
Deep Reconstruction

Professor Zhang Yi, a doctoral supervisor from Sichuan University, once introduced the basic principles and classic methods of CT reconstruction, as well as the principles and current status of CT reconstruction.
In this issue, he will take us to learn about his latest IEEE TMI paper on CT reconstruction using deep learning, which is equally applicable to other computational imaging fields.


Deep Learning Overview
Deep learning is a branch of machine learning, a concept proposed by Hinton et al. in 2006, which originated from the concept of artificial neural networks proposed in 1943.
Since 2006, deep learning has received significant attention from research institutions and the industry. The core of deep learning is feature learning, which solves the important problem of manually designing feature extraction operators by obtaining hierarchical feature information through layered networks.
Deep learning frameworks include several important network structures, mainly Convolutional Neural Networks (CNN), Autoencoders, Restricted Boltzmann Machines (RBM), Deep Belief Networks (DBN), and Recurrent Neural Networks (RNN).
In terms of brain vision, the visual cortex of the brain is hierarchical. As shown in Figure 1, when the human eye observes an image, it first extracts some edge features, then combines these edges into local features, and at the highest level of the brain, integrates these local features into overall features, allowing humans to accurately distinguish different objects.

Figure 1: Brain Visual Processing
The CNN network draws on the process of human information processing, using multi-layer convolutional networks to extract image features.
In shallow networks, convolution kernels can only extract shallow edge features. As the network depth increases, these edge features will gradually be combined into high-level features, which can be effectively used for recognition tasks.
CNN not only achieves local receptive fields, mimicking the human mode of information reception and processing, but also reduces the number of parameters, lowering the network complexity. Therefore, it is widely used in image problems.
Deep Reconstruction (DeepRecon)

In the problem of CT image reconstruction based on deep learning, several works have been published.
Below we will mainly introduce two of our research group’s papers on deep reconstruction. They are the application of deep learning for low-dose CT image denoising as a post-processing method and the method of network unfolding for sparse angle CT iterative reconstruction.
First Architecture: RED-CNN

Autoencoder
Autoencoder (AE) is a type of deep learning framework used to learn compressed features of images, making the output equal to the input. It consists of two parts: the encoder and the decoder. Our first work combines the autoencoder with a residual convolutional network to process low-dose CT images.
Architecture and Principles
Figure 2 shows our network model, which we call the Residual Encoder-Decoder Convolutional Neural Network (RED-CNN).
This network is an end-to-end network with low-dose CT images as input, and the corresponding labels are normal-dose CT images.
The network consists of 10 layers in total, with the first five layers as encoding layers, each consisting of convolutional layers and ReLU layers, and the last five layers as decoding layers, each consisting of deconvolutional layers and ReLU layers. To avoid loss of detail, we did not add pooling layers.
In the 10-layer network, we added 3 skip connections, making the entire network similar to the structure of a residual network, which can avoid issues like vanishing or exploding gradients, making the training process more stable. It is worth noting that in the 3 skip connections, we first sum the learned residuals with the skip units, then pass through the ReLU layer, which removes the non-negative constraint of the residual, making the restored image more accurate.
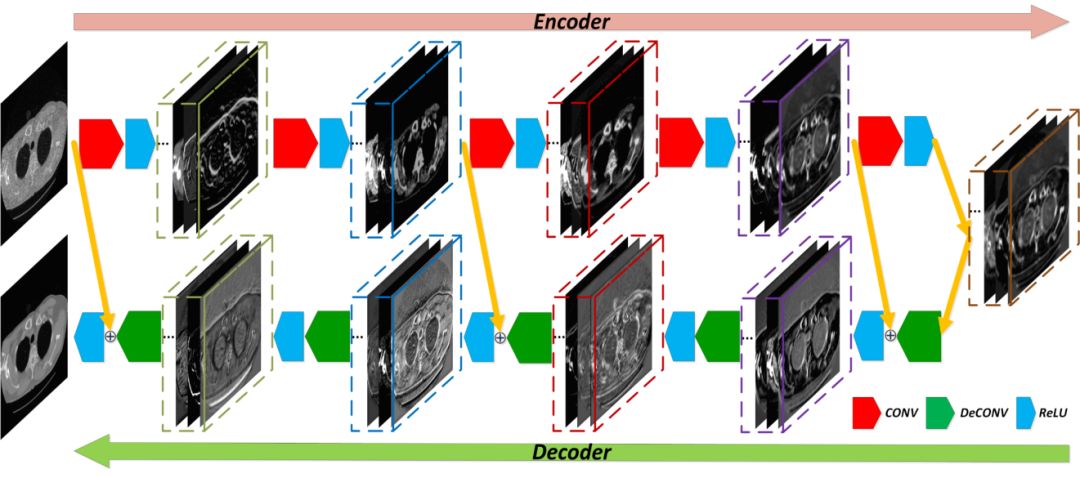
Figure 2: RED-CNN Architecture
Results
In the paper, we conducted a large number of comparative experiments. Here we only show a set of reconstruction results for thoracic data. As shown in Figure 3, compared to normal-dose CT images, low-dose CT images contain a lot of noise, and all methods can effectively remove noise from low-dose CT images.
The blue arrows indicate some vascular details, and the images obtained by RED-CNN restored these details well, while the images reconstructed by other methods lost some details to varying degrees.
In the areas marked by the red arrows, the comparative method KAIST-Net produced some artifacts that were not present in the normal-dose images.
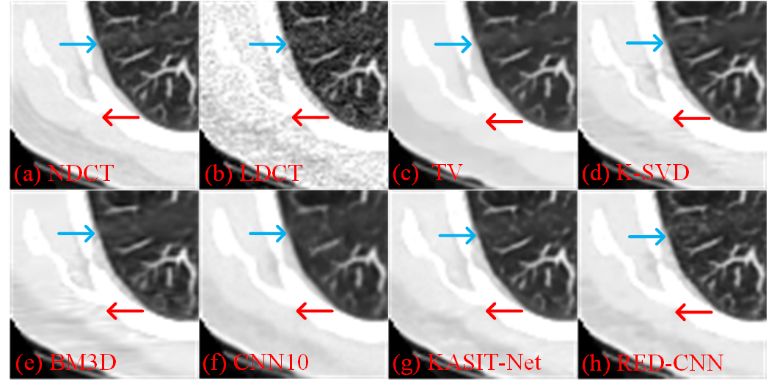
Figure 3: Comparison of Results
Second Architecture: LEARN
Idea
Compared to post-processing methods, iterative reconstruction methods theoretically yield more accurate results because they utilize real projection data during the iterative process. Therefore, our other work combines deep learning with iterative reconstruction methods.
In traditional sparse CT reconstruction, due to the ill-posed nature of the problem, regularization terms need to be artificially introduced. To construct good regularization terms, feature engineering and prior knowledge are often required. Moreover, these methods require manually setting the weights of the regularization terms, which may vary for different images, making their applicability not very strong.
Our idea is to use neural networks to simultaneously learn these regularization terms and parameters, training to obtain regularization terms and parameters based on data. We fix the number of iterations, then unfold the network at each iteration, resulting in the LEARN (Learned Experts’ Assessment-Based Reconstruction Network) framework shown in Figure 4.
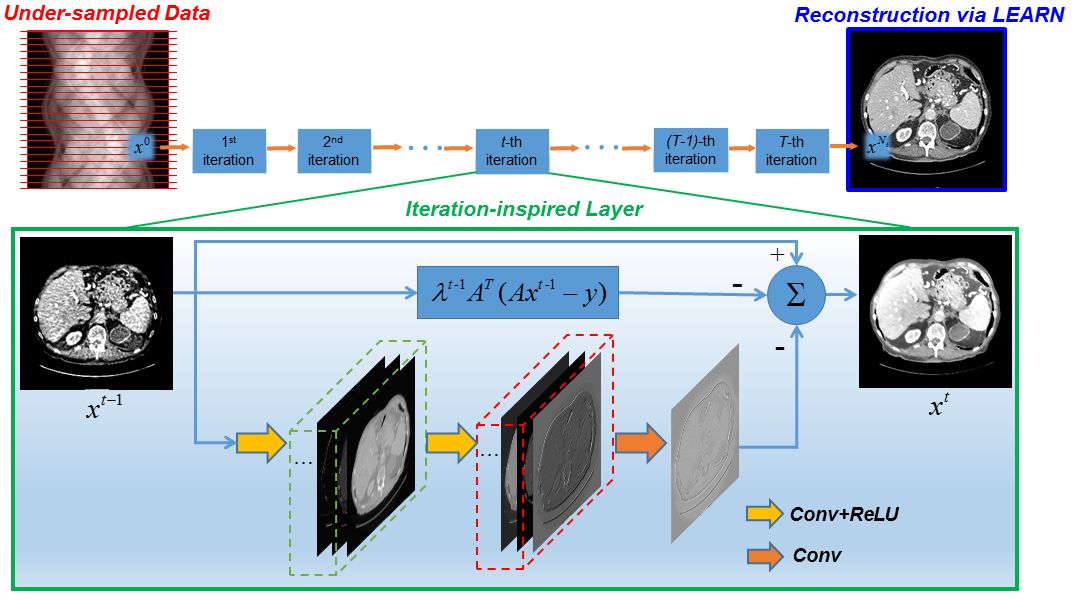
Figure 4: LEARN Architecture
Results
We used data from 10 patients from the Mayo Dataset, with each patient having 25 images, totaling 250 images. Data from 8 patients were used as the training set, and data from 2 patients as the test set.
During training, the number of iterations was set to 50, with each block containing a three-layer CNN, totaling 150 layers. The size of the convolution kernels was set to 5×5, with the first two layers having 48 kernels and the third layer having 1 kernel. The loss function used for training was MSE, optimized using the Adam algorithm.
To compare network performance, we selected ASD-POCS, Dual Dictionary Learning (Dual-DL), Total Generalized Variation based Penalized Weighted Least-Squares (PWLS-TGV), Gamma Regularization, and FBPConvNet as comparative methods. The first four methods are iterative reconstruction methods, while FBPConvNet is a post-processing deep learning-based method.
Figure 5 shows a local magnification of reconstruction results for abdominal data, where (a) is the normal-dose CT image. (b) is the result obtained by the FBP algorithm, and (c) – (g) are the images obtained from 5 comparative methods, while (h) is the result reconstructed by LEARN.
The areas marked with red arrows indicate enhanced blood vessels, and the blue arrows point to a suspected lesion. We can see that the results obtained by the LEARN method show clearer structures compared to other methods.

Figure 5: Comparison of LEARN’s Results
Conclusion

This article mainly introduces the deep reconstruction work of our research group. The results show that deep learning-based CT image reconstruction methods outperform traditional reconstruction algorithms in terms of image quality. Therefore, in the future, the connection between deep learning and medical image reconstruction will become increasingly close.
In our future work, we will also strive to promote the integration of deep learning and the field of CT images, introducing the latest technologies in deep learning development, applying deep learning-based methods to clinical applications, and attempting to solve other medical imaging problems, accelerating the development process in the field of medical imaging.
[References]
[1] Hu Chen, Yi Zhang*, Mannudeep K. Kalra, Feng Lin, Yang Chen, Peixi Liao, Jiliu Zhou, and Ge Wang. Low-dose CT with a residual encoder-decoder convolutional neural network. IEEE Transactions on Medical Imaging, pp. 2524-2535, vol. 36, no. 12, 2017.
[2] Hu Chen, Yi Zhang*, Yunjin Chen, Junfeng Chen, Weihua Zhang, Huaiqiang Sun, Yang Lv, Peixi Liao, Jiliu Zhou, and Ge Wang. LEARN: Learned experts’ assessment-based reconstruction network for sparse-data CT. IEEE Transactions on Medical Imaging, pp. 1333-1347, vol. 37, no. 6, 2018.