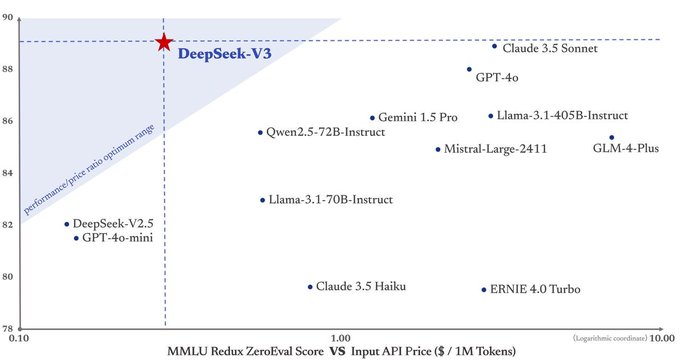
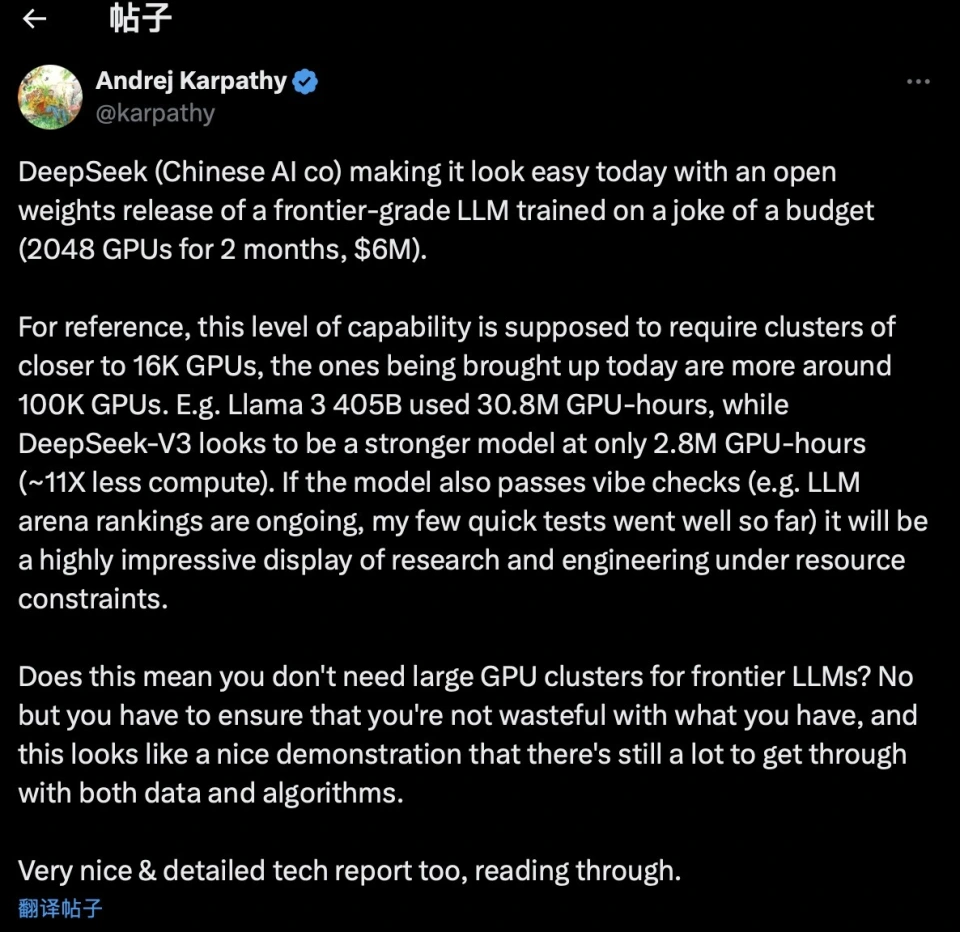
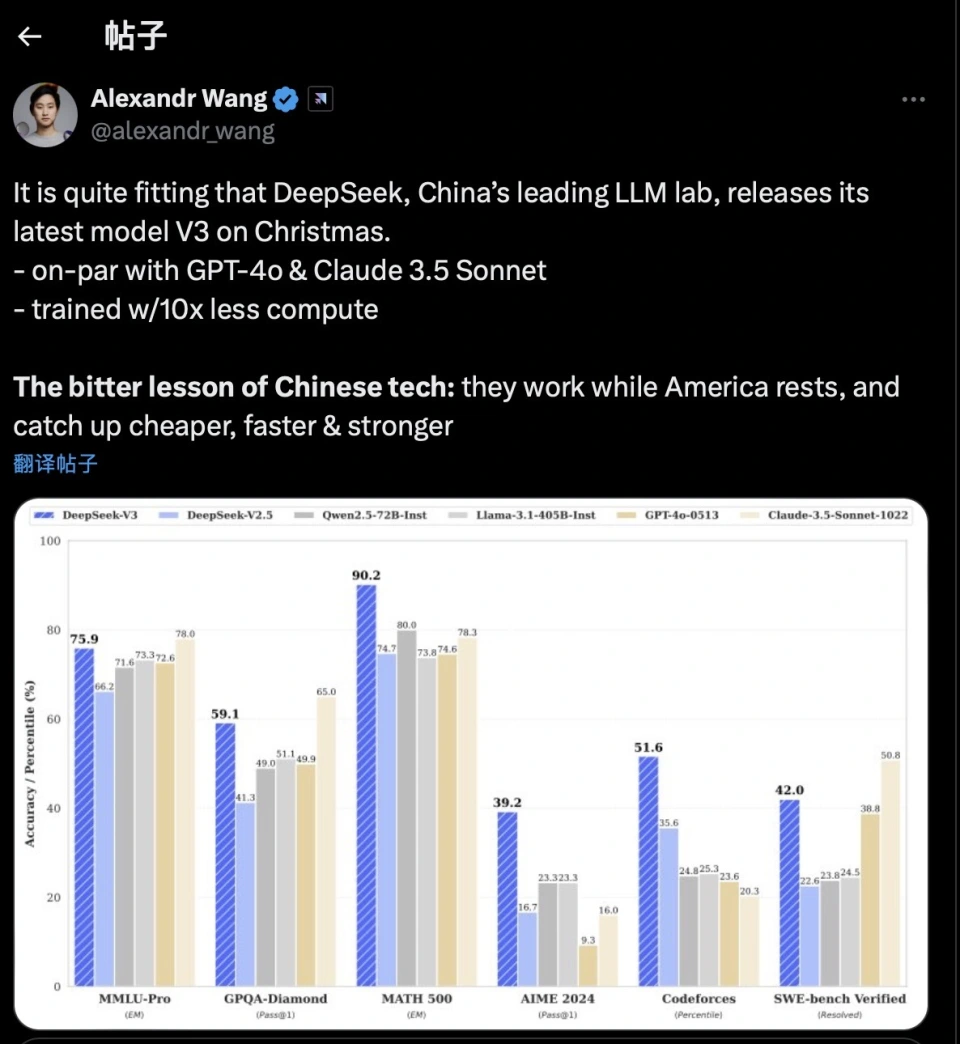
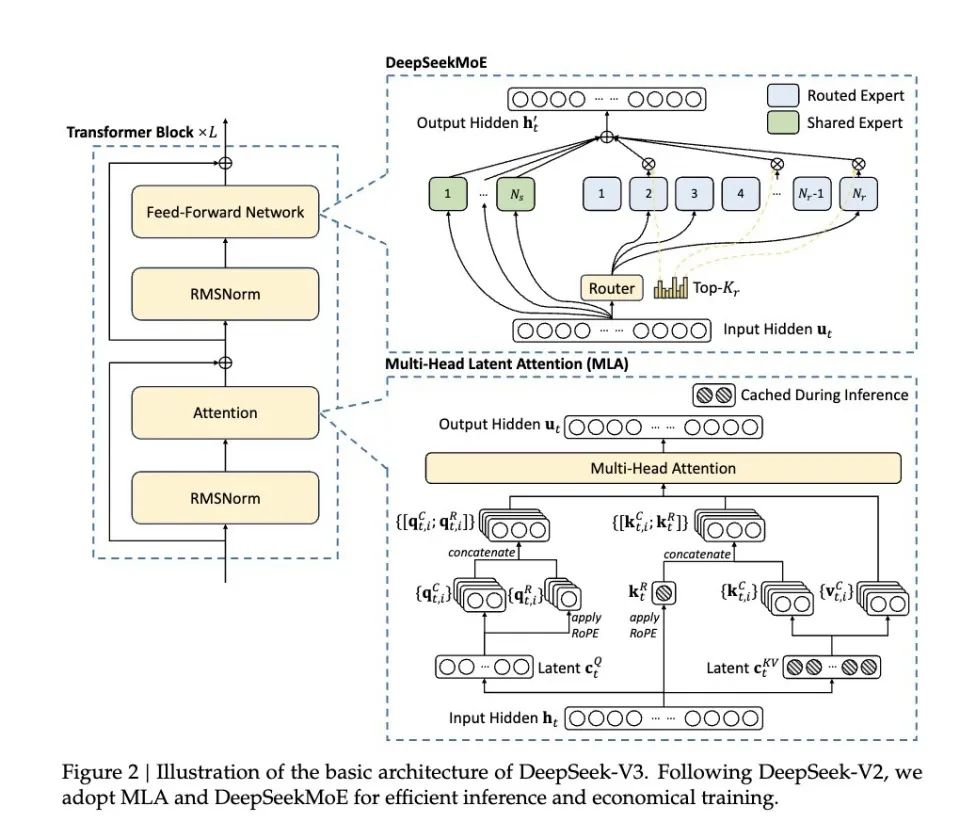
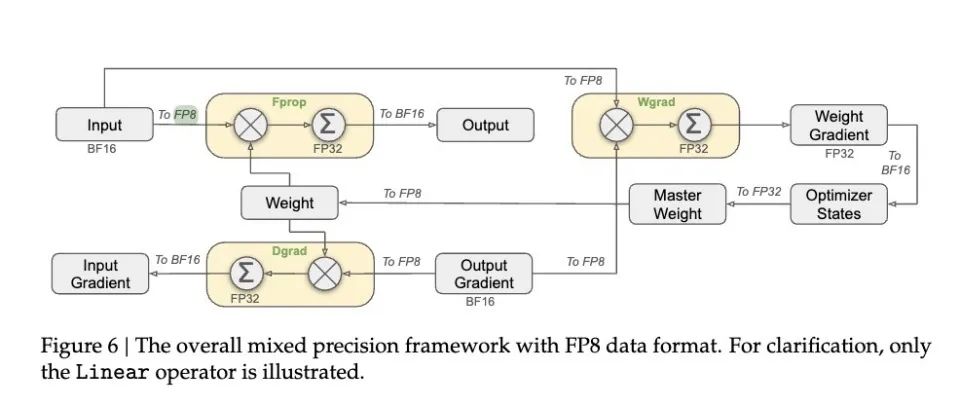
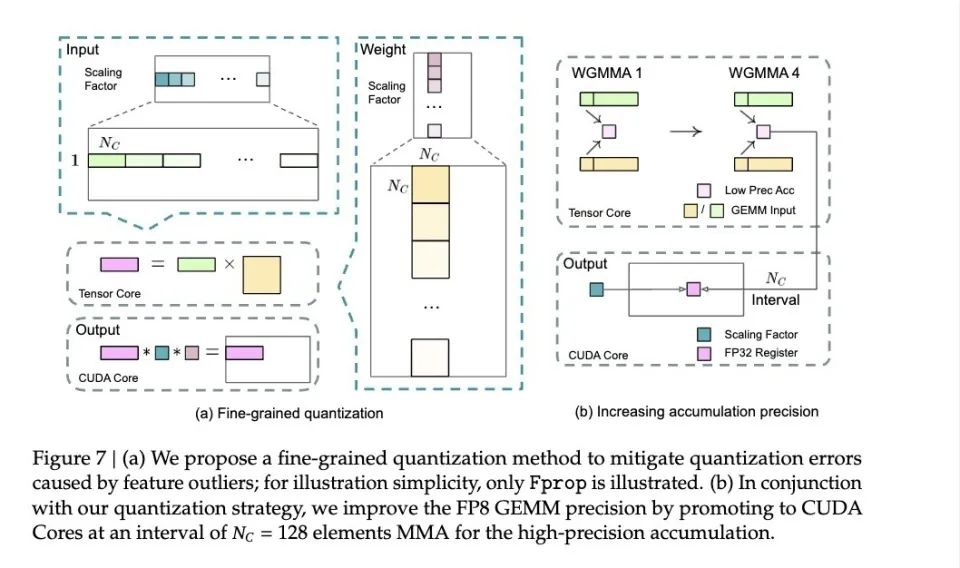
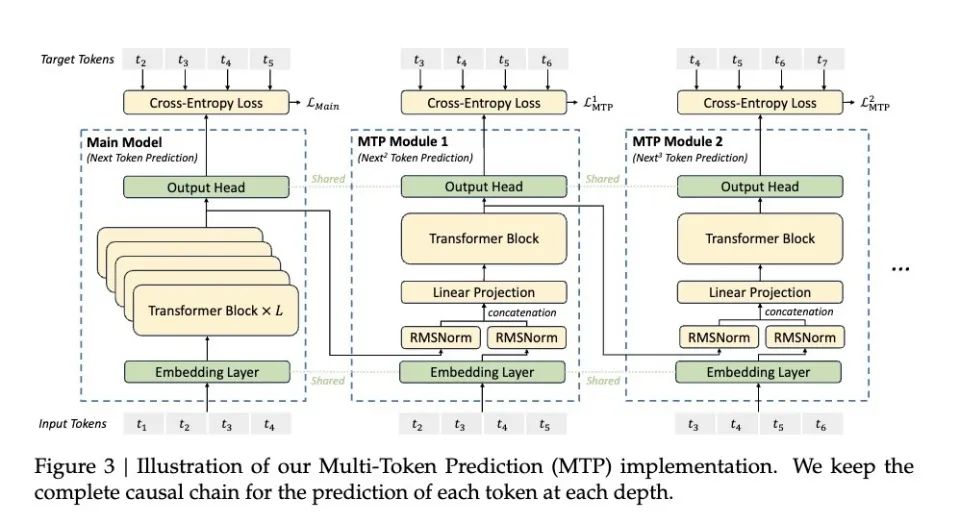
(DeepSeek’s proposed solution for error accumulation)
DeepSeek discovered a clever solution: instead of waiting until the end to calculate the total, it transfers the current result to a scientific calculator every 128 numbers added. To ensure this process does not affect speed, they leveraged the characteristics of the H800 GPUs: just like having two cashiers, when one is checking out a shopping basket, the other can continue scanning new items. This way, while enhancing precision, the processing speed remains largely unaffected.
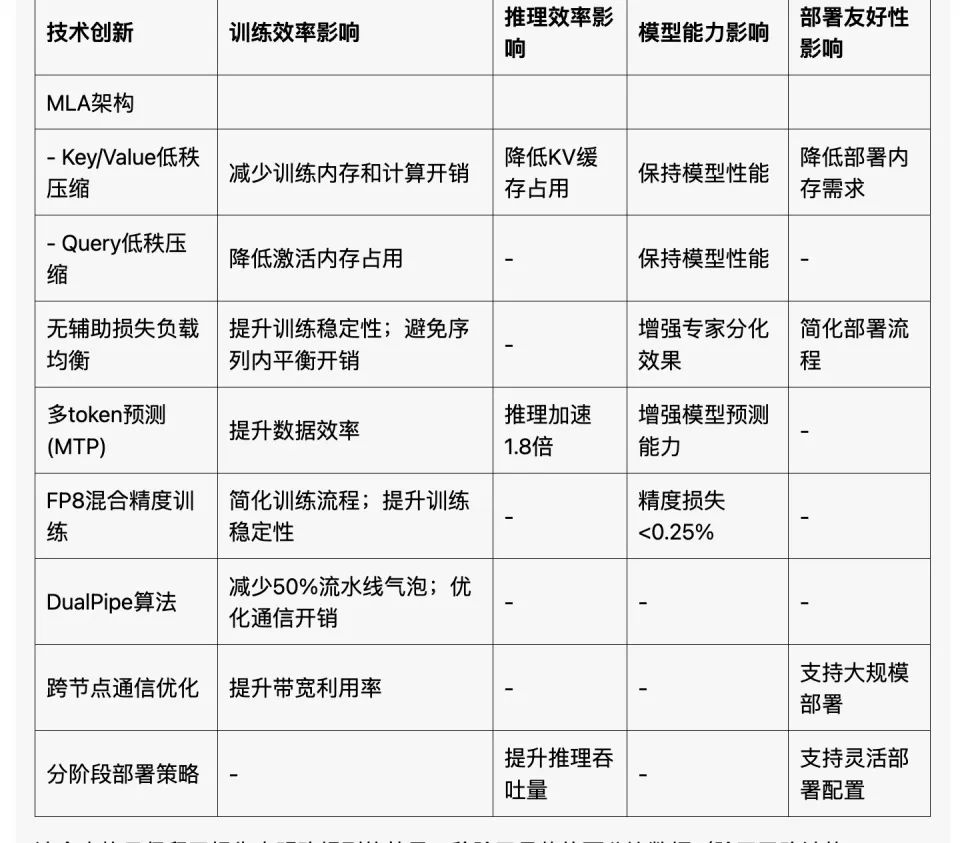
This strategy significantly boosts model training speed, as core computations can double in speed, while memory usage decreases noticeably. Furthermore, the final model’s accuracy loss can be kept below 0.25%, making it almost lossless.
Parallelism: Extreme Utilization of Hardware
To achieve faster training speeds, the most effective method is to increase the scale of parallel computation, allowing more computational units to process different data or tasks simultaneously. In parallelism, the challenge is to utilize computational resources as effectively as possible, ensuring they are all working at high loads.
At the system architecture level, DeepSeek employs expert parallel training technology by assigning different expert modules to different computing devices for simultaneous training, enhancing computational efficiency during the training process.
However, this simple parallelism is far from sufficient. DeepSeek’s approach to computational power is extreme squeezing: if we consider the training process as a factory, their main task is to ensure no idle workers on the assembly line while optimizing processes as much as possible, allowing parts (data) to be operated (computed) as soon as they enter the assembly line.
DualPipe Inter-node Communication
The primary mode for optimizing the assembly line process is DeepSeek’s innovative DualPipe method.
In terms of computation and communication overlap, DualPipe adopts a multi-task parallel processing approach.
Just as modern computers can download files while processing documents, DualPipe allows the model to prepare the next required data transfer while computing. This design ensures that communication overhead is largely hidden during computation, greatly enhancing overall efficiency.
Traditional training information pipeline parallelism resembles an assembly line where each workstation processes tasks sequentially. When a data packet is passed from one stage to the next, waiting times often occur, leading to what is known as “pipeline bubbles.” These bubbles waste computational resources, as workers on the assembly line must wait for upstream processes to complete before starting work. Additionally, communication times between different nodes can become performance bottlenecks, just as long transfer times between workstations can impact overall production efficiency.
DualPipe introduces the concept of dual pipelines, processing two batches of products simultaneously on the same production line. When one computation stage is waiting for data transfer, it can immediately switch to processing another batch of data, fully utilizing previously idle time.