
Source: Reprinted from Lei Feng Network
Original Title: The Evolution of Speech Recognition Modeling Technology Under the Wave of AI
Speech recognition modeling is an indispensable part of speech recognition, as different modeling techniques often mean different recognition performance. Therefore, this is a key optimization direction for various speech recognition teams. Because of this, speech recognition models have emerged in an endless stream, with language models including N-gram, RNNLM, etc., while acoustic models include HMM, DNN, RNN, and more…
In simple terms, the task of the acoustic model is to describe the physical changes in speech, while the language model expresses the linguistic knowledge contained in natural language. This article is shared by Chen Wei, the head of the speech technology department at the Sogou Speech Interaction Center, to help clarify the mainstream recognition modeling context and the underlying thoughts behind it.
The Sogou Zhiyin engine is an intelligent voice technology independently developed by Sogou, focusing on natural interaction. This technology integrates multiple functions such as speech recognition, semantic understanding, voice interaction, and service provision. It can not only listen and speak but also understand and think. This article will explain using the speech recognition modeling technology employed in the Zhiyin engine.
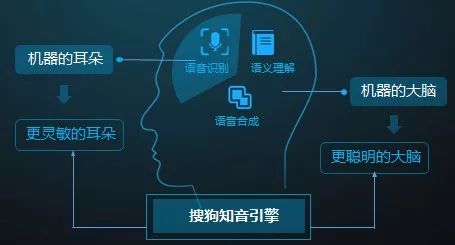
Figure 1 Sogou Zhiyin Engine
Basic Concepts
1
Speech Frame
Considering the short-term stationary characteristics of speech, the speech signal must undergo windowing and framing operations during front-end signal processing. Recognition features are extracted frame by frame, as shown in Figure 2. (Editor’s note: The speech features are extracted frame by frame for acoustic model modeling.)
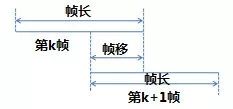
Figure 2 Division of Speech Frames
2
Speech Recognition System
After front-end signal processing and endpoint detection, speech features are extracted frame by frame. Traditional feature types include MFCC, PLP, FBANK, etc. The extracted features are sent to the decoder, which finds the most matching word sequence as the recognition result output under the guidance of the acoustic model, language model, and pronunciation dictionary. The overall process is shown in Figure 3. The recognition formula is shown in Figure 4, where the acoustic model mainly describes the likelihood probability of features under the pronunciation model; the language model mainly describes the connection probability between words; the pronunciation dictionary mainly completes the conversion between words and sounds, where the acoustic model modeling unit generally chooses the triphone model. Taking “Sogou Speech” as an example:
sil-s+ou1 s-ou1+g ou1-g+ou3 g-ou3+y ou3-y+u3 y-u3+y u3-y+in1 y-in1+sil
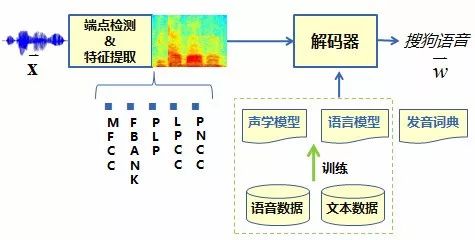
Figure 3 Speech Recognition System Process
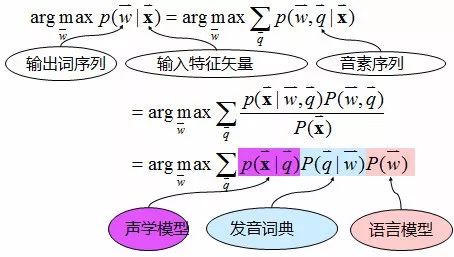
Figure 4 Principles of Speech Recognition
It is important to note that the input feature vector X represents the characteristics of the speech.
Mainstream Acoustic Modeling Technologies
In recent years, with the rise of deep learning, the acoustic model HMM (Hidden Markov Model), which has been used for nearly 30 years, has gradually been replaced by DNN (Deep Neural Network). The model accuracy has made significant advancements. Overall, acoustic modeling technology has undergone noticeable changes in three dimensions: modeling units, model structure, and modeling processes, as shown in Figure 5:
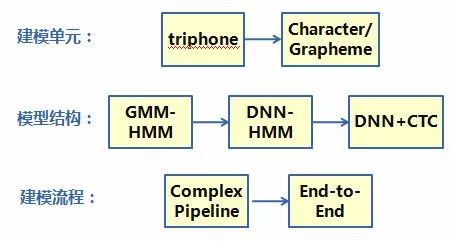
Figure 5 Summary of Acoustic Modeling Evolution
Among them, the powerful feature learning ability of deep neural networks has greatly simplified the feature extraction process and reduced the dependence of modeling on expert experience. Therefore, the modeling process has gradually shifted from a previously complex and multi-step process to a simple end-to-end modeling process. The impact of this shift is that the modeling units have gradually evolved from state and triphone models to larger units such as syllables and characters, and the model structure has transitioned from the classic GMM-HMM to DNN+CTC (DNN refers to Deep Neural Network), with the intermediate state being a hybrid model structure of DNN-HMM.
1
HMM
HMM was first established in the 1970s. In the 1980s, it spread and developed to become an important direction in signal processing and has now been successfully applied in speech recognition, behavior recognition, character recognition, and fault diagnosis.
Specifically, the classic HMM modeling framework is as follows:
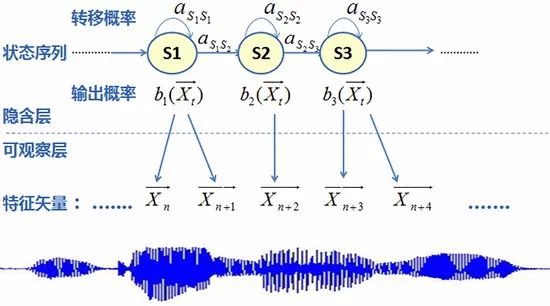
Figure 6 HMM Modeling Framework
In this framework, the output probability is modeled using a Gaussian Mixture Model (GMM), as follows:
2
DNN-HMM
In 2012, Microsoft’s Deng Li and Yu Dong introduced Feed Forward Deep Neural Networks (FFDNN) into acoustic model modeling, replacing the output layer probability of GMM-HMM with the output layer probability of FFDNN, leading to the trend of DNN-HMM hybrid systems. Many researchers have used FFDNN, CNN, RNN, LSTM, and various other network structures to model output probabilities, achieving good results, as shown in Figure 7.

Figure 7 DNN-HMM Hybrid Modeling Framework
In the DNN-HMM modeling framework, input features use the method of concatenating frames from the left and right of the current frame to model the long-term correlation of time series signals. The model output maintains the tri-phone shared state (senone) commonly used in GMM-HMM. In continuous speech recognition with a large vocabulary in Chinese, the number of states is generally set around 10,000, as shown in Figure 8.
Figure 8 DNN-HMM Modeling Process
3
FFDNN
The model structure of FFDNN is as follows:
Figure 9 FFDNN Modeling Process
4
CNN
Editor’s note: In fact, CNN was originally only applied to image recognition and was not used in speech recognition systems until 2012.
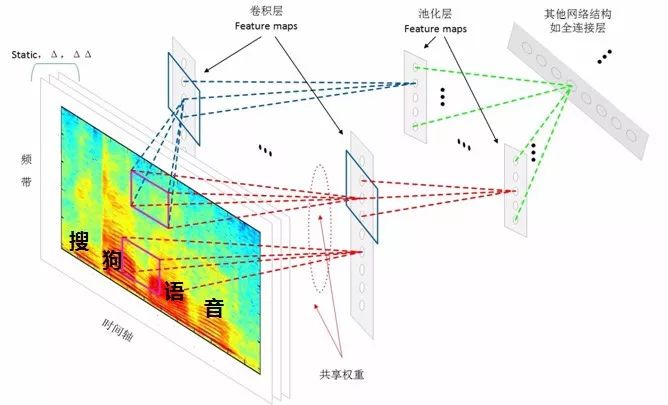
Figure 10 CNN Modeling Process
5
RNN and LSTM
The phenomenon of co-articulation in speech indicates that the acoustic model needs to consider the long-term correlation between speech frames. Although the DNN-HMM mentioned above models contextual information by concatenating frames, the number of concatenated frames is limited, and the modeling capability is weak. Therefore, RNN (Recurrent Neural Network) was introduced to enhance the long-term modeling capability. The input of the RNN hidden layer, in addition to receiving the output from the previous hidden layer, also receives the output from the previous time step’s hidden layer as the current input. Through the feedback of the RNN hidden layer, long-term historical information is retained, greatly enhancing the model’s memory capability. The temporal characteristics of speech are also well described through RNN. However, the simple structure of RNN can easily lead to gradient vanishing/explosion issues during model training using BPTT (Backpropagation Through Time). Therefore, LSTM (Long Short-Term Memory) was introduced based on RNN. LSTM is a special type of RNN that uses the special structure of cells and three gated neurons to model long-term information, solving the gradient issues that occur in RNN. Practices have also proven that LSTM’s long-term modeling capability is superior to that of ordinary RNN.
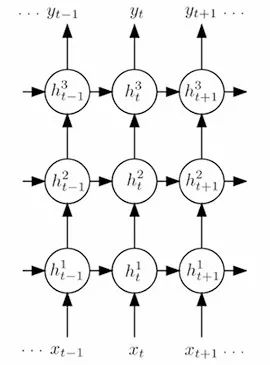
Figure 11 RNN Structure
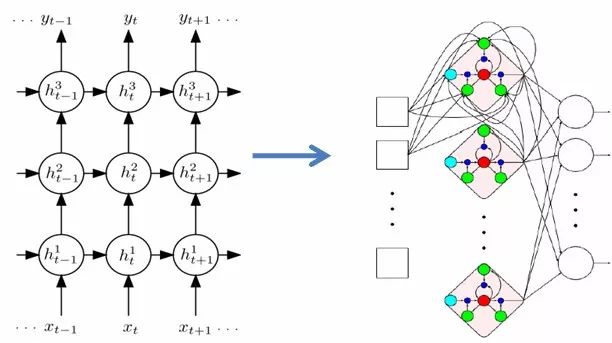
Figure 12 RNN to LSTM
6
CTC
The above modeling techniques require a condition during model training, which is that each frame in the training data must have a corresponding label pre-determined, i.e., the sequence of DNN output states must be of equal length to the sequence of training features and labels. To obtain the labels, existing models must be used to force-align the training data sequence and label sequence. However, the preparation of labels during big data training is time-consuming, and the accuracy of the model used for alignment often has deviations, leading to potential errors in the labels used for training. Therefore, the CTC (Connectionist Temporal Classification) criterion was introduced to solve the problem of unequal lengths between the label sequence and feature sequence. It automatically learns the model boundaries in speech features through the forward-backward algorithm. This criterion can be directly used for end-to-end model modeling when combined with neural networks used for temporal modeling (such as LSTM), revolutionizing the HMM framework that has been used for nearly 30 years in speech recognition.
The CTC criterion introduces a blank category to absorb the confusion within pronunciation units, further highlighting the differences between models, thus CTC exhibits a very significant spike effect. Figure 13 demonstrates the output probability distribution after recognizing the phrase “Sogou Speech” using the triphone-lstm-ctc model. Most areas are absorbed by the blank, and the recognized triphone corresponds to an obvious spike.
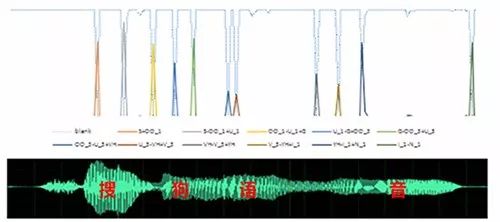
Figure 13 Demonstration of CTC Spike Effect
It is expected that end-to-end recognition technologies based on CTC or those that reference the CTC concept (such as LFMMI) will gradually become mainstream, and the HMM framework will be gradually replaced.
Other Modeling Technologies
1
Language Modeling Technology
Currently, RNNLM technology has gradually been introduced into speech recognition. By modeling longer historical information, RNNLM has significantly improved recognition performance compared to the traditional N-Gram technology. However, considering large vocabulary speech recognition, completely replacing N-Gram would lead to a significant increase in computational load and time. Therefore, in the Zhiyin engine, RNNLM is used to reorder the N-best candidate list from N-Gram recognition outputs.
2
Voice Wake-Up Technology
Currently, the Zhiyin engine uses a DNN-based end-to-end wake-up word modeling method for fixed wake-up words, as follows:
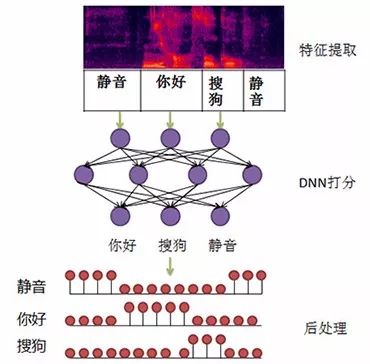
Figure 14 End-to-End Voice Wake-Up Process
This method has achieved a very low false wake-up rate, but it also has obvious drawbacks: the wake-up word cannot be customized. Therefore, in the Zhiyin engine, we use DNN to extract Bottleneck Features for training HMM-based wake-up models, which have also achieved good results compared to traditional MFCC-based methods.
About the Future
Although the modeling capability of speech recognition has significantly improved, issues such as far-field, noise, accents, and pronunciation habits (elision) still exist. I strongly agree with Andrew Ng’s statement that moving from 95% accuracy to 99% may seem like only a 4% difference, but it could change the way people interact, turning infrequently used interactions into frequently used ones.
Currently, the cost of acquiring raw speech data is decreasing, and the industry is using tens of thousands of hours of labeled data for model updates. In the future, it will be possible to have hundreds of thousands of training data. How to efficiently use this data involves the following considerations:
-
Data Screening Level: Using unsupervised, weakly supervised, and semi-supervised data for training, while more efficiently selecting data for labeling. The Zhiyin engine is already using active learning methods for data screening;
-
Computational Level: Efficiently completing model training on super-large data using heterogeneous computing clusters, and the computational capability has expanded from offline training to online testing;
-
Model Level: Learning from super-large data requires more capable models. Currently, composite structures based on multiple model architectures (such as CNN-LSTM-DNN) have proven feasible, and subsequent sequence learning frameworks based on Encoder-Attention-Decoder are also being integrated with speech recognition.
Although speech recognition can currently achieve high accuracy, the leap from 95% to 99% or even 100% is a process from quantitative change to qualitative change, and it is a crucial factor in determining whether speech interaction can become the mainstream interaction method. However, some old problems in speech recognition still exist, and the technology has not yet fully solved them. Therefore, product innovation beyond technology is also very important, as it can effectively compensate for the deficiencies in accuracy.
Taking the Zhiyin engine as an example, it provides a solution for speech error correction. For errors that occur during recognition, users can use natural speech to correct them. For example, if a user wants to say “My name is Chen Wei” but it is recognized as “My name is Chen Wei,” saying “Ear Dong Chen Wei’s Wei” will correct the recognition result. Currently, with multiple product iterations, speech correction has achieved an 80% success rate and has been integrated into the Zhiyin engine’s voice interaction. It is also integrated with the Sogou iOS input method for voice correction capabilities.
Editor’s Note: Summarizing the process of the speech recognition system, the acoustic modeling and language modeling parts are the most critical links. Currently, deep learning-based modeling technology has elevated model performance to a new stage. However, as Chen Wei mentioned, although the accuracy of speech recognition has reached a high level, there is still significant room for improvement. What kind of models will emerge in the future? Let us look forward to the new results of artificial intelligence, especially deep learning technology.
Guest Introduction:

Chen Wei
Chen Wei is an expert researcher at Sogou’s desktop division and the head of the speech technology department at the Speech Interaction Center. He is responsible for the research and development of several technologies, including Sogou speech recognition, speech synthesis, music retrieval, voiceprint recognition, and handwriting recognition. He is committed to improving the quality of speech interaction through technological and product innovations to provide users with a high-quality speech experience.


Disclaimer: This WeChat reprinted article is for non-commercial educational and research purposes and does not imply support for its views or confirm the authenticity of its content. The copyright belongs to the original author. If the reprinted article involves copyright issues, please contact us immediately, and we will change or delete related articles to protect your rights!