
Click the above “Beginner’s Guide to Vision” and select “Star” or “Pin”
Important content delivered first<br/>Author: Pallawi
Original link: https://medium.com/@pallawi.ds/difference-between-image-processing-computer-vision-and-artificial-intelligence-af670d65055d
Translation: AI Algorithms and Image Processing
Image Processing

The left image is the input image, and the right image is the processed image.
Here is the link to my image processing code, which is easy and fun to try yourself. https://github.com/PallawiSinghal/AI_Starter/blob/master/image_processing.ipynb
Computer Vision
Now, you want to reward your pets ‘Shimmy’ and ‘Pluto’ as the winner and runner-up based on who catches the red apple or yellow disc the most times and returns it to you while moving on their respective tracks, with ‘Shimmy’ on the left and ‘Pluto’ on the right (game rules).
So now you must build a computer vision system to automate your work.
Thus, the first step of the CV (computer vision) system should be to analyze each of the 350 images in detail.
Analysis Stage
The goal of this analysis is to find a universal solution, not just for a few hundred images, but for many images over the years.
What we must look for in the images is the pattern of how the pets appear most of the time. Just like here, ‘Shimmy’ is on the left track, and ‘Pluto’ is on the right.

The left image is the input image, the middle image is the mask (if you look at the image for a while, you can find the intensity differences from the center to the corners), and the right image is the background image (this background) completed using the very famous OpenCV function “Grabcut” (foreground and background segmentation).

The first image is a blurred image of the image on the top right, where the blur image processing algorithm used is for edge preservation and noise reduction. The second image is a grayscale image. The third image is a threshold image, also known as a binary image. The fourth image is the contour image of the third image (simply put, we are trying to draw boundaries on all objects that are white, which also includes the pets), and in the last image, we approximate the maximum contour using the convex hull, where the largest contour will be the pet’s contour, and we draw the approximate shape, the polygon, on the image.

The left image is the input image for this step, and we create an approximate small mask (center image) to transfer the pet polygon (also known as warping) onto the small image (center image). The warped result looks like the right image.

The left image is the input here, and we use a small template image of the yellow disc to perform template matching on this image, as shown below. Template matching is an algorithm where the template image moves from top to bottom over the input image, which in our case is the leftmost image, and finds the best matching part in the input image. The output of the template matching will be the center image, as you can see that the brightest and shiniest part of the image is where the yellow disc is located. Therefore, we draw a box on the rightmost image.

Template image
Here is the link to my computer vision code, which you can easily and fun try yourself
https://github.com/PallawiSinghal/AI_Starter/blob/master/computer_vision.ipynb
Artificial Intelligence
If you choose a hard threshold to detect ‘Shimmy’, ‘Pluto’, or the yellow disc, for example, applying semi-automatic segmentation (OpenCV grab cut), template matching, and deciding on the paths the pets should move, then this designed system may lack scalability or threshold values for the colors of the pets’ bodies. You may end up creating a biased system that can only recognize ‘Shimmy’ and ‘Pluto’.
You will not be able to hand over your CV system to the world to get the same results on different dogs or cats because the rules and features are biased only towards ‘Shimmy’ and ‘Pluto’.
AI ‘savior’ provides image processing, computer vision algorithms, and machine learning algorithms to help you promote the system like magic.
Just like you learned to differentiate mundane things in the education system, your teachers taught you to distinguish using images, feeding your brain two inputs: one is the image, and the second is the correct feature description, its appearance, and location in the picture.
Similarly, if we want to build an AI system for the above analogy, we need to use image processing algorithms to provide pre-processed images and tell them the position and existence of the ball, disc, apple, dog, or anything you want to detect in the image.
Then, once the images and the content, information of the images are provided to the system, computer vision will appear in the pictures.
AI consists of multiple layers, like a loaf of bread, where each layer runs a computer vision algorithm that works to extract features from the images.
In the earlier layers, we extract low-level features such as edges of lines or curves on the image, and then in each subsequent layer, it learns to detect eyes, apples, paws, tails, and all extracted features in the later layers. Later, you will use these learned convolutional kernels to predict objects on a new dataset, which is also known as the test dataset.
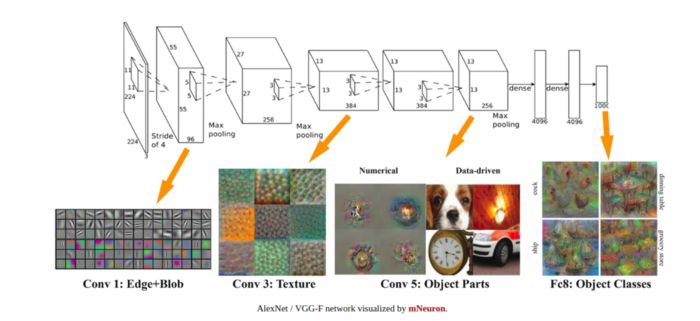
The above image is provided by https://www.cc.gatech.edu/~hays/compvision/proj6/, where you can see how layers look and how features are extracted in each layer.
Of course, there are mathematical equations. But let me assure you, they are easy, and you can do it.
And all the learning is stored in the model, just like our learning is stored in our brains; it is universal and can be used for any other data.
A very critical input for building an AI solution is data. Imagine the effort you need to create a dataset of dogs playing with balls all over the world (a dataset with no errors).
Therefore, the integration of image processing, computer vision, and machine learning forms an AI system that you hear, see, and experience around you.
Summary

Good news!<br/>Beginner's Guide to Vision Knowledge Planet<br/>Is now open to the public👇👇👇<br/><br/>Download 1: OpenCV-Contrib extension module Chinese version tutorial<br/>Reply to "Extension Module Chinese Tutorial" in the "Beginner's Guide to Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.<br/><br/>Download 2: Python Vision Practical Project 52 Lectures<br/>Reply to "Python Vision Practical Project" in the "Beginner's Guide to Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.<br/><br/>Download 3: OpenCV Practical Projects 20 Lectures<br/>Reply to "OpenCV Practical Projects 20 Lectures" in the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV to achieve advanced learning of OpenCV.<br/><br/>Discussion Group<br/><br/>Welcome to join the reader group of the public account to communicate with peers. Currently, we have WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, it will not be approved. After successfully added, you will be invited to the relevant WeChat group according to your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~<br/>