
Andrew Ng recently said in his public lecture: I believe that AI Agent workflows will drive significant advances in artificial intelligence this year, possibly surpassing the next-generation foundational models. This is an important trend, and I urge everyone working in AI to pay attention to it. Coupled with the four paradigms for implementing Agent workflows that he shared at his Sequoia AI Summit last month, it is clear that Ng has been focusing on the development of Agents.
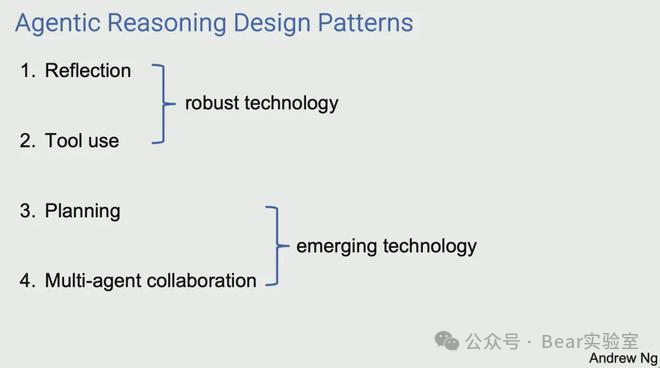
Let me explain these four paradigms:
-
Reflection: The LLM reflects on its work and identifies ways to improve.
-
Tool Use: The LLM is equipped with tools such as web search, code execution, or any other function to help it gather information, take action, or process data.
-
Planning: The LLM proposes and executes a multi-step plan to achieve a goal (e.g., drafting an outline for an article, conducting online research, then writing a draft, etc.).
-
Multi-agent Collaboration: Multiple AI Agents work together, breaking down tasks, discussing and debating ideas, and proposing better solutions than a single agent could.
Purpose
In this article, we will dissect a project on GitHub called GPT-researcher (https://github.com/assafelovic/gpt-researcher). This project collaborates through multiple Agents to search for information online, analyze, and write based on user-provided topics, ultimately outputting several pages of research reports in PDF or Markdown format. This project is also inspired by Stanford University’s STORM research paper, which can be referenced at https://arxiv.org/abs/2402.14207.
The overall execution process involves the four paradigms mentioned by Ng: multi-agent collaboration, plan-and-execute, tool usage (online information searching), and reflection.
The collaboration of multiple Agents is implemented based on LangGraph, which is an extension of LangChain. I will discuss this later, and I also want to critique LangGraph.
Multi-Agent Collaboration Architecture
The project has a core module called gpt-researcher, which functions to allow the LLM to choose a suitable Agent based on the topic provided by the user. It generates a plan based on the topic and then creates sub-queries for multiple queries based on that plan. Each sub-query searches for information online, organizes it, and provides sources. Finally, it summarizes and formats the outputs of all sub-queries into a report. This is a function that the author implemented early on, and I will explain it in detail later. This article mainly introduces multi-agent collaboration based on LangGraph.
It mainly includes seven Agents simulating a research team collaboration:
-
Chief Editor: The Chief Editor supervises the research process and manages the team. This is the “master” Agent that coordinates other Agents using LangGraph.
-
Researcher: The Researcher uses the core module gpt-researcher to conduct in-depth research on the given topic.
-
Editor: The Editor is responsible for planning the research outline and structure.
-
Reviewer: The Reviewer verifies the correctness of research results based on a set of standards.
-
Revisor: The Revisor revises the research results based on feedback from the Reviewer.
-
Writer: The Writer is responsible for drafting the final report.
-
Publisher: The Publisher is responsible for publishing the final report in various formats such as PDF, WORD, MD.
Flowchart
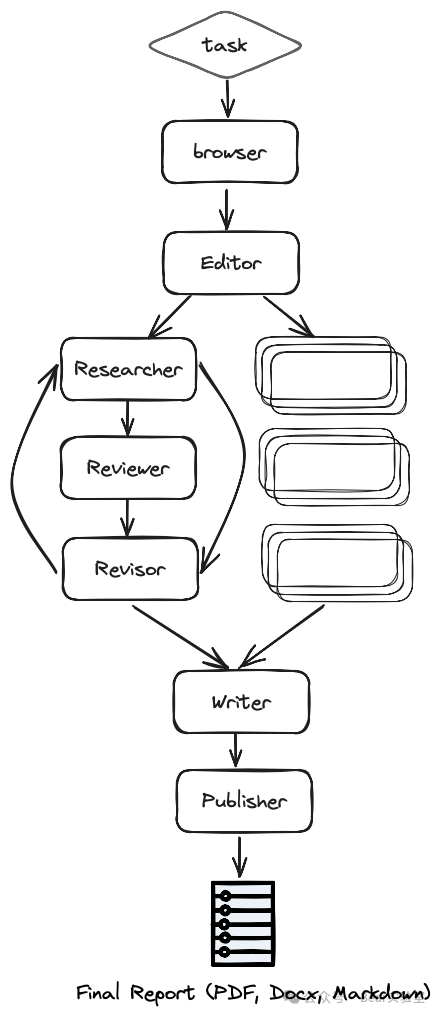
Main Process:
-
The user provides a task, including the topic query, maximum sections, and other requirements.
-
The Chief Editor, the master Agent, receives the task, initializes the process executor (Executor, a LangGraph process), and assigns the task to the Browser.
-
The Browser in the above diagram is also the Researcher Agent, which conducts preliminary research on the internet based on the given research task.
-
The Editor, a complex Agent, plans the report outline and structure based on preliminary research, executing Plan-and-Execute. The Editor’s editing includes a LangGraph subprocess.
-
For each outline topic (in parallel), this is where LangGraph’s advantages are evident, as it can execute iterative processes. The Reviewer and Revisor:
-
The Researcher is responsible for invoking gpt-researcher to conduct in-depth research on sub-topics and write drafts. -
The Reviewer verifies the correctness of the draft based on a set of standards from the user’s task’s requirements and provides feedback. -
The Revisor revises the draft based on the Reviewer’s feedback and returns it to the Reviewer until the Reviewer is satisfied, meaning no further revision suggestions are given.
prompt = [{"role": "system","content": "You are an expert writer. Your goal is to revise drafts based on reviewer notes."}, {"role": "user","content": f"""Draft:\n{{draft_report}}" + "Reviewer's notes:\n{{review}}\n\nYou have been tasked by your reviewer with revising the following draft, which was written by a non-expert. If you decide to follow the reviewer's notes, please write a new draft and make sure to address all of the points they raised. Please keep all other aspects of the draft the same. You MUST return nothing but a JSON in the following format:{{sample_revision_notes}}"""}]“role”: “system”,”content”: “You are a professional writer. Your goal is to revise drafts based on reviewer notes.” “role”: “user”,”content”: “Your reviewer has tasked you with revising the following draft written by a non-expert. If you decide to follow the reviewer’s notes, please write a new draft and ensure that you address all the points they raised. Please keep all other aspects of the draft unchanged. You can only return JSON in the following format:”
-
Tavily: A startup that has emerged in the AI era, providing APIs related to Search and News, capable of returning data in a format that is friendly to LLMs in real-time. I also used it during my development, and the overall effect was quite good, though the free call limit is only 1000 times, and running this project once consumed 6 calls. -
SerpApi: A long-established search API integration service that even includes Baidu’s API, although it is a bit pricey. -
DuckDuckGo: A search engine that emphasizes privacy, not tracking users’ search history or browsing habits. -
BingSearch: A search engine launched by Microsoft, which can be activated on Azure cloud services, but the returned results are still in a relatively traditional format. -
SearxNG: Open-source and can be self-deployed; I found its performance to be average after trying it out, so I abandoned it. However, the allure of open-source and free tools is still quite significant.
