Introduction This paper shares the research titled CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation, proposed by Fudan University & ByteDance. It introduces a new paradigm for layout-to-image generation that supports controllable image generation under the MM-DiT framework based on layouts!
Pytorch training camp, mastering code implementation in two weeks
Comprehensive tutorials on various CV directions and deployment frameworks
Full-stack guidance classes, beginner classes, and paper guidance classes are now fully launched!!

-
Paper link: https://arxiv.org/abs/2412.03859 -
Project homepage: https://creatilayout.github.io -
Project code: https://github.com/HuiZhang0812/CreatiLayout -
Project Demo: https://huggingface.co/spaces/HuiZhang0812/CreatiLayout -
Dataset: https://huggingface.co/datasets/HuiZhang0812/LayoutSAM
Task Background
Layout-to-Image (L2I) generation is a technology for controllable image generation based on layout information, where layout information includes the spatial positions and descriptions of entities in the image. For example, users specify the descriptions and spatial positions of these entities: Iron Man holding a drawing board, standing on a rock, with “CreatiLayout” written in hand-drawn font on the drawing board, and the background featuring the seaside at sunset. Layout-to-Image can generate images that meet user requirements based on this information.
Layout-to-Image further unleashes the capabilities of Text-to-Image models, providing users with more precise control and creative expression channels, with broad application prospects in game development, animation production, interior design, and creative design.
Previous Layout-to-Image models mainly had the following issues:
-
Layout Data Issues: Existing layout datasets suffer from limitations such as small-scale data with closed sets and coarse-grained entity annotations, which restrict the model’s ability to generalize to generating open-set entities and the precision in generating entities with complex attributes. -
Model Architecture Issues: Previous models primarily focused on the U-Net architecture, such as SD1.5 and SDXL. However, with the development of MM-DiT, models like SD3 and FLUX have achieved new heights in visual quality and text adherence. Directly applying the layout control paradigm of U-Net to MM-DiT would weaken the accuracy of layout control. Therefore, a new framework needs to be designed for MM-DiT to efficiently integrate layout information and fully leverage its potential. -
User Experience Issues: Many existing methods only support bounding boxes as a way for users to specify entity locations, lacking the ability to handle more flexible input methods (such as center points, masks, sketches, or just textual descriptions), which limits the user experience. Additionally, these methods do not support optimizations like adding, deleting, or modifying layouts for users.
Method Overview
To address the issues in data, models, and experiences in previous methods, CreatiLayout proposes targeted solutions to achieve higher quality and more controllable layout-to-image generation.
1. Large-Scale & Fine-Grained Layout Dataset: LayoutSAM
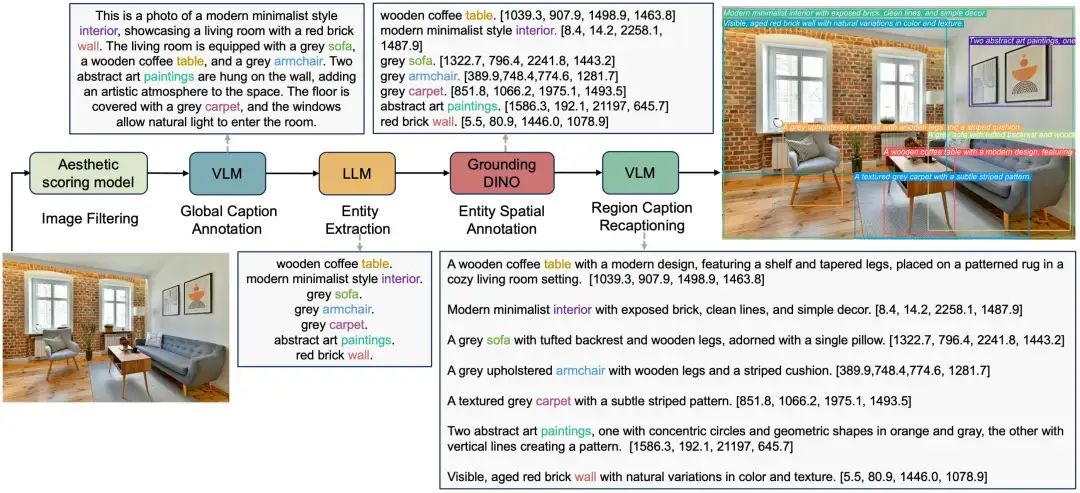
CreatiLayout has constructed a chain for automatic annotation of layouts, proposing the large-scale layout dataset LayoutSAM, which contains 2.7 million image-text pairs and 10.7 million entity annotations.
LayoutSAM is filtered from the SAM dataset and features open-set entities, fine-grained annotations, and high image quality. Each entity includes bounding boxes and detailed descriptions covering complex attributes like color, shape, and texture. This provides a data-driven approach for the model to better understand and learn layout information.
Based on this, CreatiLayout has constructed the layout-to-image generation evaluation benchmark LayoutSAM-Eval, which comprehensively evaluates model performance in layout control, image quality, and text adherence.
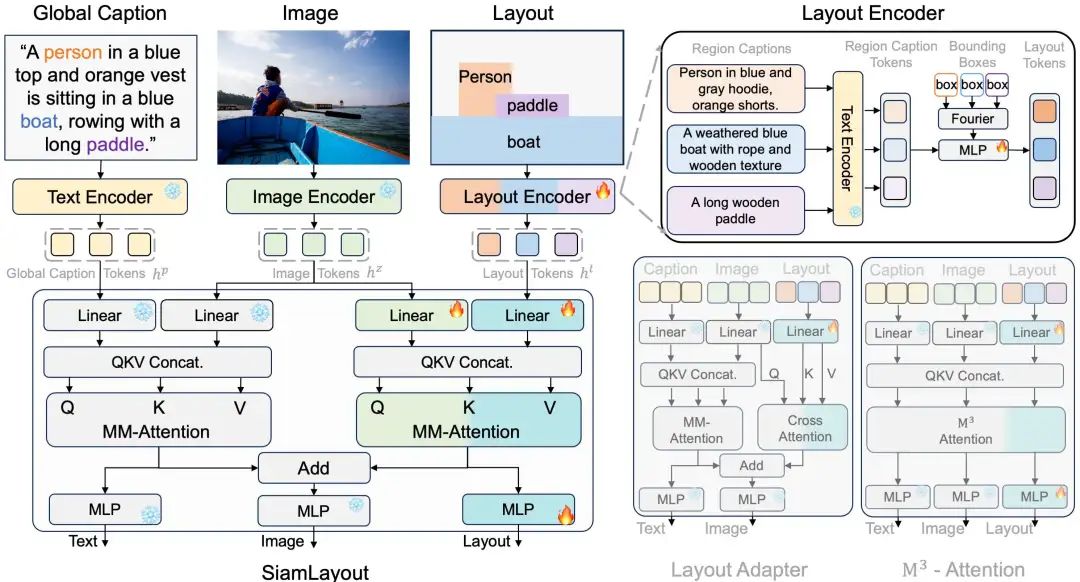
2. Model Architecture Viewing Layout Information as a Modality: SiamLayout
CreatiLayout proposed the SiamLayout framework, which introduces layout information into MM-DiT while effectively alleviating modality competition issues and enhancing the guiding role of layouts, achieving more precise layout control compared to other network solutions. The core design points are:
-
Viewing layout information as an independent modality, equally important as text and image modalities, enhancing the guiding degree of layout information on image content -
The interaction between layout modality and image modality is achieved through the native MM-Attention of MM-DiT, preserving its advantages in modality interaction -
The interaction between the three modalities of image, text, and layout is decoupled into two twin branches: image-text interaction branch and image-layout interaction branch, allowing text and layout to guide image content without interference.
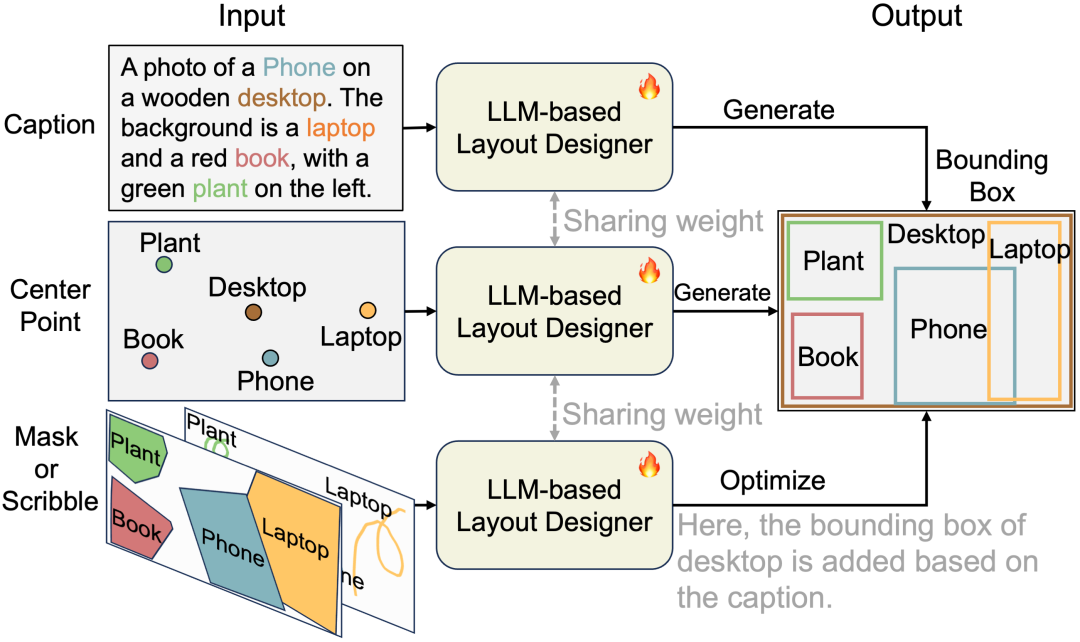
3. Layout Designer Supporting Layout Generation and Optimization: LayoutDesigner
CreatiLayout proposed LayoutDesigner, which utilizes large language models for layout planning, capable of generating and optimizing layouts based on user inputs (center points, masks, sketches, textual descriptions), supporting more flexible user input methods and providing layout optimization functions, such as adding, deleting, and modifying entities. This allows users to express their design intentions more conveniently and generate more harmonious and aesthetically pleasing layouts.
Experimental Results
1. Comparison Experiments with SOTA Methods in Layout-to-Image Generation
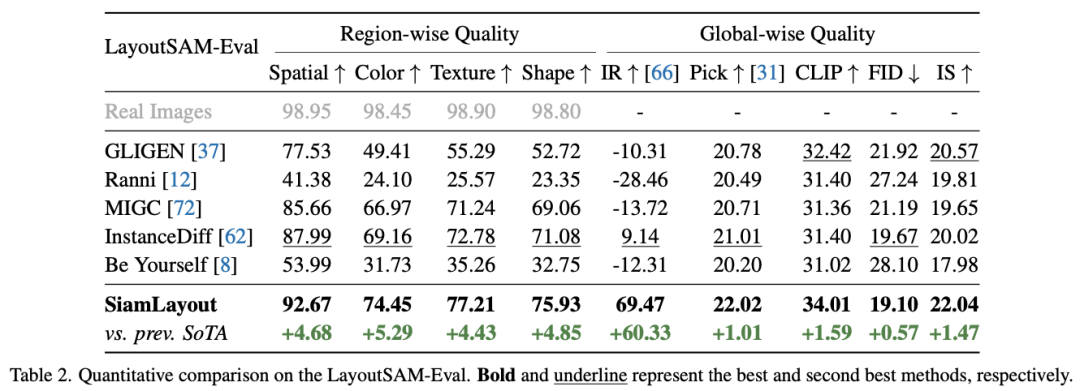
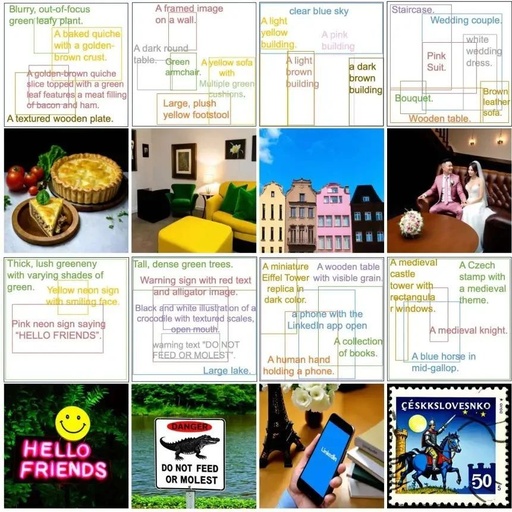
In the fine-grained open-set layout-to-image generation task, CreatiLayout outperforms previous SOTA methods in spatial positioning, color, texture, shape, and other area-level attribute rendering; in overall image quality, CreatiLayout also exhibits better visual quality and text adherence.
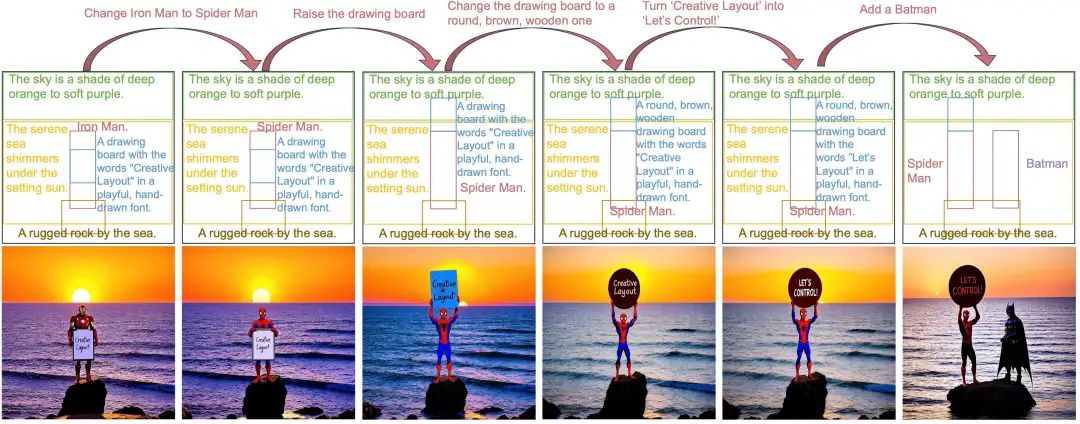
The visual results below further confirm the advantages of CreatiLayout. For example, the more precise generation of the text “HELLO FRIENDS” and the generation of different colors of pencils and benches. You can further experience CreatiLayout’s capabilities in Layout-to-Image on the project demo.
2. Comparison Experiments with SOTA Methods in Layout Generation and Optimization
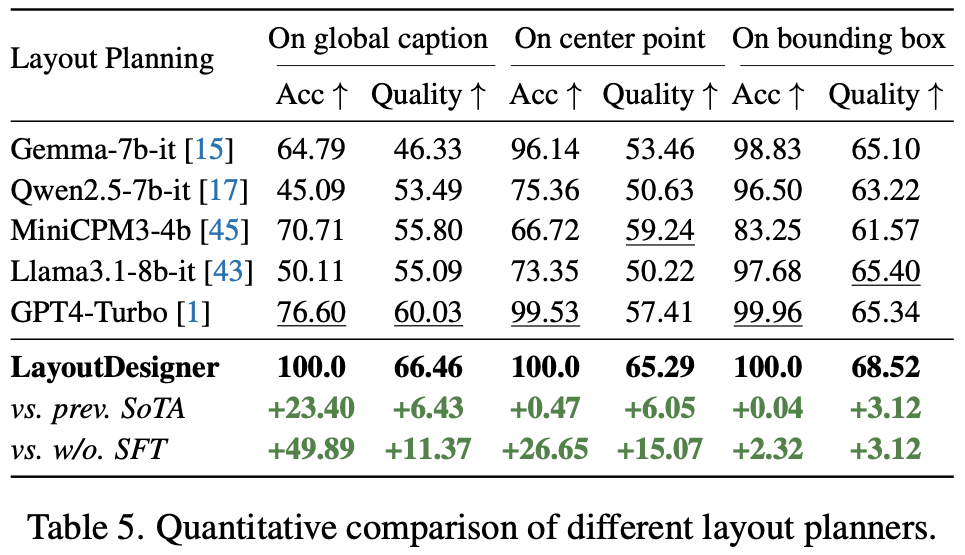
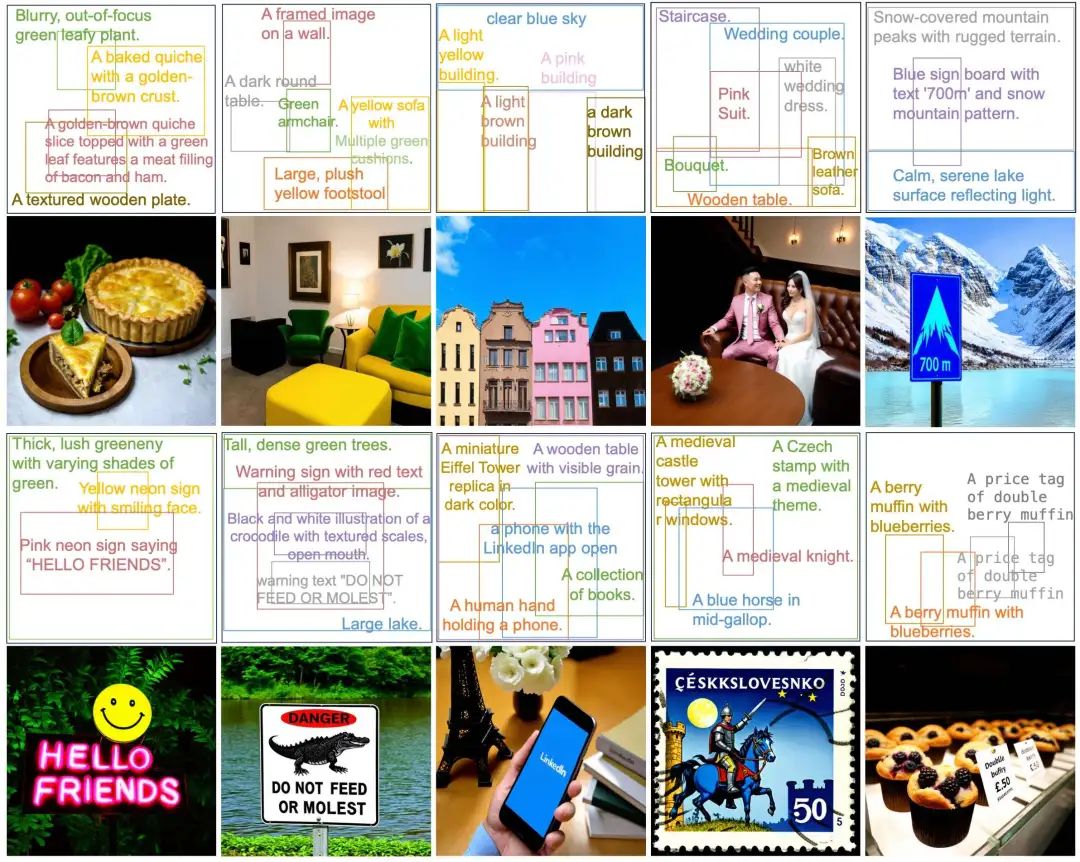
In quantitative and qualitative experiments on layout planning tasks, the layout generation and optimization capabilities of different layout optimizers under varying user input granularities are displayed. LayoutDesigner excels in layout planning tasks based on global titles, center points, and bounding boxes, achieving a format accuracy of 100%, indicating its ability to generate layouts that meet format requirements.
Furthermore, layouts planned based on LayoutDesigner to generate images yield higher quality and more aesthetically pleasing images. For instance, layouts generated by Llama3.1 often lack key elements, while layouts generated by GPT4 frequently violate basic physical laws, resulting in poor image quality and low text adherence when generating images based on these suboptimal layouts.

Full-Stack Guidance Class
To register, please scan the QR code below and note: “Full-Stack Class Registration”
