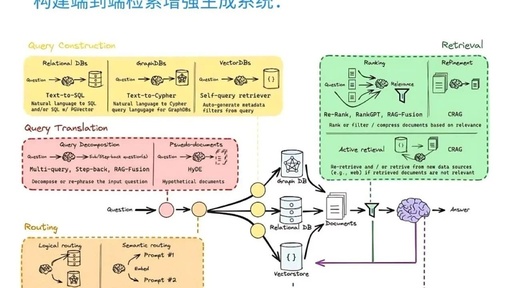
Detailed Explanation of RAG 2.0 Architecture
The so-called RAG, short for Retrieval-Augmented Generation, combines retrieval and generation technologies to enhance the effectiveness of text generation tasks. Its working principle combines the advantages of retrieval models and generation models to address some challenges and issues in text generation. RAG 2.0, on the other hand, is an integrated system that aligns all components through pre-training and fine-tuning, maximizing performance through dual backpropagation of the language model and the retriever. Generally speaking, good retrieval strategies include 1️⃣ sparse retrieval and 2️⃣ dense retrieval. The types of RAG (retrieval-augmented generation) mainly include 1️⃣ frozen model RAG: these are ubiquitous across the industry and serve merely as proof of concept (POC). 2️⃣ semi-frozen model RAG: applies intelligent retrievers and attempts to adapt them in some way. It does not modify the LLM, only operates the retriever and combines them with the final output. 3️⃣ fully trainable RAG: end-to-end training is quite challenging, but if done correctly, it can provide optimal performance; however, it is certainly very resource-intensive.
Name clearedScan to Appreciate the AuthorLike the AuthorOther AmountArticlesNo articlesLike the AuthorOther AmountMinimum Appreciation ¥0Other AmountAppreciation Amount¥Minimum Appreciation ¥01234567890. , December 31, 2024 08:10 , ,