Skip to content
Report by Machine Heart
Contributors: Racoon, Du Wei, Zhang Qian
Since its introduction in 2017, the Transformer has swept the entire NLP field, with popular models like BERT and GPT-2 adopting Transformer-based architectures.Since it is so effective, why not apply it to CV?Recently, researchers at Facebook AI have attempted this by applying Transformers to object detection tasks, achieving results comparable to Faster R-CNN.
In recent years, the Transformer has become a very popular architecture in deep learning, relying on a simple yet powerful mechanism—the attention mechanism—that allows AI models to selectively focus on certain parts of the input, making inference more efficient.
Transformers have been widely used for processing sequential data, especially in natural language processing fields such as language modeling and machine translation. Additionally, they have applications in speech recognition, symbolic mathematics, and reinforcement learning. Surprisingly, the computer vision field has not yet been dominated by Transformers.
To fill this gap, researchers at Facebook AI introduced a visual version of the Transformer—Detection Transformer (DETR)—for object detection and panoptic segmentation. Compared to previous object detection systems, DETR’s architecture has undergone fundamental changes. It is the first object detection framework to successfully integrate Transformers as a central building block of the detection pipeline.
In terms of performance, DETR can compete with current SOTA methods, but its architecture is greatly simplified. Specifically, researchers compared DETR with the Faster R-CNN baseline method on the COCO object detection dataset, finding that DETR outperformed Faster R-CNN in detecting large objects, but performed worse on small objects, providing new directions for future improvements of DETR.
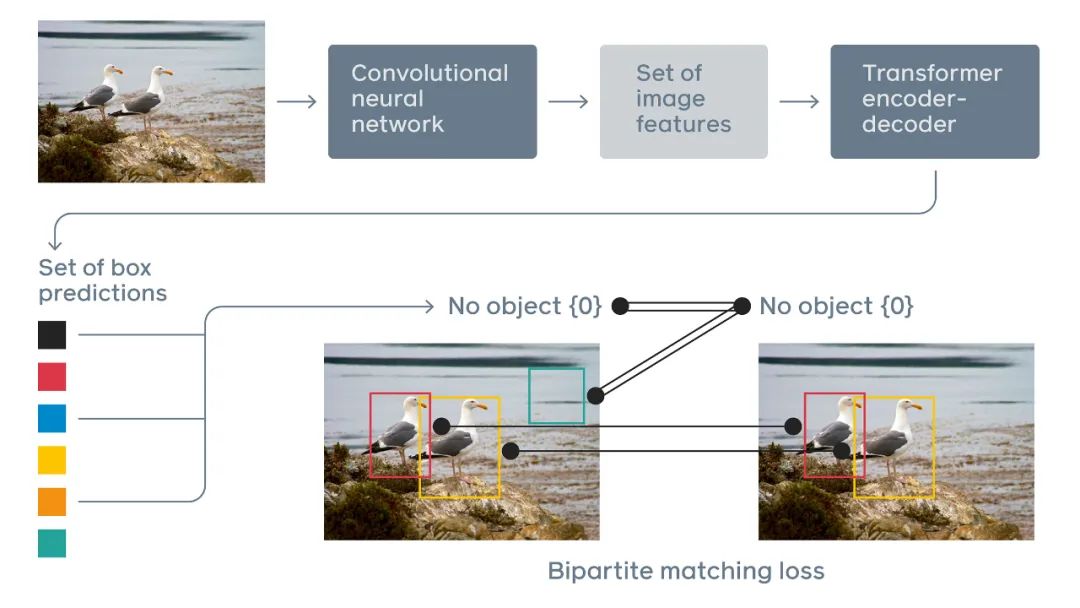
DETR directly predicts the final detection results by combining a common CNN with a Transformer. During training, bipartite matching assigns unique ground truth bounding boxes to the predicted results. Predictions without matches should generate a “no object” classification prediction.
DETR provides a simpler, more flexible pipeline architecture that requires fewer heuristics. Using basic architectural blocks, inference can be compressed into 50 lines of simple Python code.
Moreover, since Transformers have been proven to be a powerful tool in various fields, Facebook researchers believe that with further tuning, DETR’s performance and training efficiency can be further improved.
Paper link: https://arxiv.org/pdf/2005.12872v1.pdf
To facilitate the reproduction of DETR’s results, Facebook has also open-sourced the model’s code and pre-trained models on GitHub.
Project address: https://github.com/facebookresearch/detr
Facebook stated that the baseline DETR was trained for 300 epochs on 8 V100 GPUs per node, with each epoch taking 28 minutes, so training for 300 epochs took about 6 days. They provided the training results and logs for 150 epochs on GitHub for reference.
Additionally, researchers also provided a Colab Notebook, allowing users to upload their own images for prediction.

However, some have questioned the research results: “How is Faster R-CNN considered SOTA?”

Indeed, in the field of object detection, Faster R-CNN is quite outdated, lagging far behind the recent ResNeSt, so comparing it for performance is somewhat forced.
Evolution of SOTA Object Detection Algorithms on COCO
However, some believe that we should focus more on the innovative aspects of the paper, as the authors have made attempts in a new direction, which also has certain application scenarios (such as multi-modal tasks that handle both images and text simultaneously).
A New Architecture for Object Detection Tasks
DETR treats the object detection task as an image-to-set problem. Given an image, the model must predict an unordered set (or list) of all objects, each represented by a class and surrounded by a tight bounding box.
This representation method is particularly suitable for Transformers. Therefore, researchers use convolutional neural networks (CNNs) to extract local information from images while utilizing the Transformer encoder-decoder architecture for global reasoning and generating predictions.
In locating objects in images and extracting features, traditional computer vision models typically use complex and partially manual operations based on custom layers. DETR uses a simpler neural network, providing a true end-to-end deep learning solution.
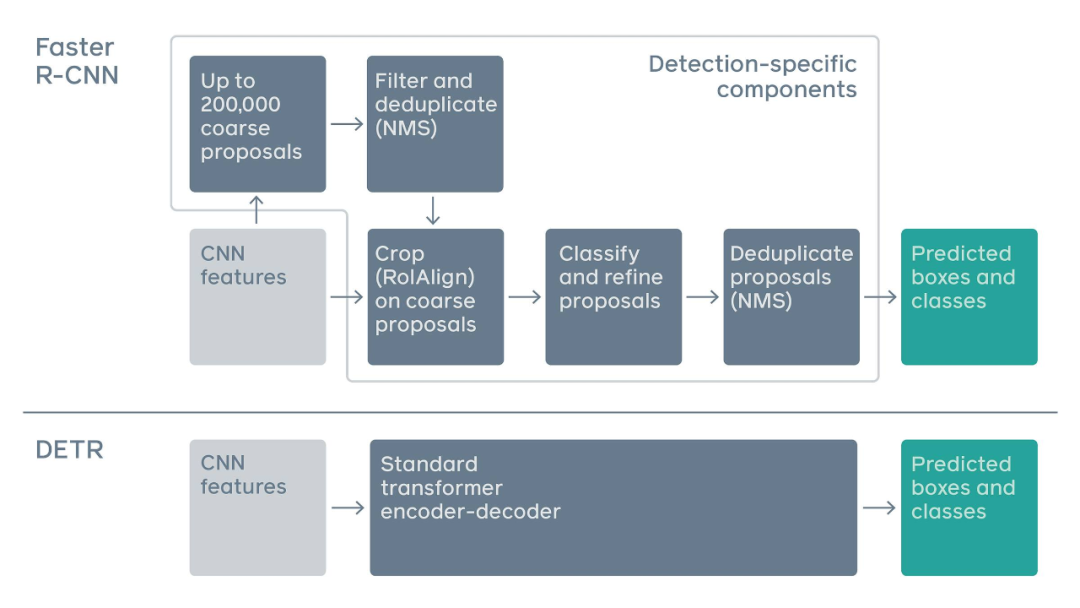
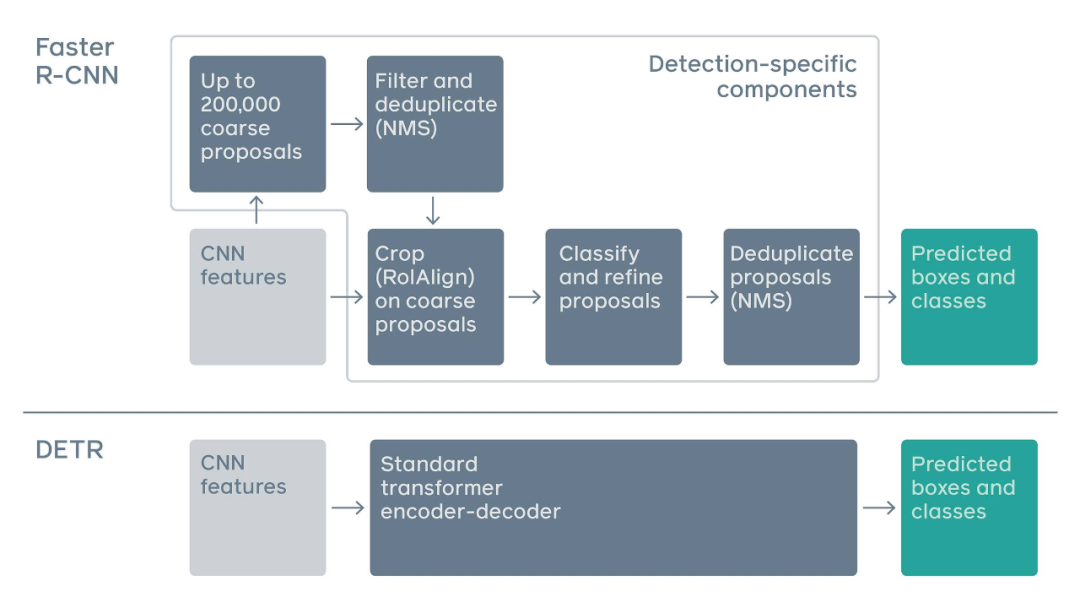
Traditional two-stage detection systems, such as Faster R-CNN, predict object bounding boxes by filtering through a large number of rough candidate regions. In contrast, DETR utilizes a standard Transformer architecture to perform operations traditionally specific to object detection, thereby simplifying the detection pipeline.
The DETR framework includes a set-based global loss that makes unique predictions through bipartite matching, as well as a Transformer encoder-decoder architecture. Given a small set of learned target queries, DETR infers the relationship between targets and the global image background, directly and in parallel outputting the final prediction set. Previous researchers have attempted to use architectures like recurrent neural networks for object detection, but these architectures make predictions sequentially rather than in parallel, resulting in slow speeds and low effectiveness.
The self-attention mechanism of Transformers allows DETR to perform global reasoning over the image and specific predicted targets. For example, the model can observe other areas of the image to help determine the target in the bounding box. Additionally, DETR can make predictions based on the relationships or correlations between targets in the image. For instance, if DETR predicts that there is a person standing on the beach in the image, it will also know that a partially obscured target is more likely to be a surfboard. In contrast, other detection models can only predict each target in isolation.
Researchers state that DETR can also be extended to other related tasks, such as panoptic segmentation, which aims to segment clearly foreground targets while labeling all pixels in the background.
One Architecture for Text and Image Processing
From the perspectives of research innovation and information reasoning methods, applying Transformers to the visual domain helps bridge the gap between the NLP and computer vision communities. There is great interest in tasks that simultaneously handle visual and textual inputs, such as Facebook’s recent Hateful Memes Challenge (to detect malicious images and texts). It is well known that traditional architectures struggle to handle such bimodal tasks.
DETR’s novel architecture helps enhance the interpretability of computer vision models, and due to its attention-based mechanism, it is easy to observe which parts of the image the network is looking at when making predictions.
Finally, Facebook AI researchers hope that DETR can promote advancements in the field of object detection and develop new methods for handling bimodal tasks.
Researchers quantitatively evaluated the results obtained by DETR against Faster R-CNN on the COCO dataset. They then provided results for DETR in panoptic segmentation to demonstrate its versatility and scalability, keeping the weights of the DETR model unchanged and training only a small portion of the extension modules.
Comparison with Faster R-CNN
The table below shows the results of comparing DETR with Faster R-CNN on the COCO validation set.
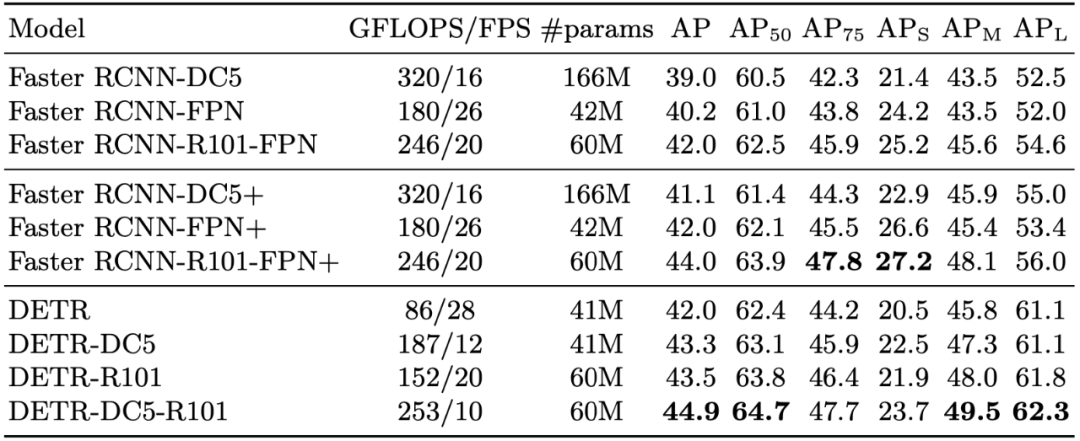
Table 1: Comparison results with Faster R-CNN on the COCO validation set.
The results indicate that DETR performs better in detecting large objects, while performing worse in detecting small objects.
Using DETR for Panoptic Segmentation
Panoptic segmentation has recently received widespread attention in the computer vision community. Similar to the extended Mask R-CNN of Faster R-CNN, DETR can also be easily extended by adding a mask head at the top of the decoder output.
The image below shows the quantized results of DETR in the panoptic segmentation task. It can be seen that DETR generates matching prediction masks for objects and materials (things and stuff) in a unified manner.
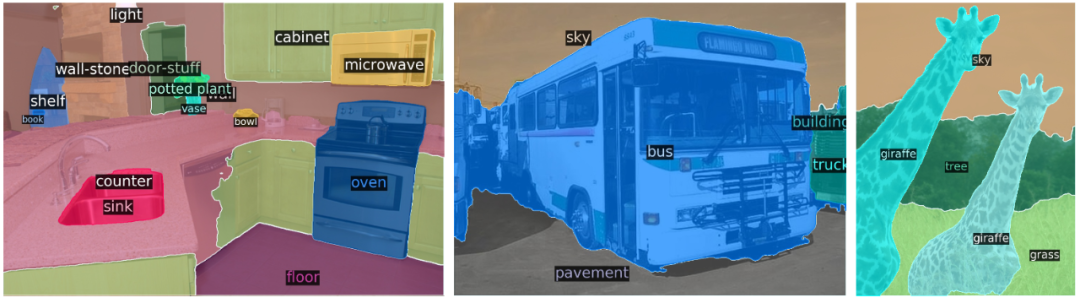
Figure 9: Panoptic segmentation results processed by DETR-R101.
The results show that DETR is particularly good at material classification, and researchers speculate that the global reasoning characteristics of the decoder’s attention mechanism are key to this outcome.
In the table below, researchers compared their proposed unified panoptic prediction method with other methods that distinguish between objects and materials.
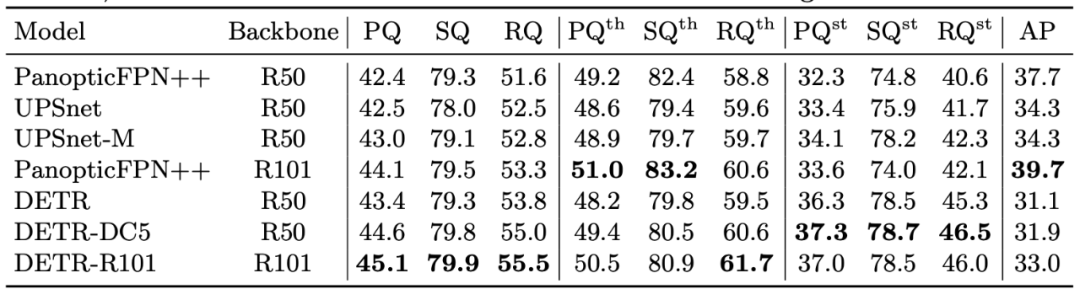
Table 5: Comparison of DETR with current SOTA methods on the COCO validation set.
Reference link: https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers
The first “Malanshan” Cup International Audio and Video Algorithm Competition is currently in full swing. The competition focuses on three major areas: image and recommendation, video quality optimization, with three main topics including video-specific point tracking, video recommendation, and quality damage repair. Outstanding participants can not only win prizes but also have their award-winning solutions potentially applied in Mango TV’s core areas, and students may join Mango TV’s “Youth Program” with a “special offer”.
Scan the QR code below or click to read the original text to register for the competition now.


