
Introduction
From many people’s perspective, DeepSeek’s intensive release of multimodal open-source models before the Spring Festival aims to capitalize on the momentum to take away “ClosedAI”. However, when I checked GitHub, I found that the previous Janus Flow was already several months old, and this Pro version is merely an “ordinary” upgrade for them. It seems they just wanted to release it quickly before the holiday to avoid worrying about others stealing their research during the festive period (manual dog head emoji).
This article will summarize the following three technical reports:
-
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation -
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation -
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Introduction to Janus, JanusFlow, and JanusPro
Janus, in ancient Greek mythology, is the deity of beginnings and endings, gateways, and passages. He has two faces, one looking back at the past and the other gazing into the future. The Janus named by DeepSeek is a new autoregressive framework for unified multimodal understanding and generation. It addresses these issues by decoupling visual encoding into different paths while still employing a single, unified Transformer architecture in processing. This decoupling not only reduces the conflict between the visual encoder’s roles in understanding and generating but also enhances the overall flexibility of the framework.
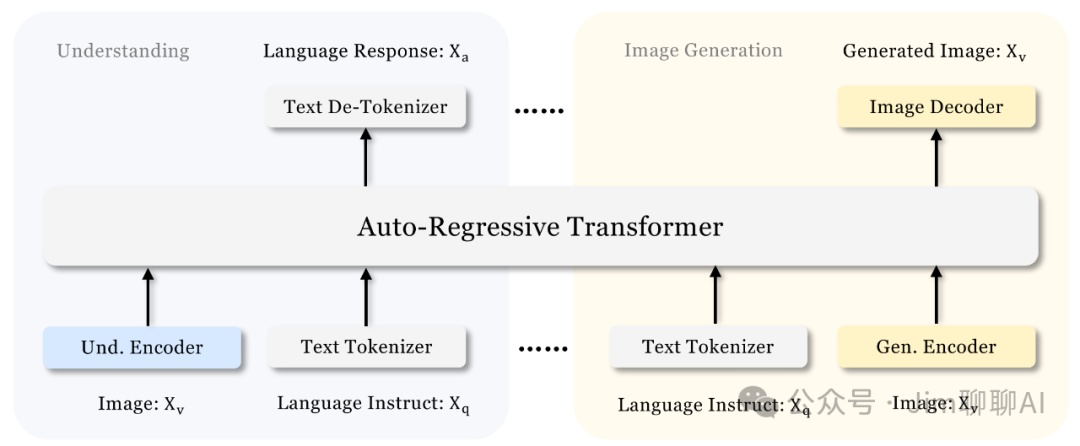

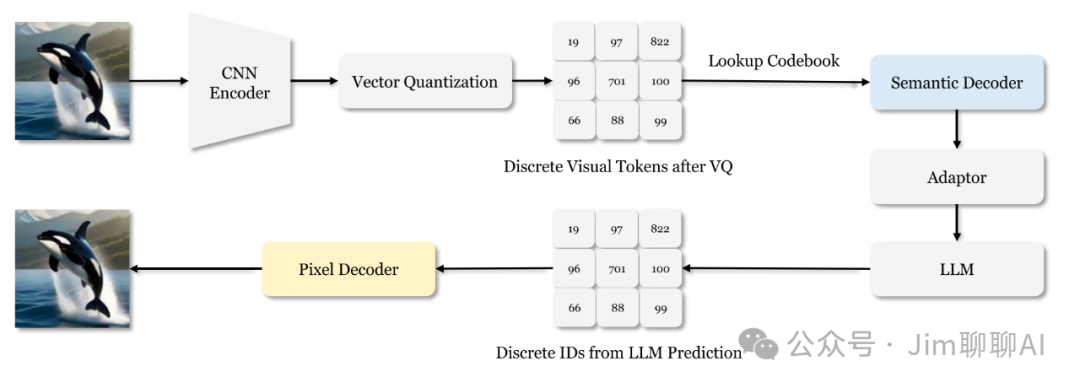
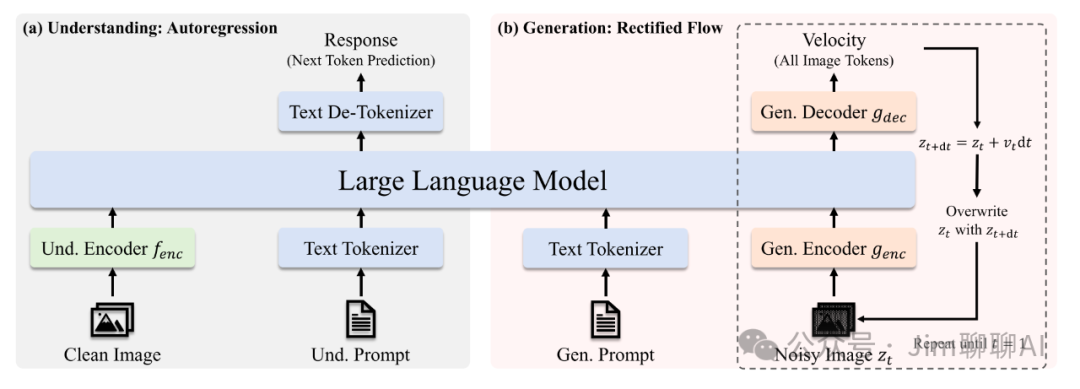
Janus Flow proposes a minimal framework that combines autoregressive language models with rectified flow, demonstrating that rectified flow can be directly trained within the framework of LLM without complex architectural modifications. Extensive experiments show that its performance in their respective fields is comparable to or even better than specialized models, and it significantly surpasses existing unified methods in standard benchmark tests. This work marks a step towards more efficient and versatile visual-language models.
Janus Pro is an advanced version of the previously mentioned Janus work. It mainly reflects in the following three aspects:
(1) Optimized training strategy; (2) Expanded training data; (3) Increased model scale.
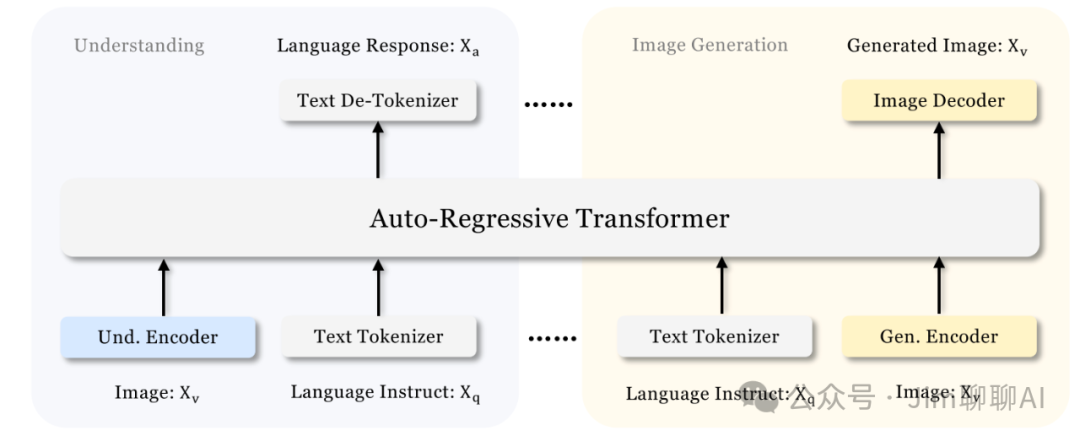
The overall network structure is consistent with Janus.
Training Methods
Janus
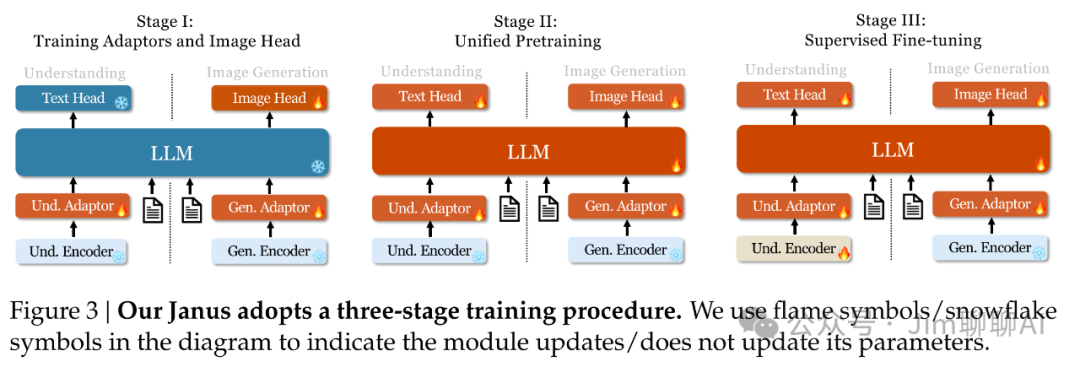
-
Stage One: This stage primarily aims to establish a basic connection between the LLM and image data, meaning allowing the LLM to initially adapt to the output of the image encoder; -
Stage Two: Joint training of semantic understanding and image generation heads. Here, we referenced pixelart, first training on imagenet 1k to help the network learn the basic information of pixel dependencies within images. -
Stage Three: A very standard SFT training, allowing the network to better understand instructions and improve dialogue capabilities.
Since we are training an autoregressive model, the loss directly uses the cross-entropy loss function:
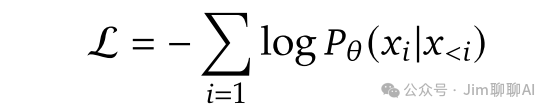
It is worth mentioning that DeepSeek aims to keep the training methods sufficiently simple, reducing unnecessary complexities in the training process, all in preparation for Janus Pro.
JanusFlow
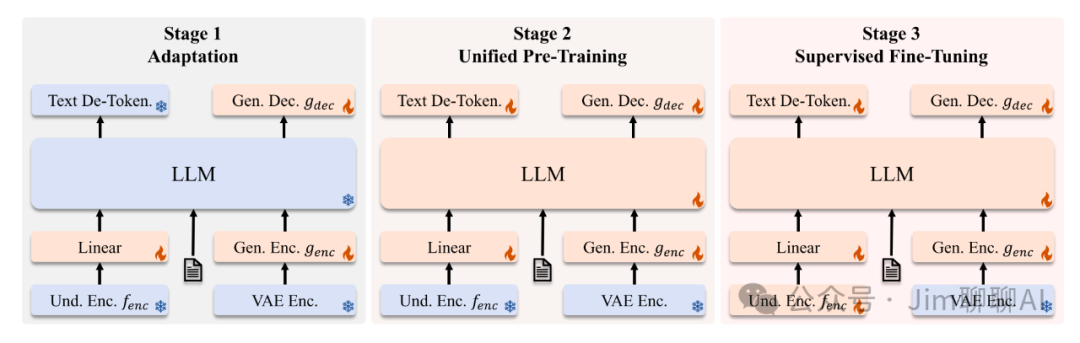
JanusPro
Like Janus, it also adopts a three-stage method. In order to improve upon Janus, the following enhancements were made:
-
The training time for the first stage is longer, meaning extended training time on the imagenet dataset. -
The second stage of training no longer uses imagenet data, instead directly using text-to-image data for training. -
The dataset ratio for the third stage has been reallocated, reducing text-to-image data, adjusting the ratio of “multimodal data” – “pure text data” – “text to image” from 7:3:10 to 5:1:4.
Comparison of Janus Series Versions

Comparison and Ablation Experiments
Several benchmark technical reports did not conduct detailed horizontal comparisons. From the perspective of JanusPro continuing to use the auto-regressive scheme, it seems that the rectified flow scheme is not superior, even if some metrics are better than the autoregressive scheme.
Janus
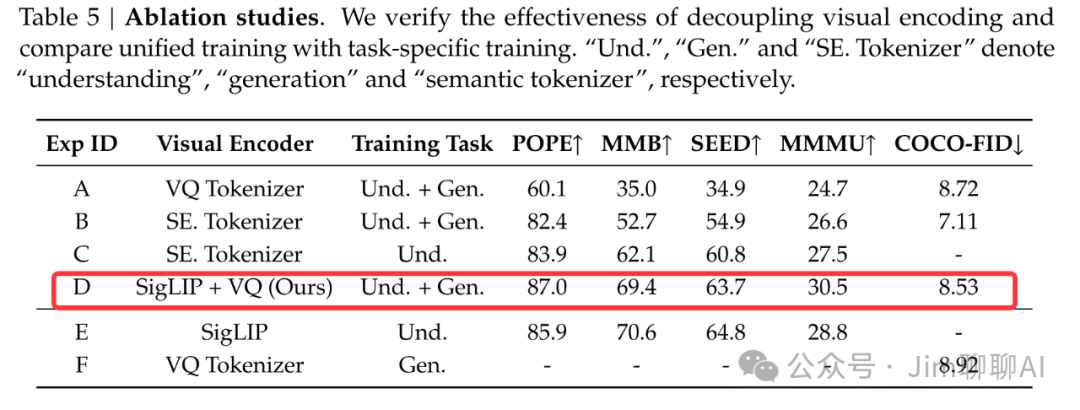
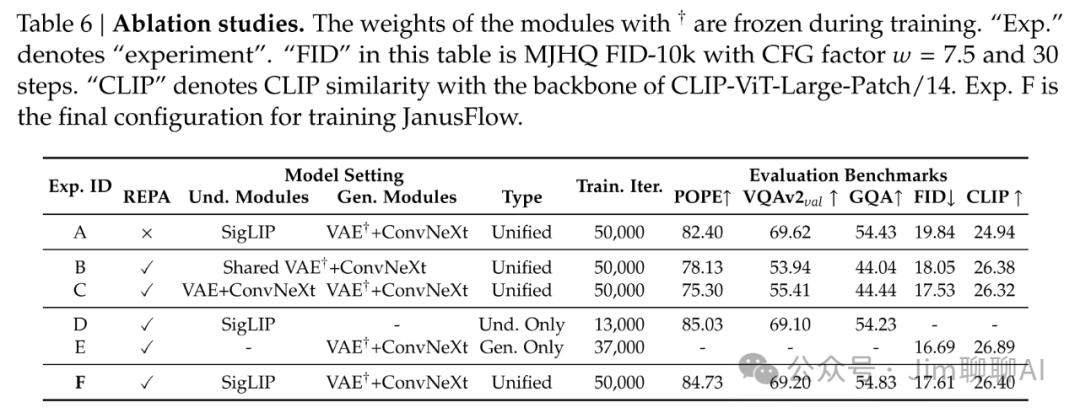
Experiment D, after adopting a task-separation network structure, significantly improves the overall performance of the network.
JanusFlow
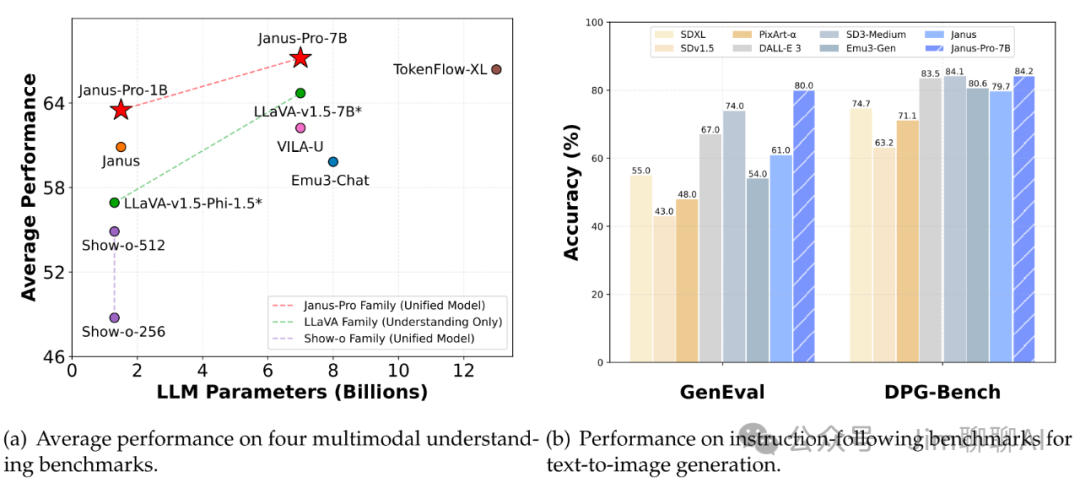
Janus Pro
Future Development Directions
The technical report mentions that although Janus has made considerable explorations in multimodal modeling, training methods, and engineering scaling, the resolution is too low, only 384×384, resulting in a lack of necessary details in the images produced for text-to-image tasks, indicating significant room for improvement in quality.
Additionally, from some publicly available experiments online, the quality of generated images of real person portraits is not very good. If better results are to be achieved in practical applications, it is likely that a larger volume of real data will need to be supplemented.
Conclusion
I particularly enjoy reading the technical reports written by DeepSeek researchers. They genuinely aim to contribute to open-source, with a very high information density, avoiding unnecessary fluff. I hope domestic large models will rise from this. Today is the first day of the Lunar New Year, and I wish everyone who reads this a Happy New Year! May those who like, share, and follow have abundant wealth!