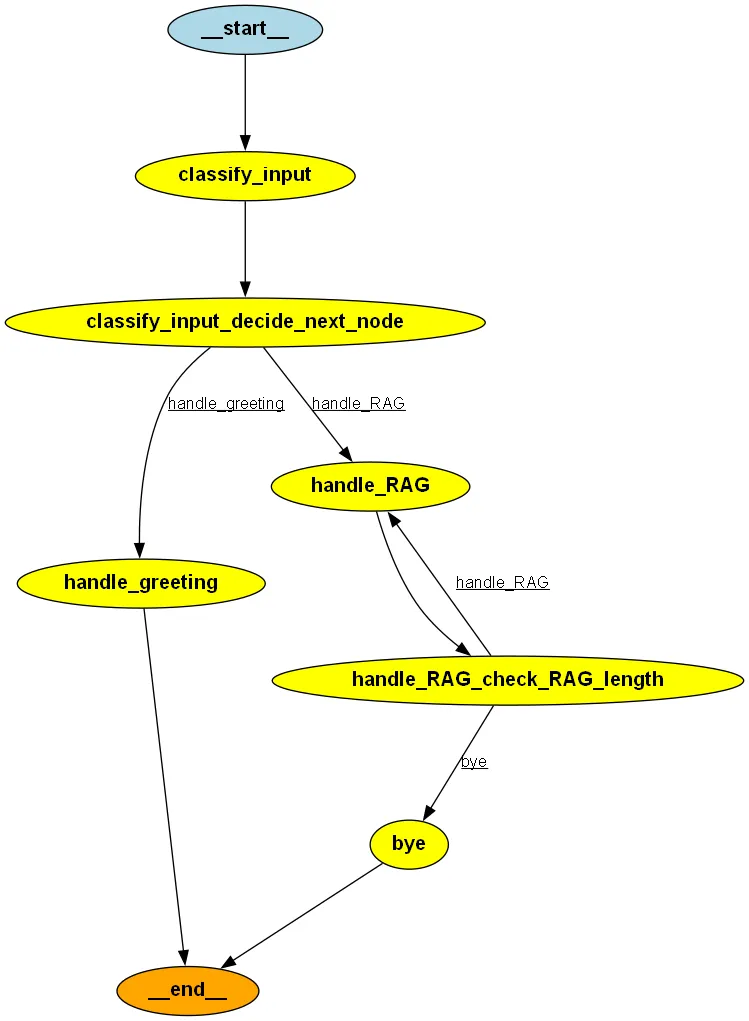
The graph we will create is shown below.
The versions used here are langchain===0.0.349, openai===1.3.8, langgraph===0.0.26.
3.1 First, let’s import the important content and initialize the LLM. Here, we use the OpenAI API, but you can also use other LLMs.
from typing import Dict, TypedDict, Optional
from langgraph.graph import StateGraph, END
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
llm = OpenAI(openai_api_key='your API')
StateGraph is the core of any LangGraph process, storing the states of various variables we will store while executing the workflow. In this example, we have 5 variables whose values will be updated during the execution of the graph and shared with all edges and nodes.
3.2 Next, let’s initialize a RAG retrieval chain from an existing vector database. The code is explained in the following video.
def classify(question):
return llm("classify intent of given input as greeting or not_greeting. Output just the class.Input:{}.format(question)).strip()
def classify_input_node(state):
question = state.get('question', '').strip()
classification = classify(question)
return {"classification": classification}
def handle_greeting_node(state):
return {"greeting": "Hello! How can I help you today?"}
def handle_RAG(state):
question = state.get('question', '').strip()
prompt = question
if state.get("length")<30:
search_result = rag_chain.run(prompt)
else:
search_result = rag_chain.run(prompt+'. Return total count only.')
return {"response": search_result,"length":len(search_result)}
def bye(state):
return{"greeting":"The graph has finished"}
workflow.add_node("classify_input", classify_input_node)
workflow.add_node("handle_greeting", handle_greeting_node)
workflow.add_node("handle_RAG", handle_RAG)
workflow.add_node("bye", bye)
This requires some explanation.
Each node is a Python function that can:
① Read any state variable.
② Update any state variable. In this case, the return function of each node will update the status/value of one or more state variables.
Use state.get() to read any state variable.
handle_RAG node can help us implement the custom looping logic we desire. If the output length <30, use prompt A; otherwise, use prompt B. For the first case (when RAG node hasn’t been executed), we will pass length=0 and provide a prompt.
We added an entry point to the graph, which will execute the first node function regardless of what the input prompt is.
The edges between nodes A and B define that node B will execute after node A. In this case, if handle_greeting or bye appears in our workflow, the graph should END (a special node to terminate the workflow).
Conditional edges can choose between two nodes based on conditions (like if-else). In the two conditional edges created:
First Conditional Edge
When encountering classify_input, choose handle_greeting or handle_RAG based on the output of decide_next_node function.
Second Conditional Edge
If encountering handle_RAG, choose handle_RAG or bye based on the check_RAG_length condition.
3.6 Compile and invoke the prompt. Initially, keep the length variable set to 0.
app = workflow.compile()
app.invoke({'question':'Mehul developed which projects?','length':0})
# Output
{'question': 'Mehul developed which projects?',
'classification': 'not_greeting',
'response': ' 4',
'length': 2,
'greeting': 'The graph has finished'}
For the above prompt, the graphical flow is as follows:
classify_input: The sentiment will be not_greeting.
Due to the first conditional edge, move to handle_RAG.
Since length=0, use the first prompt and retrieve the answer (the total length will be greater than 30).
Due to the second conditional edge, move again to handle_RAG.
Since length>30, use the second prompt.
Due to the second conditional edge, move to bye.
END.
If LangGraph was not used:
rag_chain.run("Mehul developed which projects?")
# Output
"Mehul developed projects like ABC, XYZ, QWERTY. Not only these, he has major contribution in many other projects as well at OOO organization"
3.7 Next input.
app.invoke({'question':'Hello bot','length':0})
# Output
{'question': 'Hello bot',
'classification': 'greeting',
'response': None,
'length': 0,
'greeting': 'Hello! How can I help you today?'}
The flow here will be simpler.
classify_input: The sentiment will be greeting.
Due to the first conditional edge, move to handle_greeting.
END.
While the conditions applied here are quite simple, this framework can easily be used to improve your results by adding more complex conditions.
“Practical Machine Learning Platform Architecture” elaborates on the basic solutions related to machine learning platform architecture, mainly including machine learning and machine learning solution architecture, business use cases of machine learning, machine learning algorithms, data management in machine learning, open-source machine learning libraries, Kubernetes container orchestration infrastructure management, open-source machine learning platforms, building data science environments using AWS machine learning services, building enterprise machine learning architectures using AWS machine learning services, advanced machine learning engineering, machine learning governance, bias, interpretability and privacy, building machine learning solutions using AI services and machine learning platforms, etc. Additionally, this book provides corresponding examples and codes to help readers further understand the implementation process of related solutions.
[50% Off Promotion] Purchase Link: https://item.jd.com/13855627.html
Exciting Reviews
30 Most Commonly Used Python Libraries in Data Engineering (Part 2)
30 Most Commonly Used Python Libraries in Data Engineering (Part 1)
Using BitoAI Plugin with PyCharm to Call ChatGPT, Speed Increased by 10 Times!
Full Analysis of RAG, with Code Implementation Using LangChain
Easily Build a Knowledge Base Based on LangChain, LlamaIndex, and OpenAI
LangChain Beginner’s Guide, Learn Easily, Help You Navigate Freely
Long press to follow “Python Learning Base”, join the reader group, and share more wonderful content.Long press to visit [IT Today’s Hot List], discover daily technology hotspots.