
 At the beginning of the technical report, the Deepseek team intuitively summarizes the current model’s performance with several numbers and two images. The model’s parameter count reaches 236B, and due to the small expert mixture characteristic, the activation parameters during inference are minimal, allowing for high inference speed. In terms of general capability, the model scored on the MMLU multiple-choice benchmark, achieving second place, with Deepseek-V2’s performance ranking just behind the 70B LLaMA3 among numerous open-source models, surpassing their previously released V1 67B non-MoE model. In terms of cost efficiency, compared to the dense model V1, the V2 model saves on training costs, reduces the KV-cache memory usage during inference, and improves the generated throughput to multiple times of the original. With the help of the YaRN optimized length extrapolation training method, the model’s context capability has been extended to 128k in size. Below, we will provide a detailed interpretation of the Deepseek-V2 model in conjunction with code and the technical report.
At the beginning of the technical report, the Deepseek team intuitively summarizes the current model’s performance with several numbers and two images. The model’s parameter count reaches 236B, and due to the small expert mixture characteristic, the activation parameters during inference are minimal, allowing for high inference speed. In terms of general capability, the model scored on the MMLU multiple-choice benchmark, achieving second place, with Deepseek-V2’s performance ranking just behind the 70B LLaMA3 among numerous open-source models, surpassing their previously released V1 67B non-MoE model. In terms of cost efficiency, compared to the dense model V1, the V2 model saves on training costs, reduces the KV-cache memory usage during inference, and improves the generated throughput to multiple times of the original. With the help of the YaRN optimized length extrapolation training method, the model’s context capability has been extended to 128k in size. Below, we will provide a detailed interpretation of the Deepseek-V2 model in conjunction with code and the technical report.
Core Optimization Analysis
Here, we will assist with the model architecture diagram from the official technical report to introduce the core optimization point of the model – Multi-head Latent Attention (MLA):
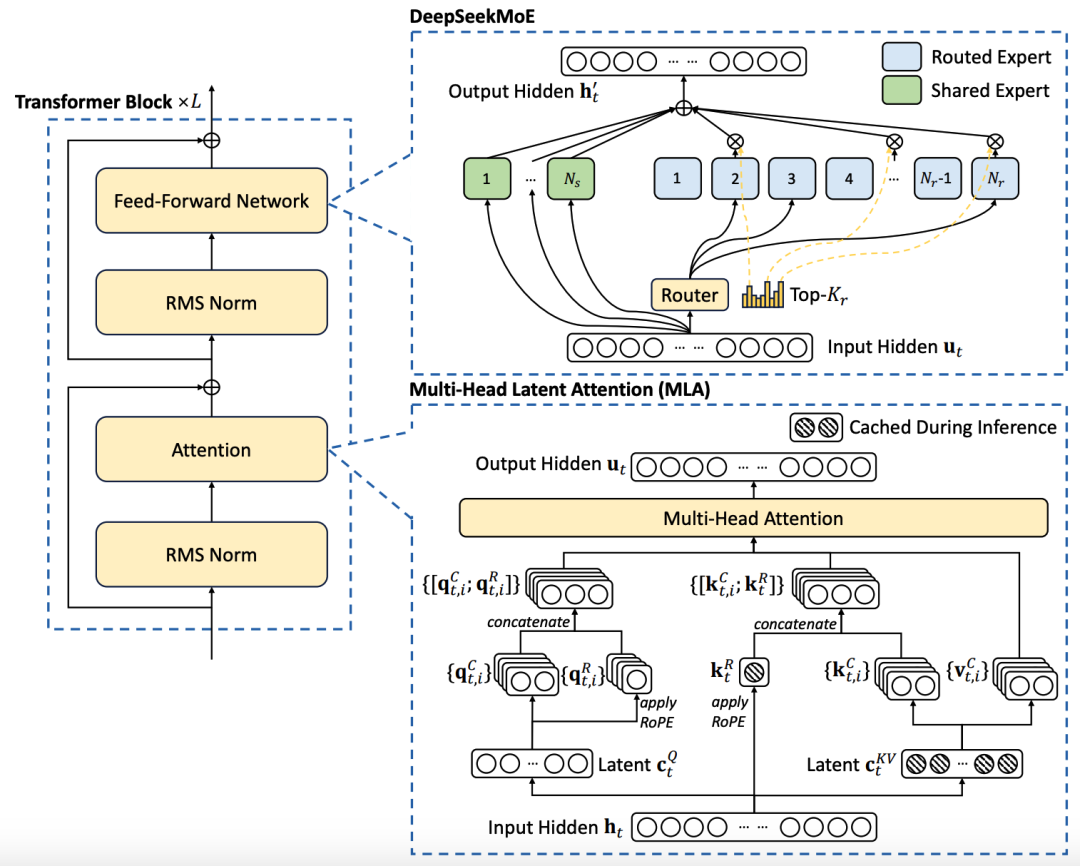
As shown in the bottom right of the above image, large models use kv-cache to accelerate model decoding. However, when the sequence is long, it can easily lead to insufficient memory issues. MLA addresses this by aiming to reduce kv cache usage.
MLA draws on the successful experience of LoRA to achieve more efficient low-rank inference than methods like GQA, which compress the matrix scale by copying parameters, while incurring minimal performance loss. First, let’s understand the role of each part through these lines in the configuration file:
"hidden_size": 5120,
"kv_lora_rank": 512,
"moe_intermediate_size": 1536,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64
When processing the hidden states computed from the previous layer (hidden_size=5120), the model first compresses the model’s q to the dimension of q_lora_rank (set to 1536), then expands to the output dimension of q_b_proj (num_heads * q_head_dim), and finally splits into q_pe and q_nope two parts, which we will see the effect of in the training section.
##### __init__ #####
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim # =192
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
##### forward #####
bsz, q_len, _ = hidden_states.size();
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)));
# q (bsz, q_len, 24576)
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2);
# q (bsz, q_len, 128, 192)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
);
#将最后一层 192 的hidden_states切分为 128 (qk_nope_head_dim) + 64 (qk_rope_head_dim)
For the kv matrix design, the model uses a kv compressed matrix design (only 576 dimensions), reducing dimensions during training and increasing dimensions during inference. When inferring the model, the amount that needs to be cached becomes compressed_kv, which is elevated to obtain the k, v calculation results through kv_b_proj.
##### __init__ #####
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
##### forward #####
compressed_kv = self.kv_a_proj_with_mqa(hidden_states);
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
);
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2);
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
);
So, why does Deepseek-V2 break down the entire computation process into q_nope, k_nope, k_pe, k_nope four parts? In the implementation of RoPE, if we want the model’s q, k to have positional properties, this is typically done, where m, n represent tokens at specific positions, and R can be referred to in RoPE:
The calculation of the output attention score becomes:
To save KV cache memory, Deepseek-V2 compresses the kv cache into the same small matrix and decompresses it later:
At this point, the calculation of the attention score can be written as:
We clarify that when applying rotary positional encoding, the standard implementation without decompression would directly update the original K states concatenated in front of K, while the matrix operations above use left multiplication followed by decompression. Since matrix multiplication is not commutative, using C as cache concatenated in mathematical terms is not equivalent under this matrix compression setting. To solve this issue, Deepseek-V2 designed two variables ending with pe to store the information of the rotary positional encoding, decoupling the information storage and the rotary encoding.

Next, we concatenate the parts responsible for storing information in q and k with the parts responsible for rotary encoding to perform standard attention calculations:
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
);
kv_seq_len = value_states.shape[-2];
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len);
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids);
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim);
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope;
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe;
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim);
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope;
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe;
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos}; # Specific to RoPE models
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs
);
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
);
attn_output = torch.matmul(attn_weights, value_states);
attn_output = attn_output.transpose(1, 2).contiguous();
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim);
attn_output = self.o_proj(attn_output);
Finally, the num_head dimension is flattened, and the output matrix yields the output hidden states for this layer of the model, which remains 5120 dimensions.
Architecture Interpretation
We gain a rough understanding of the model design through the model architecture diagram and configuration file. Deepseek’s model habitually uses a remote_code import format. After downloading the model, we can import the model weights through the official example and print out the model architecture.
DeepseekForCausalLM(
(model): DeepseekModel(
(embed_tokens): Embedding(102400, 5120)
(layers): ModuleList(
(0): DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=5120, out_features=32768, bias=False)
(o_proj): Linear(in_features=163840, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=12288, bias=False)
(up_proj): Linear(in_features=5120, out_features=12288, bias=False)
(down_proj): Linear(in_features=12288, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
(1-59): 59 x DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=5120, out_features=32768, bias=False)
(o_proj): Linear(in_features=163840, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMoE(
(experts): ModuleList(
(0-159): 160 x DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=1536, bias=False)
(up_proj): Linear(in_features=5120, out_features=1536, bias=False)
(down_proj): Linear(in_features=1536, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=3072, bias=False)
(up_proj): Linear(in_features=5120, out_features=3072, bias=False)
(down_proj): Linear(in_features=3072, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
)
(norm): DeepseekRMSNorm()
)
(lm_head): Linear(in_features=5120, out_features=102400, bias=False)
)
From the embedding layer’s dimensions, consistent with Gemma, LLaMA, and Qwen’s experience, Deepseek also selects a larger input vocabulary as the model’s input (this is feasible when data is sufficient and diverse). The benefit of this approach is a strong diversity in vocabulary, where multiple characters can exist within a single token, leading to high compression efficiency.
"num_hidden_layers": 60,
"num_key_value_heads": 128,
"num_experts_per_tok": 6,
"n_shared_experts": 2,
"n_routed_experts": 160
Through the above configuration analysis, the model has a total of 60 layers, with 128 attention heads, and a total of 160 gating experts. Each token calculation activates 6 gating experts while maintaining 2 shared experts, totaling 8 activated experts. After the embedding layer, consistent with Deepseek-MoE, it first goes through a shared large Decoder layer for the first computation. This layer’s attention calculation setup is fundamentally consistent with the subsequent 59 layers, with the only difference being that the MLP layer of this layer is fixed at the width of 8 experts, without additional gating parameters for activation. This setup is intended to store the common knowledge of language generation (including fluency, logic, etc.) here.
From the perspective of the overall architecture selection of the model, using pre-norm facilitates model training with sufficient depth, employing RMSNorm for normalization, and SiLU as the nonlinear activation function, while the attention matrix does not add bias (beneficial for flash-attention). These appear to be standard configurations adopted by major companies when training large models today.
Training
-
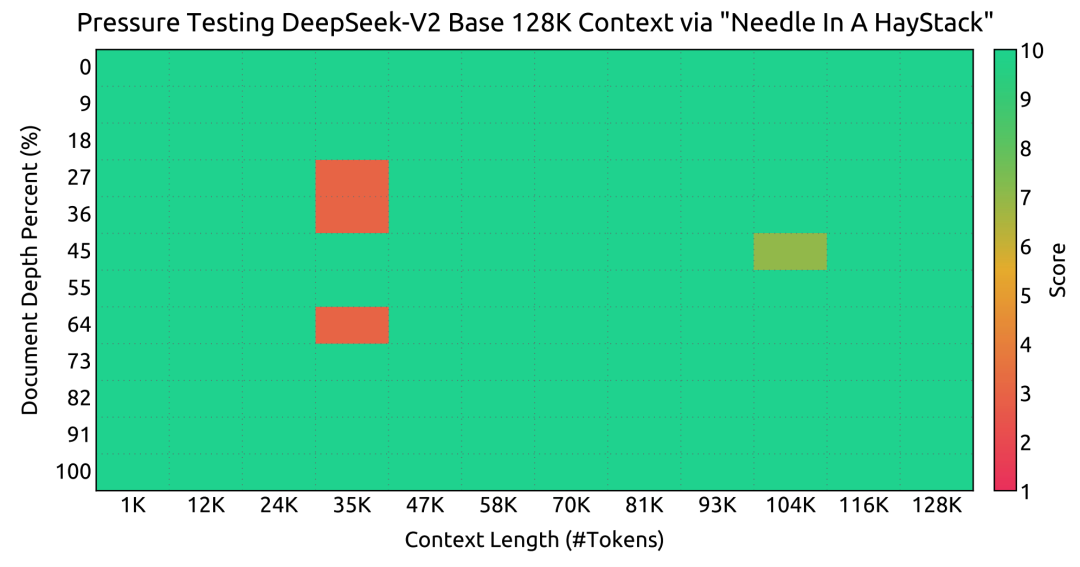
Decoupled Length Extrapolation under MLA: The model employs YaRN based on base conversion for length extrapolation training, performing well in needle-in-a-haystack testing.
-
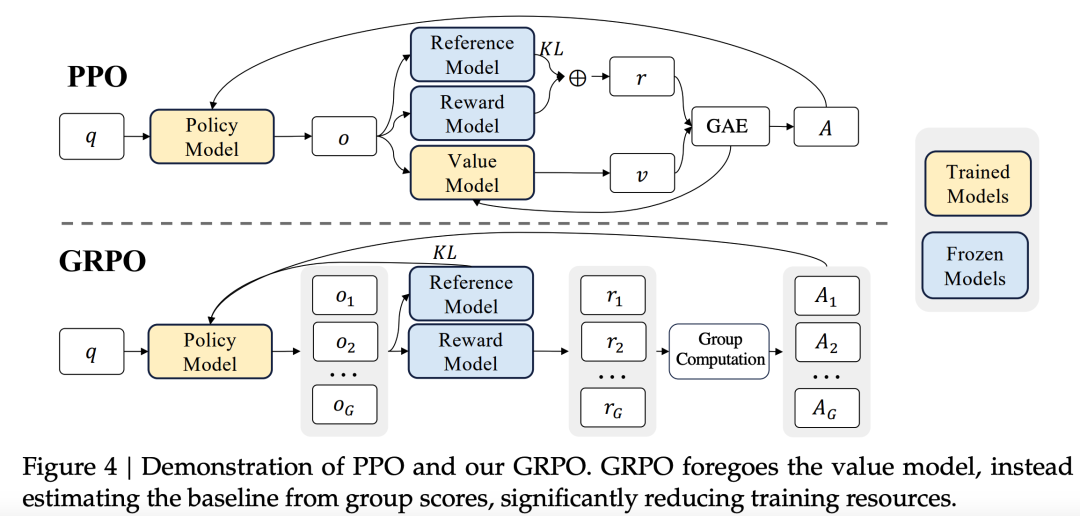
Model Alignment Training: The model uses dialogue data for SFT, focusing on instruction-following capabilities during evaluation. Significant effort was also put into the reinforcement alignment phase, with the GRPO algorithm, first seen in Deepseek-Math, being used for preference alignment training. This is a resource-optimized PPO training method that does not require updating the parameters of a Critic Model of the same size as the Policy Model (the aligned model) during training (Note: Reward Model still needs to be trained, but parameter updates are not made during alignment).

Comparison of GRPO and PPO
Infra
There are many enlightening points in the engineering optimization aspects (infra) of model training. The model uses pp=16 pipeline parallelism, with 160 experts distributed across ep=8 nodes in parallel (expert parallel), without adopting any form of tensor parallelism, reducing communication costs. It employs ZeRO-1 data parallelism to reduce optimizer state memory usage. The training facilities utilize NVLink and NVSwitch for intra-card communication, and InfiniBand switches for inter-node communication, with communication optimizations fully maximized. The parallel strategy is entirely implemented using self-developed HAI-LLM.
Additionally, Deepseek-V2 proposes a resource-aware expert load balancing method that ensures that experts are evenly distributed across several machines, preventing some machines from idling while others are overused. During training, given the ensemble characteristics of the model’s experts, all experts are completely symmetrical at the beginning of training. If no additional restrictions are applied, it is easy for pressure to be excessively borne by certain gating experts, causing frequent parameter updates on the machines where these experts are located, while the machines housing unused experts remain idle. Three dimensions of balancing optimization are proposed, integrating the cooperative properties of experts across different machines into the loss calculation:
-
Expert dimension balancing, to avoid overworking some experts and mixing knowledge:

-
Machine dimension balancing, aiming to distribute the 6 experts handling each token across different machines as much as possible:

-
Communication dimension balancing: Although machine dimension balancing has already been done, let’s take an example (ep_size=8):
[tok_0, tok_1, tok_2, ..., tok_n]
算 tok_0 专家所在的机器: 0,1,2,3,5,6
算 tok_1 专家所在的机器: 0,4,2,1,3,7
算 tok_2 专家所在的机器: 0,1,2,3,5,6
Even so, it is still insufficient. Although it ensures that each token’s experts are well-distributed, machines 0, 1, 2, and 3 are used too frequently, while machines 4, 5, 6, and 7 are underutilized. In simple terms, the ideal state is that during model parameter updates, the machines where experts reside should ideally appear 0 or 1 times in the above matrix, while the overall frequency of each machine in the entire matrix should align with the overall machine usage.

Integrating algorithms and engineering! This is another highlight of Deepseek, achieving optimal algorithm performance while fully utilizing the model ensemble structure design, and avoiding machine idling to realize optimal training efficiency.
Model Performance
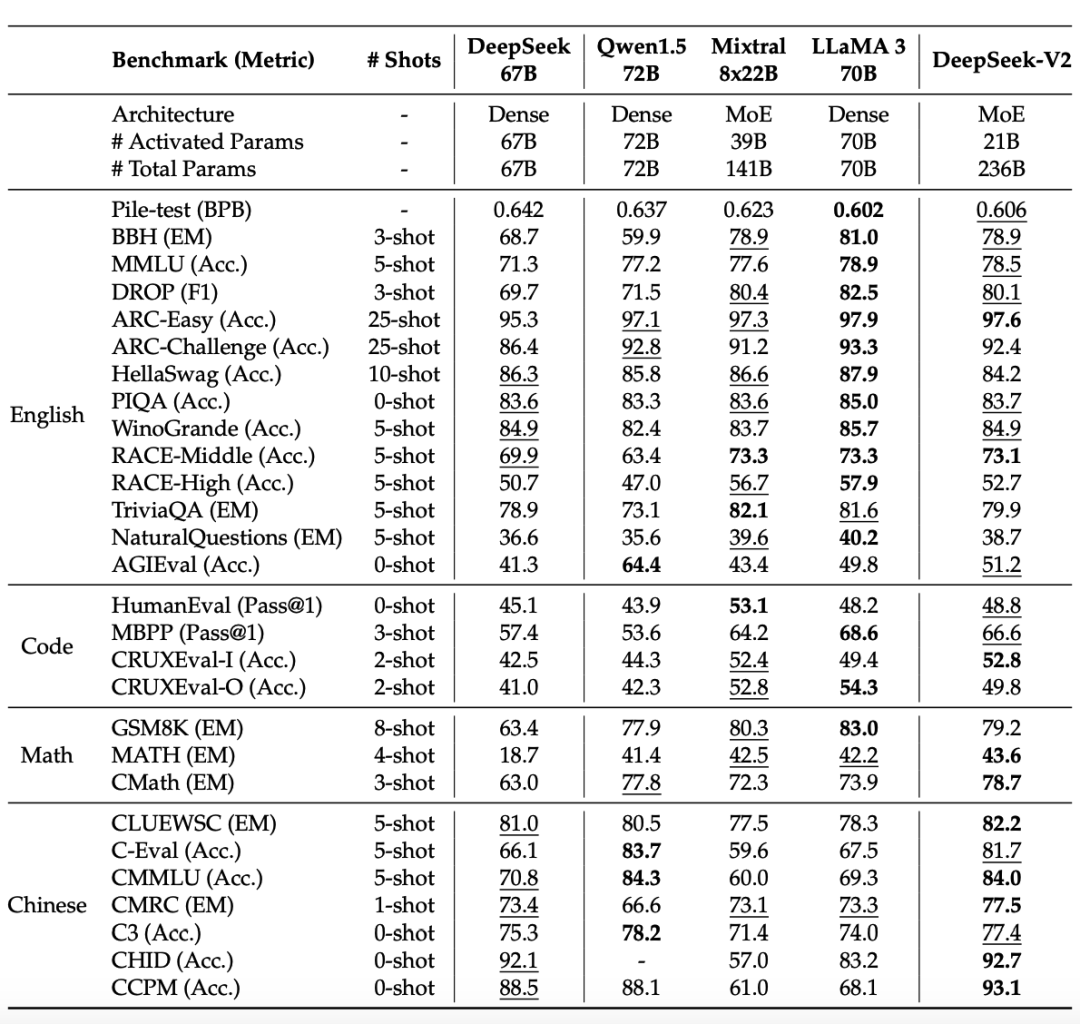
The base capability is very strong, likely due to the data optimization in model training, with the proportion of Chinese data being 1.12 times that of English data.
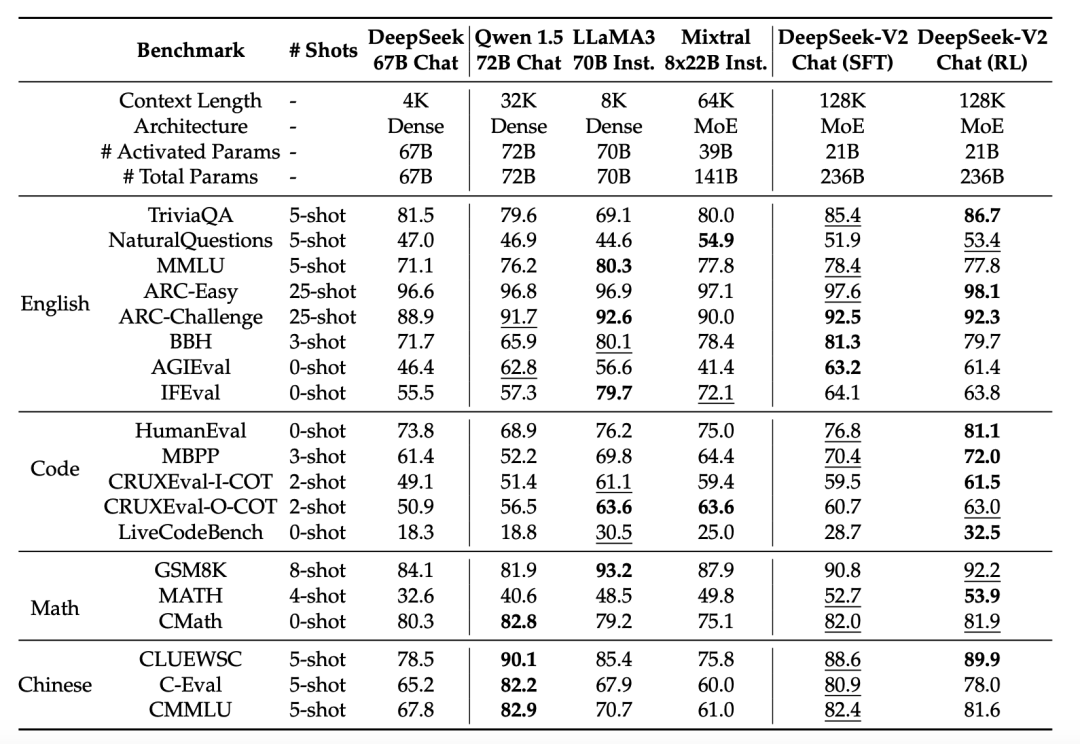
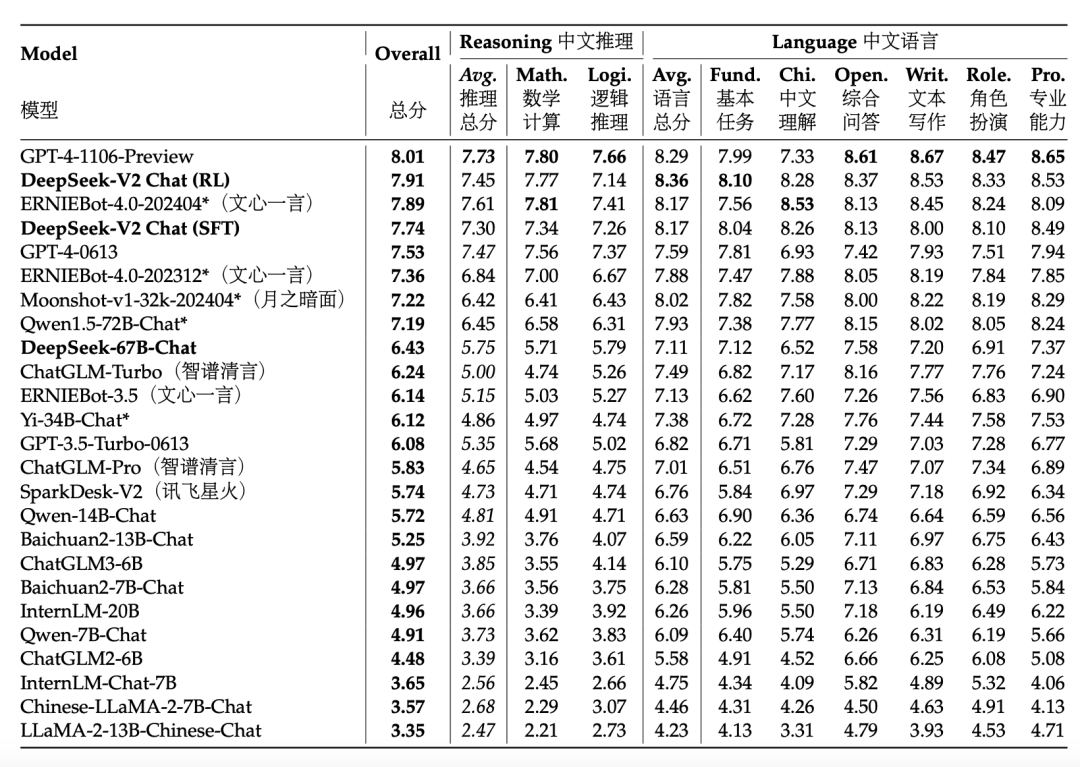
The instruction-following ability is excellent.
Discussion
In this section, we directly refer to the conclusions provided by Deepseek in the report.
Scale of Instruction Fine-tuning Data
DeepSeek-V2’s experiments show that if the experimental data for SFT is too small, for example, less than 10,000 entries, the model’s IFEval metric declines significantly. Moreover, a decrease in data volume cannot be compensated by merely increasing the model’s scale; the model must learn the key knowledge required for instruction following through a large volume of data.
Reinforcement Learning Alignment Tax
The researchers of Deepseek-V2 found that human preference alignment is beneficial for open-ended question answering, meaning that whether a large model is truly good is likely derived from this aspect.
However, this aspect can lead to alignment tax, specifically, aligning with human preferences to become a usable model may not be conducive to the model’s ranking. To mitigate the impact, Deepseek-V2 implemented more refined data processing and training strategy improvements, ultimately achieving a balance.
Online vs. Offline Preference Alignment
DeepSeek-V2 found that for reinforcement learning preference alignment, online methods significantly outperform offline methods.
Summary
Thanks to the outstanding researchers and engineering team, Deepseek-V2 deeply integrates widely validated training strategies in large language model training, combining YaRN for length extrapolation training, GRPO for efficient alignment, MLA, and mixture of expert allocation methods for model training, achieving extreme optimization in algorithms, engineering, and data.