
Machine translation technology has developed for over 80 years. The legend of the Tower of Babel is now a thing of the past; we can no longer reach the heavens. However, machine translation can help you discuss the World Cup elegantly with people all over the world, avoiding misunderstandings.

01
Machine Translation and the Legend of Babel
The Bible records a story:
Humans once united to build a tower that could reach heaven—the Tower of Babel. To thwart their plans, God made humans speak different languages, preventing them from communicating with each other, leading to the failure of their plans and scattering them across the earth.
Achieving seamless communication between different languages has always been one of humanity’s ultimate dreams.

Recognizing that even with a lifetime of effort, one can only master a few dozen languages, many scientists began to ponder how to use machines to help solve communication issues, leading to the birth of machine translation.
Machine translation is the process of using computers to translate one natural language into another. The basic process roughly consists of three parts: preprocessing, core translation, and post-processing.
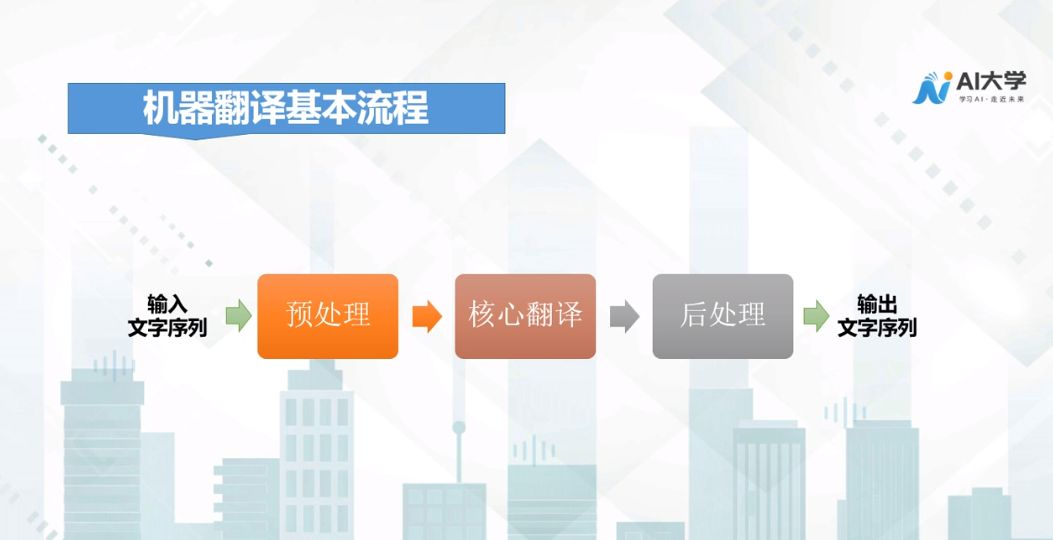
Preprocessing involves normalizing the text, breaking long sentences into shorter ones using punctuation, filtering out filler words and irrelevant text, and standardizing numbers and expressions.
The core translation module translates the input character units and sequences into the target language sequence, which is the most critical part of machine translation.
The post-processing module converts the translation results to the correct case, concatenates modeling units, and processes special symbols to make the translation more aligned with human reading habits.
02
The Journey of Machine Translation
The story of machine translation began in 1933, evolving from a bold idea in the minds of scientists to large-scale applications today. The development of machine translation technology can be divided into six phases.

Origin Phase:
Machine translation originated in 1933 when French engineer G.B. Artaud proposed the idea of machine translation and obtained a patent for a translation machine;
Initial Phase::
In 1954, Georgetown University, in collaboration with IBM, successfully completed the first English-Russian machine translation experiment using the IBM-701 computer, marking the beginning of machine translation research;
Stagnation Phase:
In 1966, the American National Academy of Sciences established the Automatic Language Processing Advisory Committee (ALPAC), which published a report titled “Languages and Machines,” denying the feasibility of machine translation, leading to a downturn in machine translation research;

Revival Phase:
In 1976, the TAUM-METEO system developed jointly by the University of Montreal and the Canadian Federal Government Translation Bureau marked the full revival of machine translation;
Development Phase:
In 1993, IBM’s Brown et al. proposed a statistical translation model based on word alignment, marking the rise of the second generation of machine translation technology;
In 2003, Edinburgh University’s Koehn proposed the phrase-based translation model, significantly improving machine translation effectiveness and promoting industrial applications;
In 2005, David Chang further proposed the hierarchical phrase model, and research on grammar tree-based translation models also made significant progress;
Prosperity Phase:
In 2013 and 2014, researchers from Oxford University, Google, and the University of Montreal proposed end-to-end neural machine translation, ushering in a new era of deep learning translation;
In 2015, the University of Montreal introduced the Attention mechanism, bringing neural machine translation to a practical stage;
In 2016, Google’s GNMT was released, and iFlytek launched its NMT system, leading to the large-scale application of neural translation.
03
Technical Principles of Machine Translation
Before discussing the technical principles of machine translation, let’s look at a timeline of the development of machine translation technology:
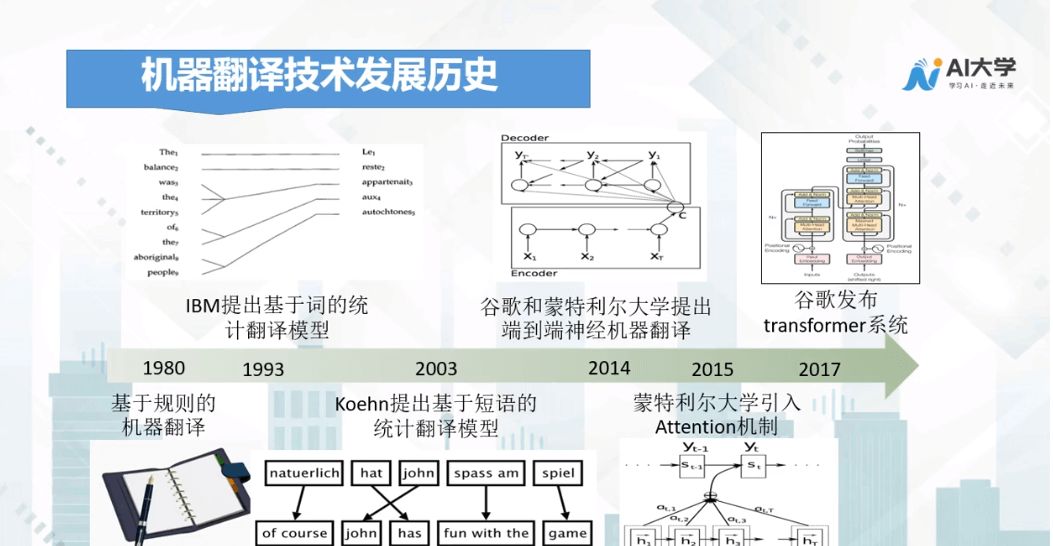
In the 1980s, rule-based machine translation began to be applied, representing the first generation of machine translation technology. As the application fields of machine translation became increasingly complex, the limitations of rule-based machine translation began to emerge, requiring more rules, which led to conflicts among them.
Thus, many researchers began to consider whether machines could learn the relevant rules automatically from databases. In 1993, IBM proposed the statistical translation model based on words, marking the rise of the second generation of machine translation technology.
In 2014, Google and the University of Montreal proposed the third generation of machine translation technology, which is end-to-end neural machine translation, marking the arrival of the third generation of machine translation technology.
After reviewing the iterative development of machine translation technology, let’s explore the core technologies of the three generations of machine translation: rule-based machine translation, statistical machine translation, and neural machine translation.
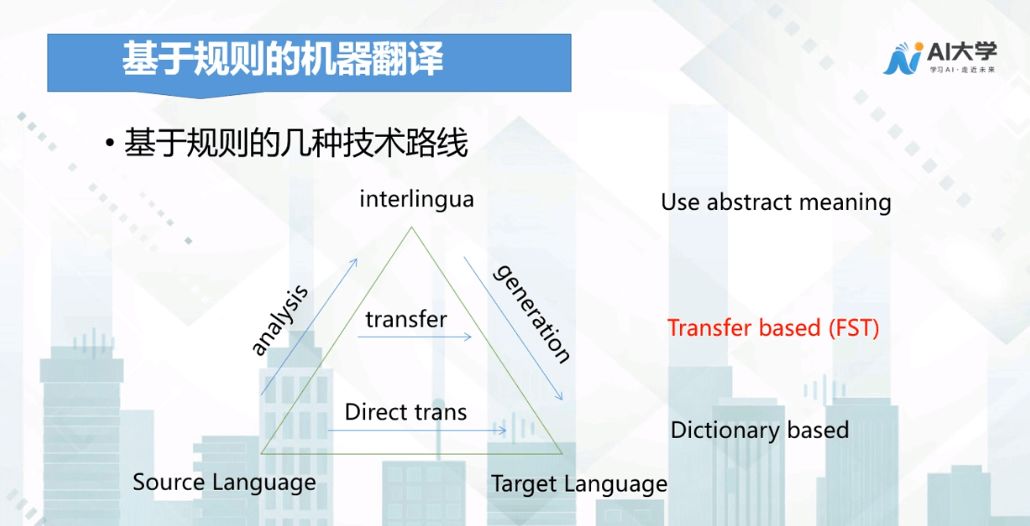
Rule-Based Machine Translation
Rule-based machine translation generally has three technical routes. The first method is direct translation, where after segmenting the source language, each word is translated into the corresponding word in the target language and then concatenated to produce the translation result.
Since the source and target languages do not belong to the same system, the syntactic order can differ significantly, and the translation result from direct concatenation is often suboptimal.
Therefore, researchers proposed a second method of rule-based machine translation, applying linguistic knowledge to analyze the syntax of the source language sentences. This method produces more accurate target translations due to the application of syntactic linguistic knowledge.
However, this method is only effective when the language’s regularity is strong enough for machines to analyze.
Building on this, researchers proposed whether it is possible to leverage human brain translation to achieve rule-based machine translation. This involves using an interlingua to describe the source language and then translating it into the target language using this interlingua.
However, due to the complexity of languages, achieving precise descriptions of the source and target languages using a single interlingua is quite challenging.
After discussing the three technical routes of rule-based machine translation, let’s summarize its advantages and disadvantages with a diagram:

Statistical Machine Translation
The second generation of machine translation technology is based on statistical machine translation, whose core lies in designing probabilistic models to model the translation process.
For instance, we represent the original sentence as x and the target language sentence as y, with the task of finding a translation model
θ.The earliest model applied to statistical translation is the source-channel model, which assumes that the observed source language text x is obtained from a segment of target language text y after some peculiar encoding. Therefore, the goal of translation is to restore y back to x, which is a decoding process.
Thus, our translation objective function can be designed to maximize Pr(𝑥│𝑦), and by using Bayes’ theorem, we can break down Pr(𝑥│𝑦) into two parts: Pr(𝑦) as the language model and Pr(𝑦|𝑥) as the translation model.

If we take the logarithm of both sides of this objective function, we can obtain a log-linear model, which is the model we actually use in engineering.
The log-linear model includes not only the translation model and language model but also reordering models, distortion models, and word count penalty models, which collectively constrain the translation from the source language to the target language.
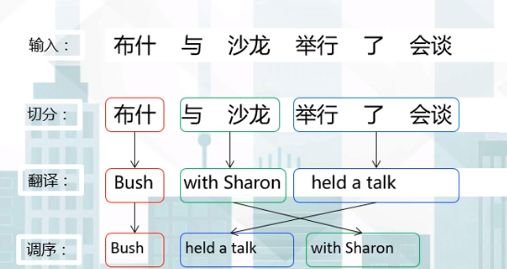
After discussing the relevant knowledge of statistical machine translation, let’s look at the three basic steps of phrase-based statistical translation models:
1. Source Phrase Segmentation: Segment the source language sentence into several phrases
2. Source Phrase Translation: Translate each source phrase
3. Target Phrase Reordering: Combine the target phrases into a sentence in a specific order
Finally, let’s summarize the advantages and disadvantages of statistical machine translation with a diagram:

Neural Machine Translation
Having discussed rule-based and statistical machine translation, let’s now explore end-to-end neural machine translation.
The basic modeling framework of neural machine translation is the end-to-end sequence generation model, which transforms input sequences into output sequences.
Its core consists of two aspects: how to represent the input sequence (encoding) and how to obtain the output sequence (decoding).
For machine translation, it includes both encoding and decoding, and introduces an additional mechanism—the attention mechanism—to assist in reordering.
Let’s look at a diagram to illustrate the process of RNN-based neural machine translation:
First, we obtain the input source language word sequence through tokenization. Each word is then represented by a word vector, resulting in a corresponding word vector sequence, which is encoded using a forward RNN neural network.
Next, we use a backward RNN to obtain its backward encoding representation, and finally concatenate the forward and backward encoding representations. Using the attention mechanism, we predict which word needs to be translated at each moment. Through continuous prediction and translation, we can obtain the target language translation.
04
Basic Applications of Machine Translation
The basic applications of machine translation can be divided into three major scenarios: information retrieval, information dissemination, and information communication.
In the information retrieval scenario, you may be familiar with applications like translation or overseas shopping, where encountering obscure words can be aided by machine translation technology to understand their true meanings.
In the information dissemination scenario, a typical application is assisted translation.
You might remember needing to write an abstract in English for your undergraduate thesis. Many students use Google Translate to convert their Chinese abstract into English and then make some simple adjustments to finalize the English abstract; this is a straightforward process of assisted translation.
The third major scenario is the information communication scenario, primarily addressing language communication issues between people.


That’s all for today’s introduction to “Machine Translation”. For those who want to study the course in detail, you can click the lower left corner “Read the Original” to enter the AI University official website and check the relevant teaching videos~


Follow us for more exciting courses
