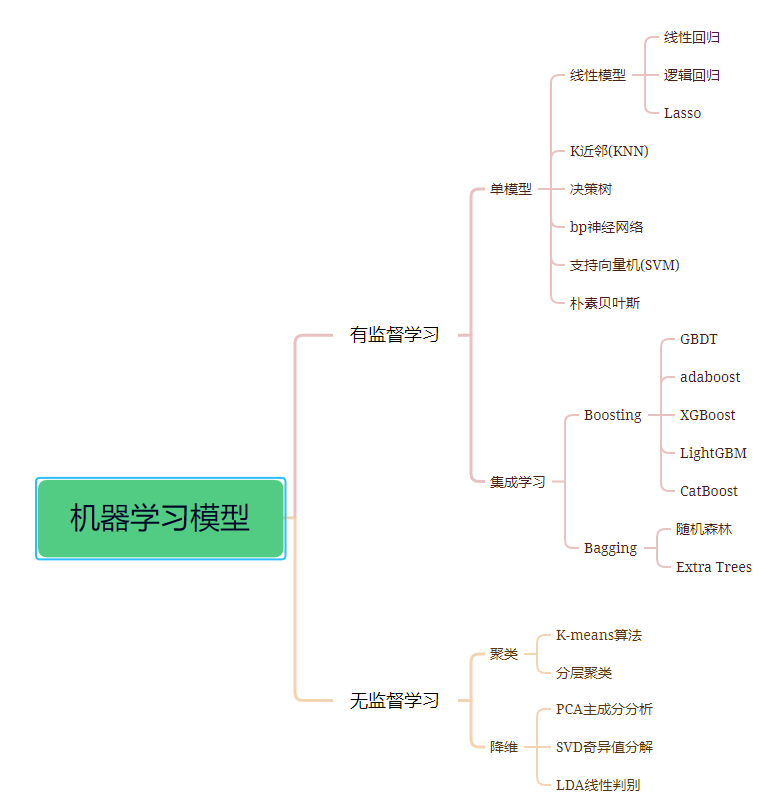
1. Supervised Learning
-
Classification problems: Predicting the category of a sample (discrete). For example, determining gender, health status, etc. -
Regression problems: Predicting the corresponding real number output of a sample (continuous). For example, predicting the average height of people in a region.
1.1 Single Model
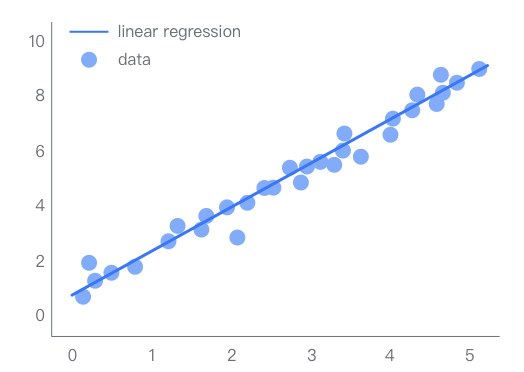
Linear regression refers to a regression model composed entirely of linear variables. In linear regression analysis, there is only one independent variable and one dependent variable, and their relationship can be approximated by a straight line; this type of regression analysis is called univariate linear regression analysis.
If the regression analysis includes two or more independent variables, and the relationship between the dependent variable and the independent variables is linear, it is called multivariate linear regression analysis.
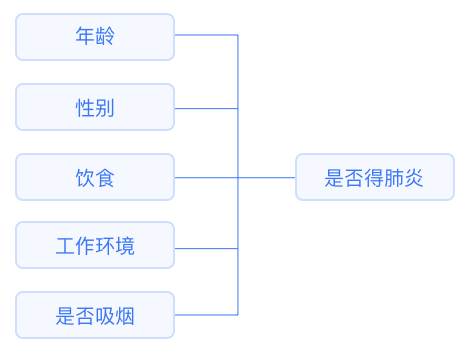
Used to study the influence relationship between X and Y when Y is categorical data. If Y has two categories, such as 0 and 1 (for example, 1 means willing and 0 means not willing, 1 means purchased and 0 means not purchased), this is called binary logistic regression; if Y has three or more categories, it is called multinomial logistic regression.
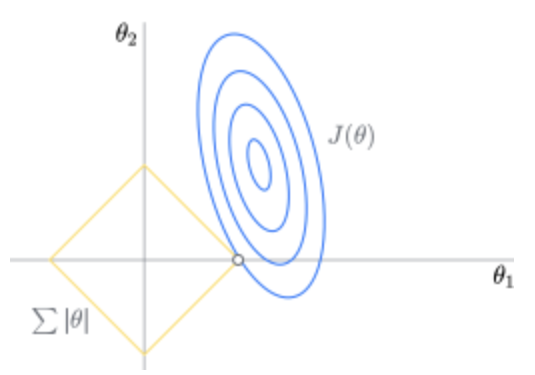
1.13 Lasso
The main difference between KNN for regression and classification lies in the decision-making process during the final prediction. When KNN does classification predictions, it generally uses majority voting, that is, predicting the class of the sample based on the K nearest samples in the training set.
When KNN performs regression, it generally uses the average method, predicting the regression value as the average of the outputs of the K nearest samples. However, their theories are the same.
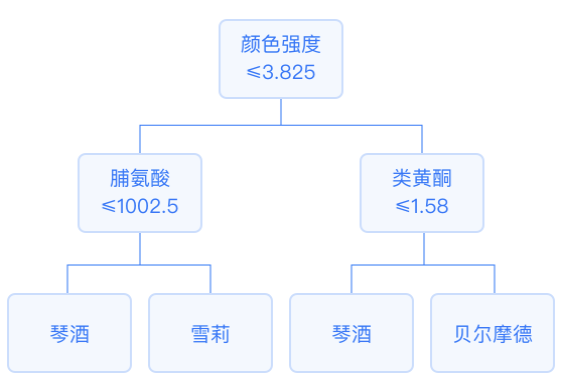
In a decision tree, each internal node represents a splitting question: it specifies a test on an attribute of the instance, dividing the samples that reach that node according to a specific attribute, with each successor branch corresponding to a possible value of that attribute.
Classification trees output the mode of the output variable among the samples in the leaf node as the classification result. The regression tree outputs the mean of the output variable among the samples in the leaf node as the prediction result.
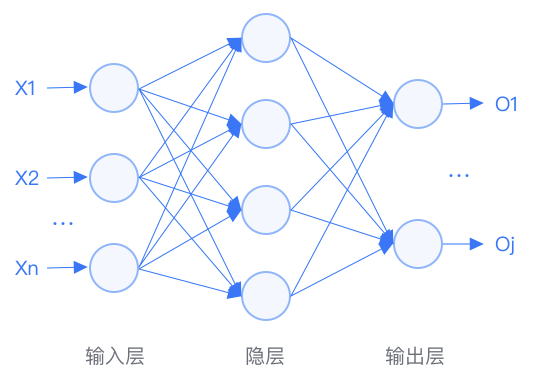
BP neural networks are a type of multilayer feedforward network trained by the error backpropagation algorithm, and one of the most widely used neural network models today. The learning rule of BP neural networks uses the steepest descent method to continuously adjust the network’s weights and thresholds through backpropagation to minimize the classification error rate (the sum of squared errors).
-
The first phase is forward signal propagation from the input layer through the hidden layer to the output layer; -
The second phase is backward error propagation from the output layer to the hidden layer, finally reaching the input layer, adjusting the weights and biases from the hidden layer to the output layer and from the input layer to the hidden layer in sequence.

Support Vector Machine Regression (SVR) maps data to high-dimensional feature space using nonlinear mapping, ensuring that in the high-dimensional feature space, the independent and dependent variables exhibit good linear regression characteristics. After fitting in that feature space, it returns to the original space.
Support Vector Machine Classification (SVM) is a type of generalized linear classifier that performs binary classification of data using supervised learning, with its decision boundary being the maximum margin hyperplane solved from the training samples.
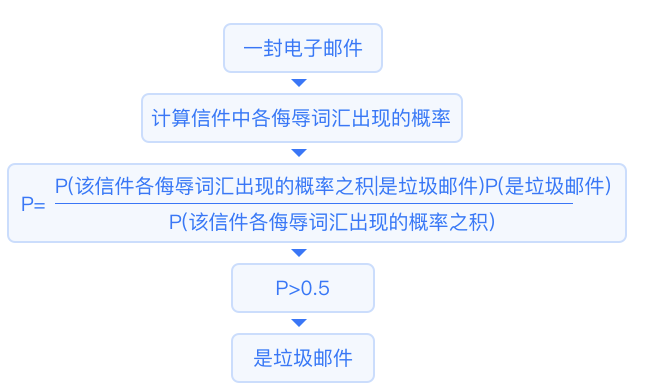
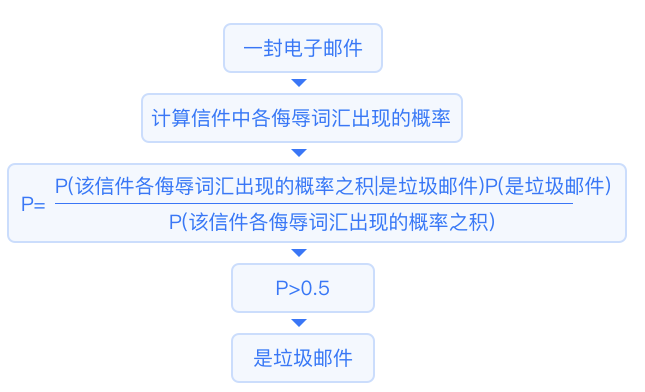
This algorithm assumes that all variables are mutually independent.
1.2 Ensemble Learning

-
Boosting
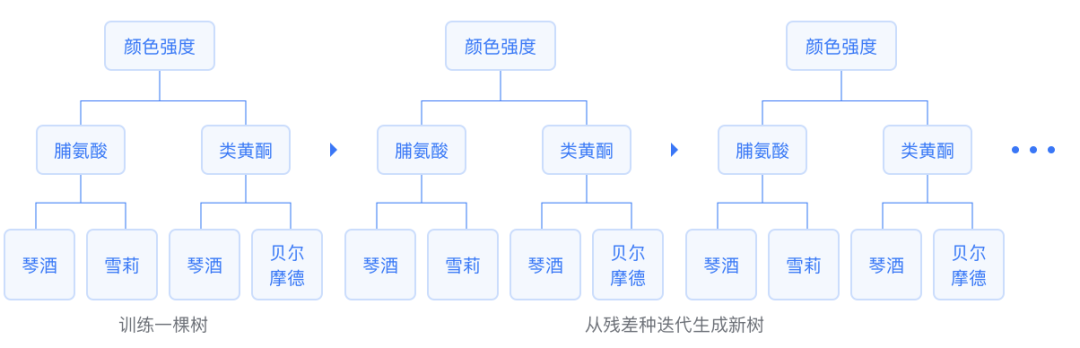
GBDT is a Boosting algorithm based on CART regression trees, which is an additive model that serially trains a set of CART regression trees, ultimately summing the predictions of all regression trees to obtain a strong learner. Each new tree fits the negative gradient direction of the current loss function. Finally, the sum of this set of regression trees outputs the regression result or applies the sigmoid or softmax function to obtain binary or multi-class results.
1.22 AdaBoost
AdaBoost assigns a high weight to learners with low error rates and a low weight to learners with high error rates, combining weak learners with corresponding weights to generate a strong learner. The difference between regression and classification algorithms lies in the way error rates are calculated; classification problems generally use the 0/1 loss function, while regression problems generally use squared loss functions or linear loss functions.
1.23 XGBoost