
In the field of artificial intelligence, knowledge base systems are one of the core components for building intelligent agents.
CrewAI’s memory system provides a comprehensive and flexible knowledge management solution by combining RAG (Retrieval-Augmented Generation) technology with traditional database storage.

This article will take you step-by-step through configuring the knowledge base using Crew.ai, setting up the vector database, and driving knowledge base content from various document types such as text, TXT, and PDF.
Ready? Let’s get started!
1. Basic Configuration and Features
To ensure that the output and knowledge are more conservative and consistent, the temperature for the LLM instance of the knowledge base is generally set to 0.
# Create an LLM instance, setting temperature to 0 to ensure deterministic output
# temperature=0 means the output will be more conservative and consistent
llm = LLM(model="gpt-4o-mini", temperature=0)There are several types of knowledge base configurations in Crew.ai:
StringKnowledgeSource
The simplest one is StringKnowledgeSource, which configures the corresponding knowledge in the specified string_content. The related code is as follows:
from crewai import Agent, Task, Crew, Process, LLM
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
# Create a string type knowledge source
# StringKnowledgeSource allows using plain text strings as a knowledge base
content = "Users name is John. He is 30 years old and lives in San Francisco."
string_source = StringKnowledgeSource(
content=content, # Pass in the knowledge content
)
# Create an LLM instance, setting temperature to 0 to ensure deterministic output
# temperature=0 means the output will be more conservative and consistent
llm = LLM(model="gpt-4o-mini", temperature=0)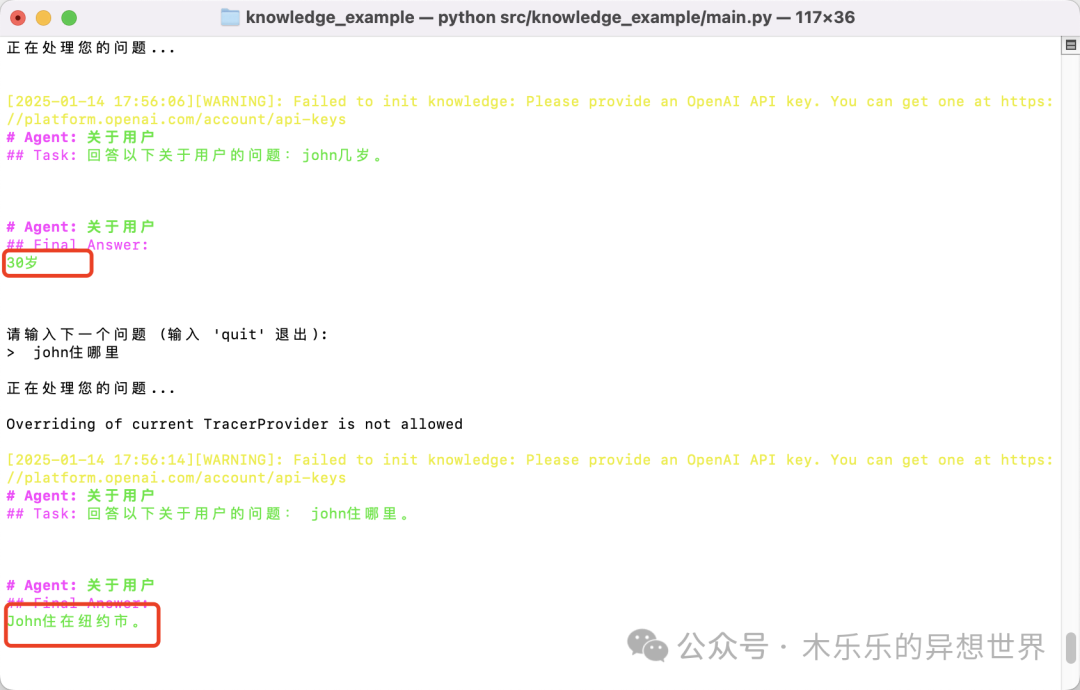
Let’s test it; the question can be answered normally. However, the model is talking nonsense! John lives in San Francisco, not New York. Let’s fix this issue.
We need to configure the crew to add the embedding model. The related configuration is as follows:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
knowledge_sources=[string_source,text_source],
embedder={
"provider": "ollama",
"config": {
"model": "nomic-embed-text",
"host": "http://localhost:11434" # Ollama default address
}
}
)Since I am using the locally installed embedding model from Ollama, I configured the local host address.
For how to install the embedding model locally, please refer to this article:
ollama local installation embedding model
Let’s test again:
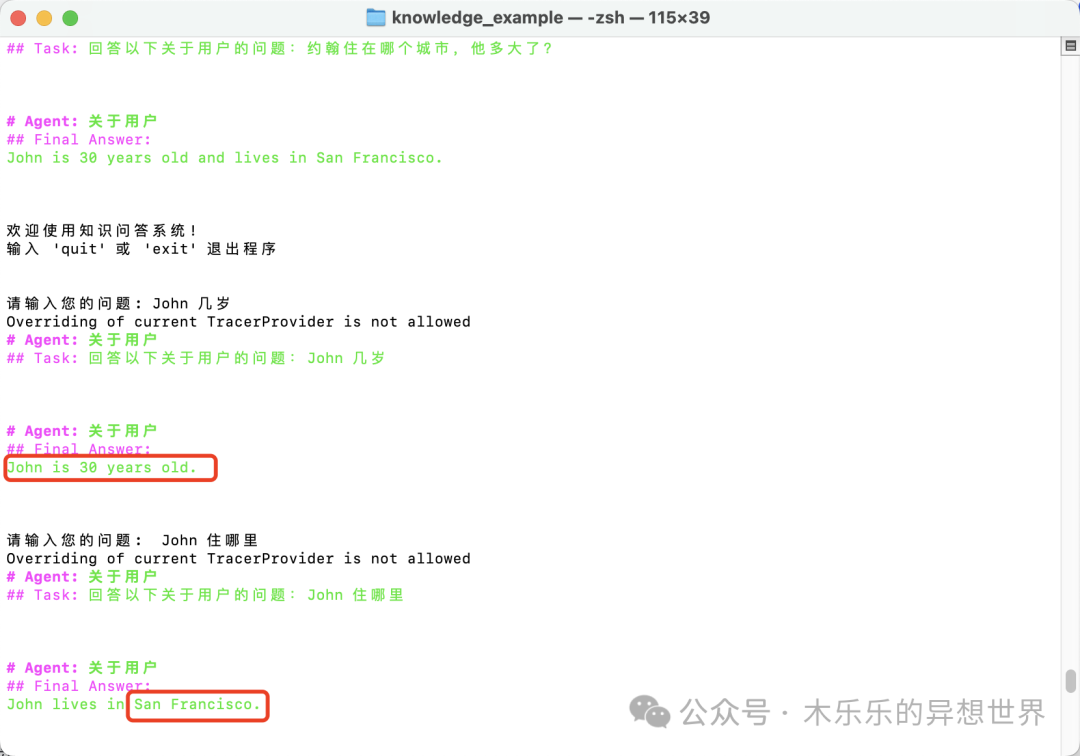
It works! The configured content in the knowledge base can now be answered correctly.
2. How to Solve the Nonsense Problem?
Let’s ask some other questions that are not in the knowledge base and see the effect.
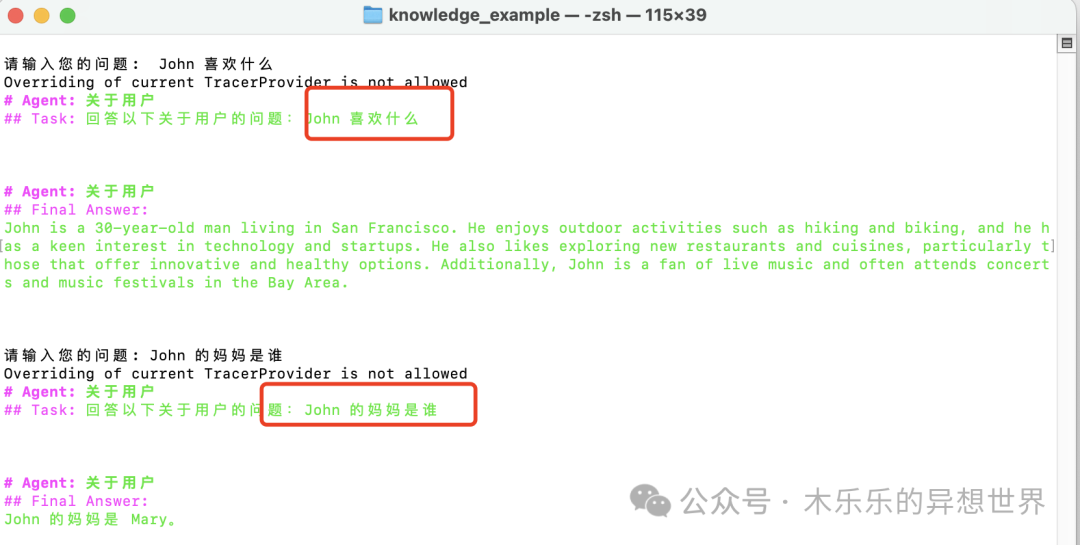
It started to talk nonsense (`へ´)!
How to constrain and limit it? Directly add constraints in the Agent configuration.
Modification of agents.yaml
john:
role: >
User Information Expert
goal: >
Accurately answer questions about users based solely on known information. If the question involves unknown information, clearly state "this information is not provided in the knowledge base."
backstory: >
You are a rigorous information expert, answering questions only based on the information explicitly provided in the knowledge base. For any information not clearly provided in the knowledge base, you will clearly state that this information is unknown.Finally, let’s check the effect; perfect!
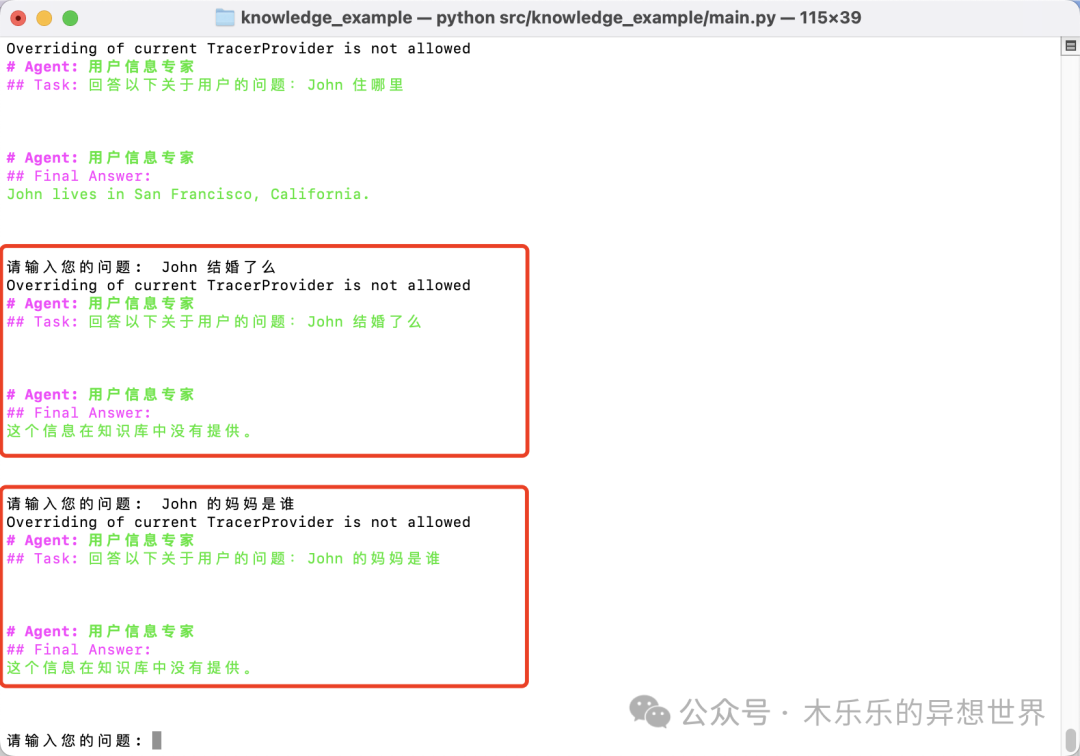
3. Solving Memory Confusion When Adjusting Knowledge Base Content Multiple Times
What happens when I adjust the content of the knowledge base multiple times?
I made the following modifications and adjustments:
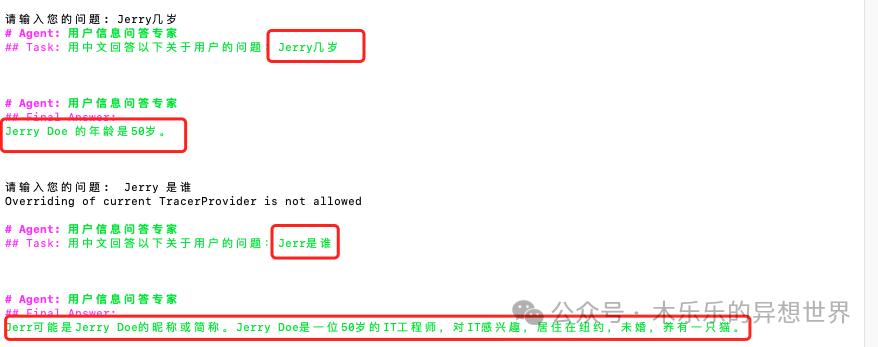
1. Changed John’s name to Jerry;
2. Changed both profession and interest from AI to IT.
3. Adjusted residence address, marital status, and pets.
After restarting, I inquired again and found the following issue:

This issue is caused by the vector database cache in CrewAI. When I update the knowledge base file, the previous embedding vectors remain cached and do not automatically update.
What to do? It’s quite simple.
After the code for configuring the vector database, add the parameter force_reload_knowledge=True, which will force CrewAI to reload and embed the knowledge base content every time it runs. This ensures that the latest knowledge base content is used each time.
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
knowledge_sources=[string_source, file_source],
embedder={
"provider": "ollama",
"config": {
"model": "nomic-embed-text",
"host": "http://localhost:11434"
}
},
force_reload_knowledge=True # Add this line to force reload the knowledge base
)
Haha, fixed it!
4. Other Formats of Knowledge Base Configuration Modes
Crew.AI supports various file formats, including TXT, PDF, DOCX, HTML, etc. The related component is CrewDoclingSource, which is a versatile knowledge source.
Here are the code examples for different formats of knowledge base sources:
Importing Knowledge from TXT Files
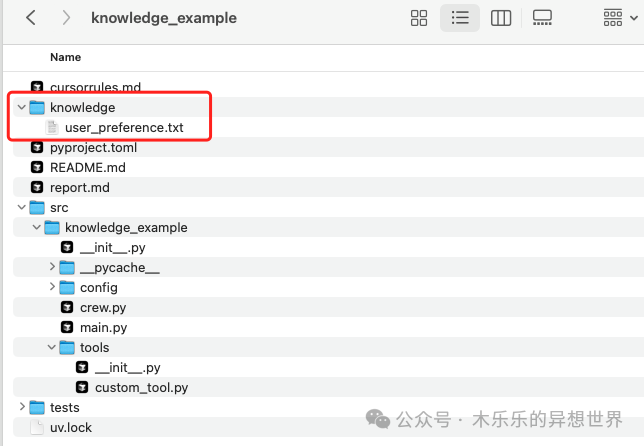
It should be noted that I created a separate folder for knowledge base documents in my Crew project:
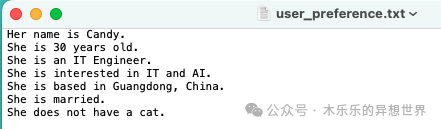
The configuration of the knowledge base content is as follows:
The corresponding code is as follows:
from crewai.knowledge.source.text_file_knowledge_source import TextFileKnowledgeSource # Import knowledge base configuration supporting Txt format
# Configure file knowledge base
# Get the current position path
current_dir = Path(__file__).parent.parent.parent
# Specify the file path
file_paths = current_dir / "knowledge"/ "user_preference.txt"
txt_source = TextFileKnowledgeSource(
file_paths =[file_paths],
metadata={"preference": "personal"}
)Then, in @Crew, make the following modifications, changing the original
knowledge_sources=[string_source] to knowledge_sources=[txt_source]
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
knowledge_sources=[txt_source],
embedder={
"provider": "ollama",
"config": {
"model": "nomic-embed-text",
"host": "http://localhost:11434"
}
},
force_reload_knowledge=True
)Okay, let’s test the effect:

Importing Knowledge from PDF Files
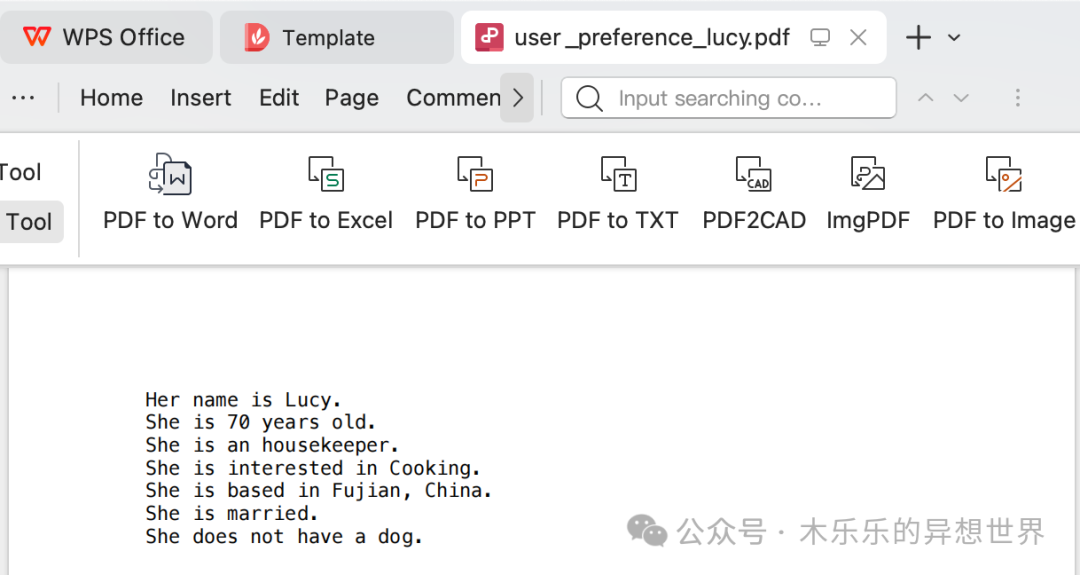
The information in this PDF document is as follows:
The code modification is as follows:
from crewai.knowledge.source.pdf_knowledge_source import PDFKnowledgeSource
# Configure file knowledge base
# Specify the PDF file path
pdf_file_paths = current_dir / "knowledge"/ "user_preference_lucy.pdf"
pdf_source = PDFKnowledgeSource(
file_paths=[pdf_file_paths],
metadata={"source": "personal"}
)Similarly, the @crew also needs to be modified accordingly.
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
knowledge_sources=[pdf_source],
embedder={
"provider": "ollama",
"config": {
"model": "nomic-embed-text",
"host": "http://localhost:11434"
}
},
force_reload_knowledge=True
)Let’s test the effect:

Done.
For other formats of knowledge bases, I won’t elaborate one by one; you can modify the corresponding code for testing. The code is as follows:
Importing Knowledge from CSV Format
# Create a CSV knowledge source
csv_source = CSVKnowledgeSource(
file_paths=["data.csv"]
# CSVKnowledgeSource is used to handle tabular data
# Suitable for handling structured datasets like tables, statistical data, etc.
)Importing Knowledge from Excel Format
# Create an Excel knowledge source
excel_source = ExcelKnowledgeSource(
file_paths=["spreadsheet.xlsx"]
# ExcelKnowledgeSource is specifically for handling Excel files
# Can handle complex spreadsheets, including documents with multiple sheets
)Importing Knowledge from JSON Format
# Create a JSON knowledge source
json_source = JSONKnowledgeSource(
file_paths=["data.json"]
# JSONKnowledgeSource is used to handle JSON formatted data
# Suitable for handling structured configuration files or API response data
)Importing Knowledge from Specified Web Links
from crewai.knowledge.source.crew_docling_source import CrewDoclingSource
# Create a knowledge source using CrewDoclingSource to load online documents
# Here we load two academic papers about AI: reward hacking and hallucination
content_source = CrewDoclingSource(
file_paths=[
"https://lilianweng.github.io/posts/2024-11-28-reward-hacking",
"https://lilianweng.github.io/posts/2024-07-07-hallucination",
],
)