
In recent years, with the rapid advancement of long-context model (LCM) technology, the ability to handle long contexts has become a core competitiveness of large language models (LLMs) and a focal point for many tech companies. As of December 2023, few models can exceed the 8K context limit; however, by September 2024, the Gemini Pro model has been able to handle contexts up to 2M. In just nine months, the context window of long-text models has achieved an astonishing growth of 250 times. Recently, the highly discussed OpenAI o1-preview model also claims to handle contexts up to 130K.
So, how do these models perform on benchmark tests for long-text understanding tasks? By observing the latest or most commonly used benchmark rankings, an interesting phenomenon can be found: whether in length handling (Figure 1: XL2Bench, 2024), task difficulty (Figure 2: Ruler, 2024), or real-world tasks (Figure 3: LongBench, 2024), open-source models generally lag behind closed-source models. Moreover, there seems to be no more critical information worth noting.
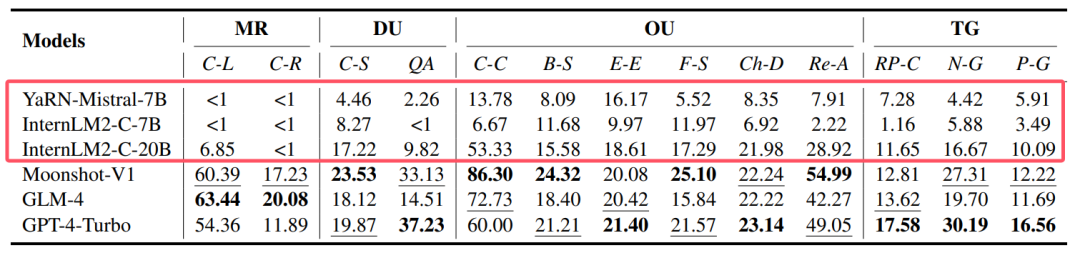
Figure 1: XL2Bench, red box indicates open-source models
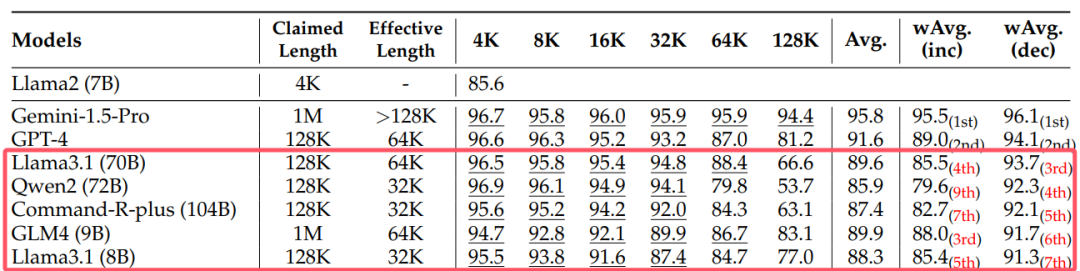
Figure 2: Partial results of Ruler, red box indicates open-source models
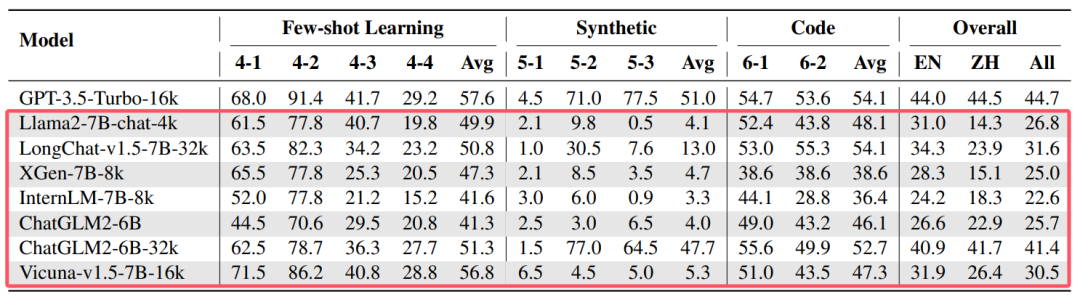
Figure 3: Partial results of LongBench, red box indicates open-source models
With long-text evaluation benchmarks springing up like mushrooms, a severe homogenization phenomenon has emerged among these benchmarks. They either compete to increase text length or raise task difficulty, or both. In some cases, this trend has led to even the most advanced closed-source models, such as GPT-4, performing poorly in tests. But does this competition really make sense?
In this context, we should consider what the original intention of developing long-text models is; only by clarifying this goal can we prescribe the right remedy and design more reasonable evaluation benchmarks. First, let’s review the most common application scenarios for long-text models in the real world—long-text understanding tasks. Based on this scenario, we will then introduce the capabilities that should be focused on when evaluating long-text models.
Long-Context Models and Long-Text Understanding Tasks
Typically, a possible user input is shown in Figure 4:
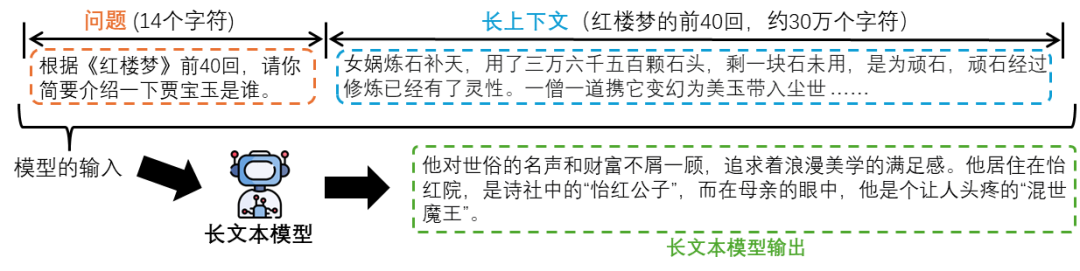
Figure 4: The user inputs a question and then provides a long context segment for the long-text model to respond
Of course, if you are a loyal LLM believer, you will surely believe this response. But if you are skeptical about these responses, that is completely normal, as everyone must have a question in mind: “Is the model’s response really correct?” Do we still need to read the article first and then go back to check the model’s response?
But if the model can provide reference texts along with the answer, as shown in Figure 5, then the user can directly verify the model’s response based on this reference information. The user can simply refer back to the original text using the provided reference sections and content. This practice of providing reference sources is commonly referred to as “Citation,” which can reflect the model’s faithfulness.
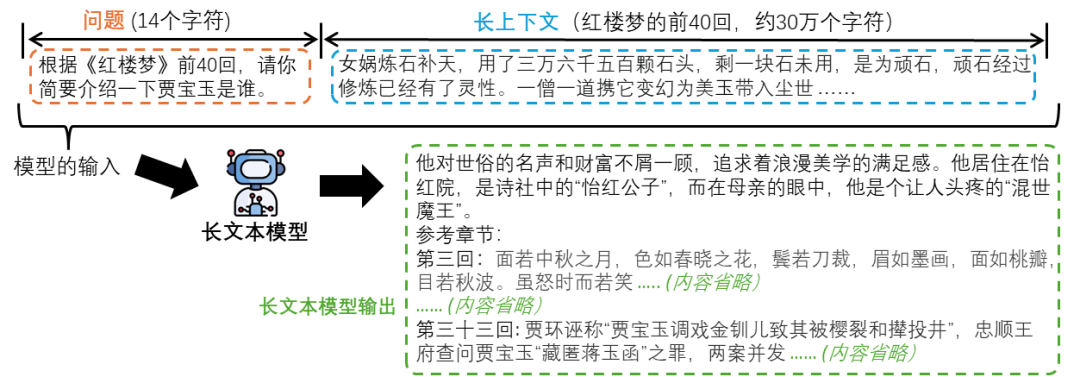
Figure 5: The long-text model not only provides an answer but also the referenced text (Citation)
The Current State of Citation Generation & Our Progress
In the current long-text model evaluation field, there are indeed not many lists that test the model’s faithfulness. ALCE was once a well-recognized evaluation benchmark focusing on assessing the model’s citation generation ability, thus indirectly reflecting its faithfulness. However, with the development of long-text processing technology, the context length involved in ALCE’s tasks has become somewhat inadequate.
To meet this challenge, THU combined the QA tasks from Longbench and proposed an extended version of ALCE called LongCite; although this somewhat solves the length issue, it is still limited to QA tasks, with the longest context length reaching only 32K, which still has a significant gap compared to the current long-text model’s context processing ability.
In response to this situation, we propose a brand new long-text understanding task benchmark—L-CiteEval. L-CiteEval is a multi-task long-text understanding benchmark that includes citation generation, covering five main task categories: single-document Q&A, multi-document Q&A, summarization, dialogue understanding, and synthesis tasks, with a total of 11 different long-text tasks. These tasks have context lengths ranging from 8K to 48K. Additionally, we provide automated evaluation tools (not relying on manual evaluation or GPT4 evaluation) to facilitate researchers and developers in objectively evaluating models.
Paper & Code (Evaluation Data) Portal:
Paper: L-CiteEval: Do Long-Context Models Truly Leverage Context for Responding? Link: https://arxiv.org/pdf/2410.02115 Project: https://github.com/ZetangForward/L-CITEEVAL
Next, we will briefly introduce our work; for more details, please refer to our paper and source code (including evaluation data).
Note: The codebase is still being organized and should be released before the National Day holiday; everyone is welcome to use it and provide valuable feedback!
L-CiteEval Task Format
As shown in Figure 6, in the L-CiteEval benchmark test, the model needs to generate a response (Response, R) based on the user’s question (Question, Q) and the provided long reference context (Reference, R). To ensure the accuracy and verifiability of the response, the model is required to generate the response in a specific format, where each statement (Statement, S) is followed by a corresponding citation (Citation, C). This format aids in the comprehensive evaluation of the model’s response during the verification (Verification, V) phase.
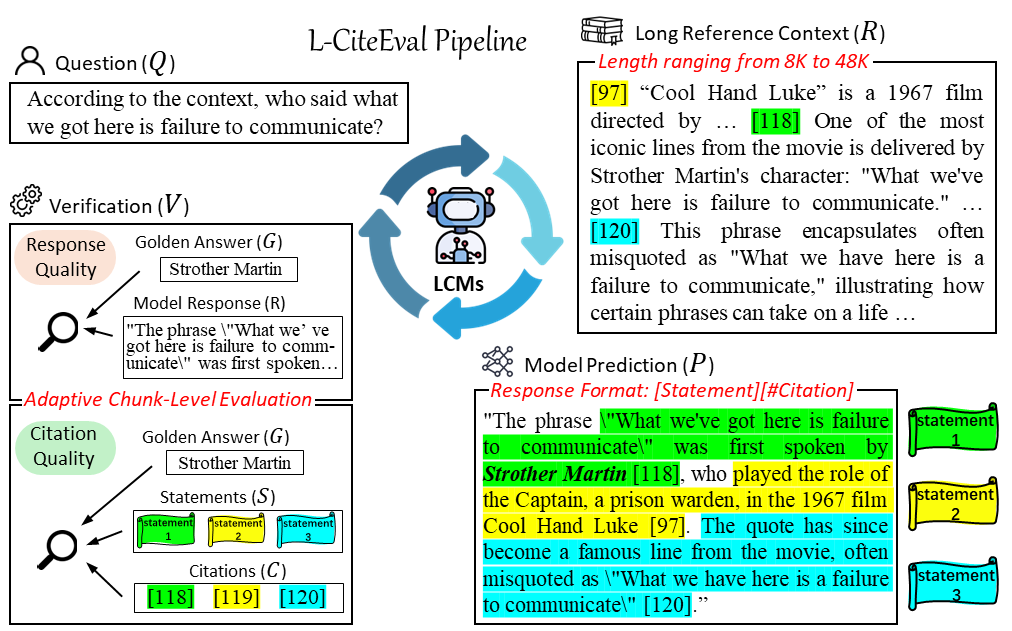
Figure 6: The task format of L-CiteEval
Dataset Distribution & Production
1) Evaluation Dataset Distribution
Figure 7 shows the data distribution of the test dataset, and we provide corresponding automatic evaluation metrics for the generation quality of different tasks. For the evaluation of citation quality, a unified standard is adopted, namely Citation Recall (CR), Citation Precision (CP), and Citation F1 score (F1). The calculation methods for these metrics are the same as those used in the ALCE benchmark test, and the specific calculation methods can be referenced in ALCE.
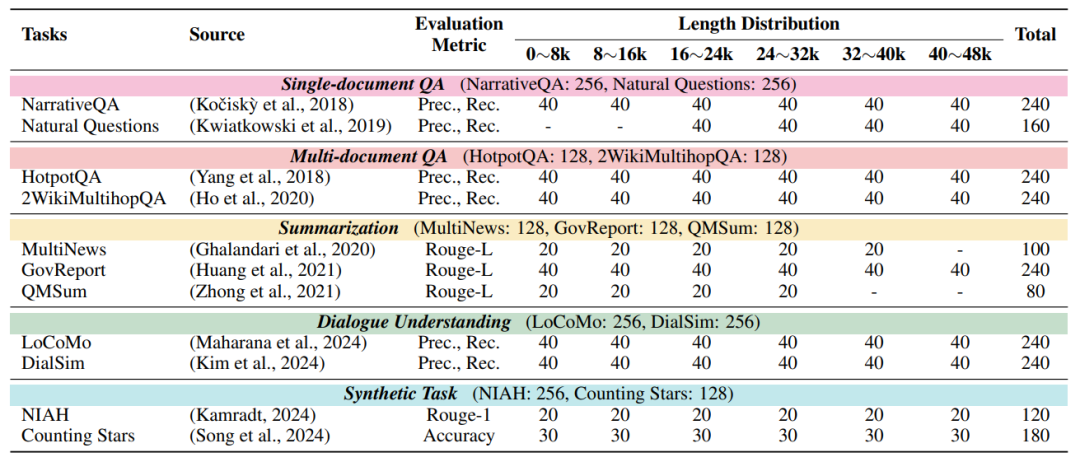
Figure 7: L-CiteEval test dataset distribution
2) Dataset Production Process

Figure 8: L-CiteEval testing data process
As shown in Figure 8, the specific testing data production process includes three steps:
-
Seed Data & Padding Data Sampling:
-
Sample a portion of the test dataset from each source dataset as seed data.
-
For datasets with shorter contexts, sample data from the remaining datasets as candidate padding data to extend the context length.
-
Padding Data Filtering:
-
Use named entity recognition (NER) models to extract entities from the questions and reference contexts in the seed data and from the reference contexts in the padding data.
-
Retain padding samples that overlap less with the seed data entities to reduce additional contextual information that may affect predictions.
-
Length Extension:
-
Use the filtered padding data to extend the context length of the seed data.
-
Randomly sample padding data to fill in the length gaps missing from the seed data based on the target length intervals.
Model Evaluation
Model Selection
As shown in Figure 9, our evaluation currently covers the most commonly used long-text models, including closed-source, open-source, different sizes, and different structures.
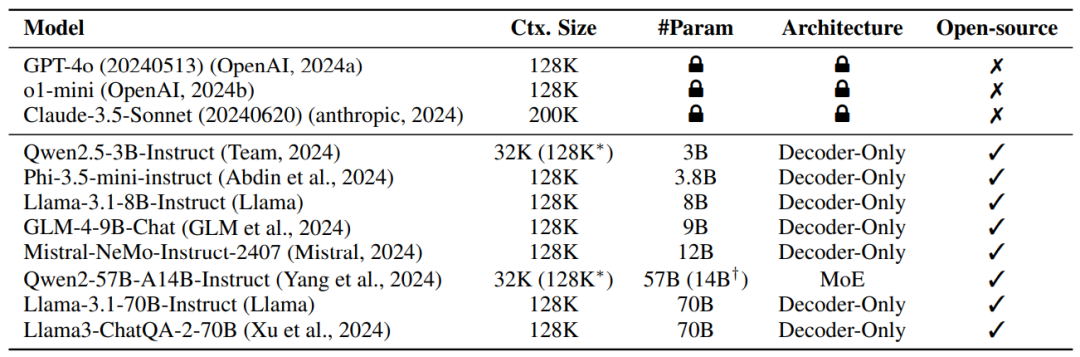
Figure 9: Model selection
Main Experimental Results:
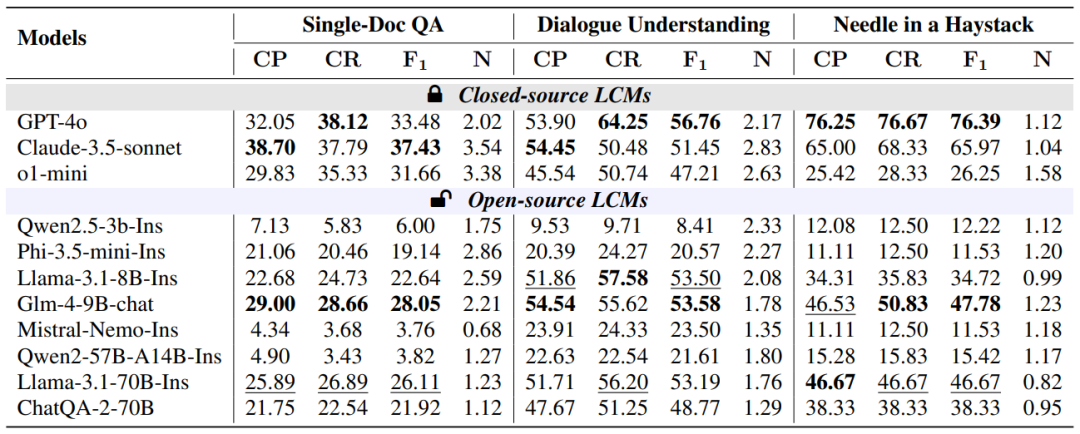
Figure 10: Citation quality of models on information concentration tasks
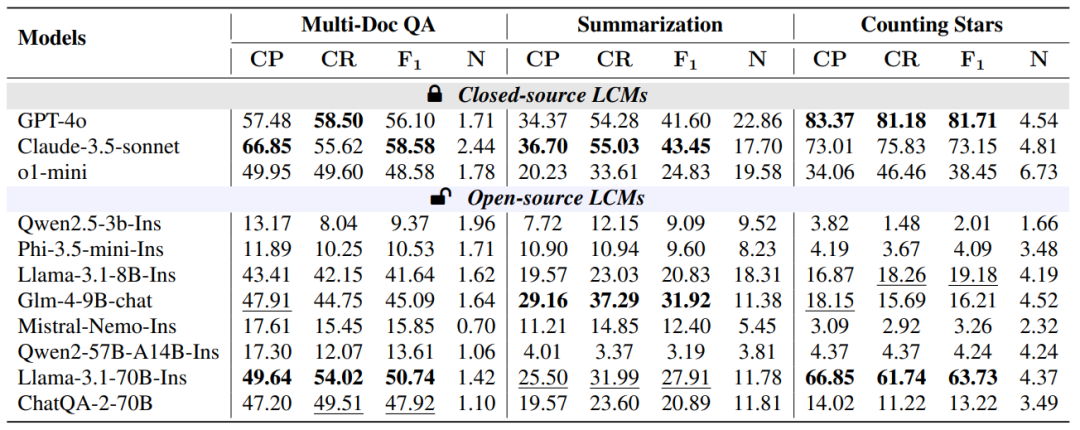
Figure 11: Citation quality of models on information dispersion tasks
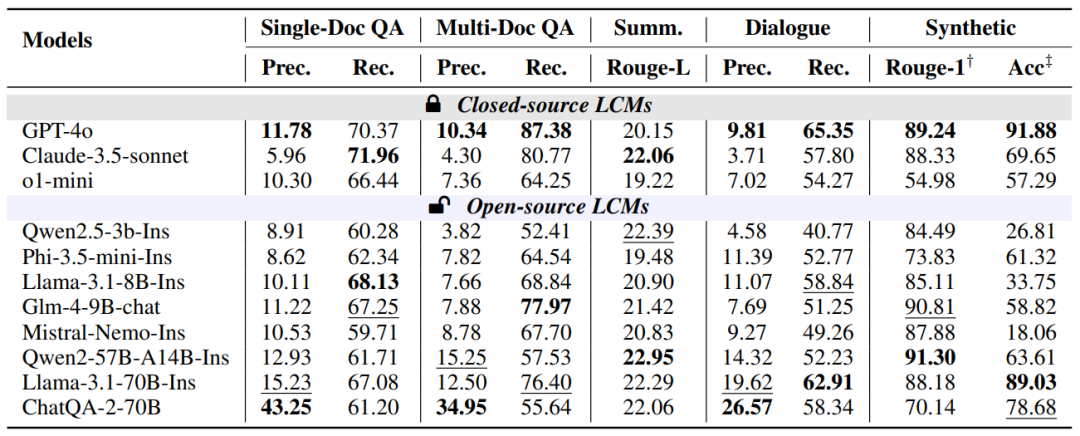
Figure 12: Model generation quality
Several Key Conclusions:
-
Performance of Closed-Source Models: Closed-source models GPT-4o and Claude-3.5-sonnet excel in generation quality and citation quality, especially in citation accuracy and recall. However, o1-mini is more suitable for reasoning tasks rather than those requiring context retrieval.
-
Performance of Open-Source Models: Open-source models are comparable to closed-source models in generation quality but lag in citation quality, especially in tasks requiring reasoning; some larger open-source models, such as Llama-3.1-70B-Instruct, perform nearly as well as closed-source models in certain tasks.
-
Model Size and Performance: Model size does not always correlate with performance. Some medium-sized models (like 8B and 9B) perform comparably to larger models on certain tasks, indicating a high cost-performance ratio for medium models, with significant development potential. However, larger models are generally more stable in performance, and if further enhanced, they may catch up with closed-source models.
Other Experiments
Does Length or Task Difficulty Have a Greater Impact on Long-Context Models?
L-CiteEval-Length and L-CiteEval-Hardness are two variants of the L-CiteEval benchmark, designed to evaluate long-context models from different perspectives, with the following purposes:
-
L-CiteEval-Length focuses on evaluating the model’s performance at different context lengths.
-
L-CiteEval-Hardness focuses on evaluating the model’s performance at different task difficulties.
The evaluation results are shown in Figures 12 and 13. Key conclusions:
-
Impact of Context Length (L-CiteEval-Length): When task difficulty remains constant, as the context length increases, the performance of open-source LCMs generally shows a downward trend, especially smaller models are more affected by longer contexts. Closed-source LCMs, such as GPT-4o, maintain relatively stable performance even at longer context lengths.
-
Impact of Task Difficulty (L-CiteEval-Hardness): As task difficulty increases, the generation quality of LCMs typically declines, but citation quality does not show a consistent trend. This indicates that faithfulness (whether based on context for responses) is not strongly correlated with task difficulty.
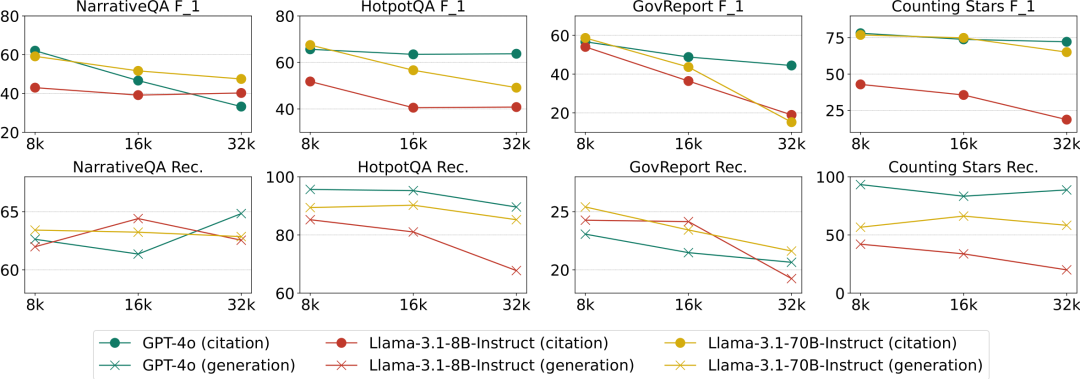
Figure 12: Model generation and citation quality on L-CiteEval-Length
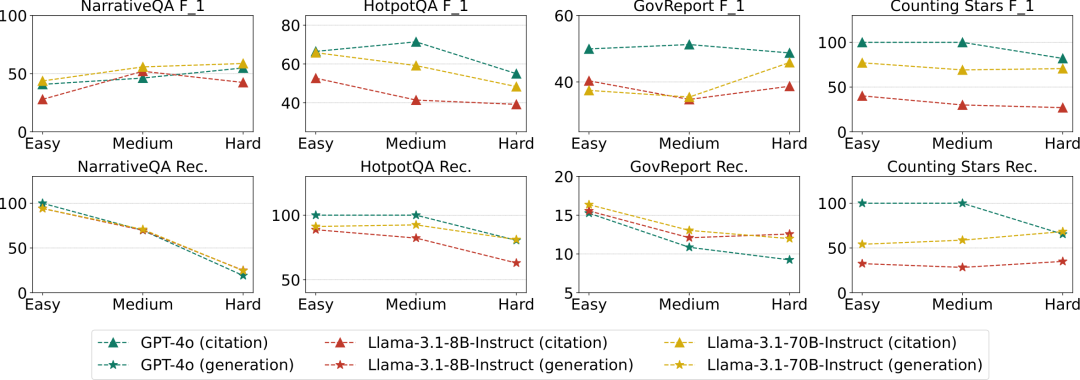
Figure 13: Model generation and citation quality on L-CiteEval-Hardness
Does RAG Help L-CiteEval?
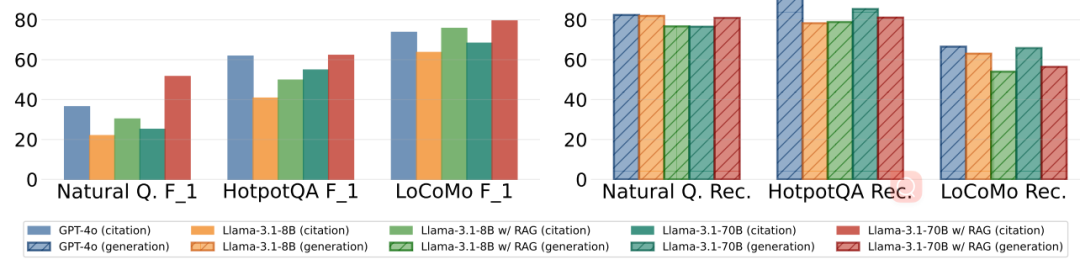
Figure 14: RAG-enhanced long-text models’ generation and citation quality on L-CiteEval sub-tasks
As shown in Figure 14, RAG technology significantly improved the faithfulness of models on open-source models (even matching the performance of GPT4o). However, RAG technology may slightly affect the generation quality of the models.
Is Citation Generation Related to Attention Mechanisms?
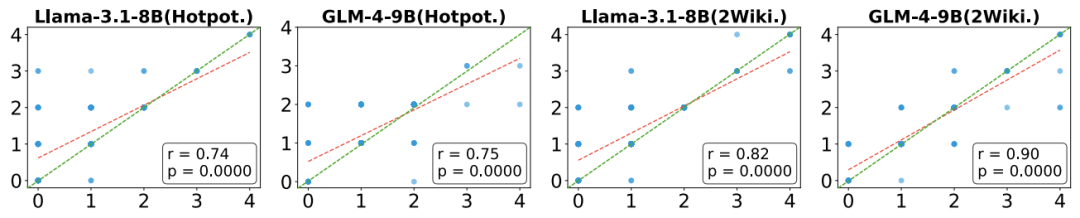
Figure 15: The relationship between citation generation and attention mechanisms (correlation coefficient). Red line: fitted correlation curve; green line: theoretically optimal correlation curve
Attention mechanisms are a key component of many modern LCMs, enabling models to focus on the most important parts of the input sequences. In long-text processing tasks, effective attention allocation can help models better understand and utilize contextual information.
As shown in Figure 15, the red line (correlation curve of citation generation and attention) closely overlaps with the green line (theoretically optimal correlation curve). This indicates a high correlation between the context segments the model focuses on when generating citations and the actual correct citations. If the model’s attention mechanism can correctly concentrate on the context segments containing answer information, the model is more likely to generate accurate citations.
This finding validates the reasonableness of citation generation and the L-CiteEval benchmark dataset, while also providing ideas for future long-text benchmark datasets and long-text model development.
Conclusion
This article proposes an evaluation baseline that emphasizes the interpretability of generation results and the faithfulness of models, which is an important consideration in the development of long-text models. However, as technology continues to advance, we must ponder: do future long-text models really need to endlessly pursue greater context processing capabilities? In practical applications, do we frequently need models to handle such large amounts of text? The development of long-text models seems to be entering a “competition” trap, blindly pursuing breakthroughs in numbers while potentially neglecting the actual needs of practical applications.
In fact, users may be more concerned about whether the model truly bases its responses on context, rather than just the correctness of the answers. This shift in focus suggests that in future research, we may need to pay more attention to the model’s understanding and reasoning abilities, as well as how to make the model’s decision-making processes more transparent and interpretable. Should we step out of the race for “longer contexts” and instead explore how to enable models to provide more precise and human-like responses given a context?
The “true window size” of long-text models may not be the length of text the model can handle but rather the depth and accuracy of the model’s understanding and utilization of contextual information. This depth and accuracy are key to building user trust and satisfaction. Therefore, future research on long-text models should perhaps focus more on enhancing the faithfulness and interpretability of models rather than merely pursuing the ability to process longer texts.
References
[1]o1-preview: https://artificialanalysis.ai/models/o1
[2]ALCE: https://zhuanlan.zhihu.com/p/660368275
[3]LongCite: https://arxiv.org/pdf/2409.02897

Scan the QR code to add the assistant’s WeChat
