This article is about 11,000 words long and is recommended to be read in 6 minutes. This article introduces large models + RAG.
Large Language Models (LLMs) have limitations when handling domain-specific or highly specialized queries, such as generating inaccurate information or “hallucinations.” A promising approach to mitigate these limitations is Retrieval-Augmented Generation (RAG), which acts like a plugin that integrates external data retrieval into the generation process, enhancing the model’s ability to provide accurate and relevant responses.
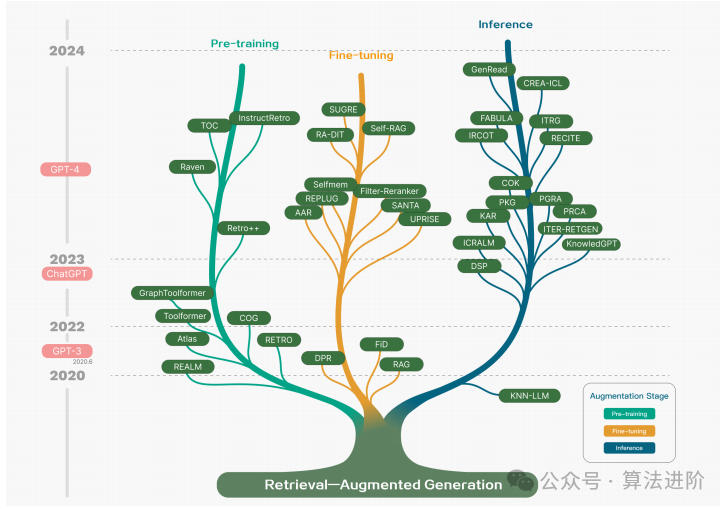
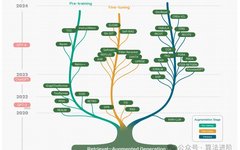
Figure 1 RAG Technology Development Tree
The main content of this article is as follows:
-
It reviews the current state-of-the-art RAG technologies, including naive RAG, advanced RAG, and modular RAG paradigms, and elaborates on their development history. In the context of LLMs, this article provides a comprehensive and systematic exploration of the broader field of RAG research.
-
It focuses on the core technologies in the RAG process, particularly the three aspects of “retrieval,” “generation,” and “augmentation.” The article analyzes how these three components work together and clarifies how they collaborate to form a cohesive and effective RAG framework.
-
A comprehensive evaluation framework for RAG is constructed, including evaluation objectives and metrics, analyzing its advantages and disadvantages from multiple perspectives, while predicting its future development direction and potential enhancements. Additionally, the expansion and ecosystem development to address current challenges are emphasized.
RAG is a pattern that enhances LLMs by integrating external knowledge bases, employing a collaborative approach that combines information retrieval mechanisms and In-Context Learning (ICL) to improve LLM performance. The RAG workflow consists of three key steps: first, the corpus is divided into discrete chunks, and then a vector index is constructed using an encoder model. Second, RAG identifies and retrieves chunks based on their vector similarity to the query and indexed chunks. Finally, the model synthesizes a response conditioned on the contextual information obtained from the retrieved chunks. These steps form the fundamental framework of the RAG process, supporting its information retrieval and context-aware generation capabilities. The key advantage of RAG lies in that it does not require retraining the LLM for specific tasks; developers can add external knowledge bases to enrich the input and thereby improve the model’s output accuracy.
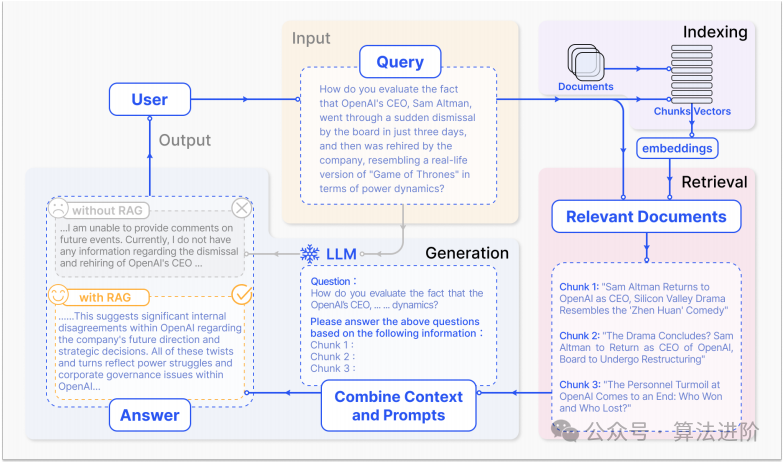
Figure 2 RAG Technology in QA Problems
The RAG research paradigm has undergone continuous evolution, mainly categorized into naive RAG, advanced RAG, and modular RAG. While RAG is cost-effective and outperforms native LLMs, it also exhibits some limitations. To address specific shortcomings in naive RAG, advanced RAG and modular RAG were developed.
Naive RAG follows a traditional workflow that includes indexing, retrieval, and generation.
Indexing. The indexing process during data preparation is a crucial initial step that involves multiple stages, from data cleaning and extraction to file format conversion and chunking, followed by transforming the embedding model into vector representations and creating an index. Indexing facilitates similarity comparisons during the retrieval phase and stores text segments and their vector embeddings as key-value pairs, enabling efficient and scalable search capabilities.
Retrieval. The system transcodes user queries, generates vector representations, and computes similarity scores between the query vector and chunks in the indexed corpus. The system prioritizes retrieving the chunks most similar to the query, which are then used as the basis for extending context to respond to user requests.
Generation. Large language models are used to synthesize responses based on prompts, allowing them to leverage parameter knowledge or constraints within the provided documents. Dialogue history can also be integrated into prompts for multi-turn conversational interactions. The model’s method of answering questions may vary depending on specific task standards.
Disadvantages of Naive RAG. Naive RAG faces challenges in the three key areas of retrieval, generation, and augmentation. Low retrieval quality leads to mismatched chunks, hallucinations, and dropouts, hindering the ability to construct comprehensive responses. Generation quality raises hallucination challenges, where the model generates answers not based on the provided context, leading to irrelevant context and potential toxicity or bias issues. The augmentation process struggles to effectively combine context from retrieved paragraphs with the current generation task, resulting in incoherent or inconsistent outputs. Repetition and redundancy are also issues, necessitating the determination of the importance and relevance of retrieved paragraphs and coordinating different writing styles and tones. The generation model’s over-reliance on augmented information poses risks, potentially leading to outputs that merely reiterate retrieved content without providing new value or synthesized information.
Advanced RAG addresses the shortcomings of Naive RAG through enhanced targeted retrieval strategies and improved indexing methods. It implements pre-retrieval and post-retrieval strategies and employs techniques such as sliding windows, fine-grained segmentation, and metadata to improve indexing methods. Additionally, various methods have been introduced to optimize the retrieval process, such as ILIN.
Pre-retrieval process. Optimizing data indexing can improve the quality of indexed content, thereby enhancing RAG system performance. This involves five main strategies: enhancing data granularity, optimizing index structure, adding metadata, alignment optimization, and hybrid retrieval. Enhancing data granularity aims to increase the degree of text normalization and context richness, optimizing index structure includes adjusting chunk sizes and utilizing graph data indexing to integrate information, adding metadata for filtering and integrating metadata to improve retrieval efficiency, and alignment optimization addresses alignment issues and discrepancies between documents.
Retrieval phase. In the retrieval phase, appropriate context is determined by calculating similarity between queries and chunks, with the embedding model being central. Fine-tuning the embedding model can enhance retrieval relevance in domain-specific contexts, and dynamic embeddings adapt based on the context used. Transformer models like BERT can capture contextual understanding but may not be as context-sensitive as the latest full-size language models.
Post-retrieval process. After merging valuable context retrieved from the database with the query, addressing challenges posed by context window limitations, re-ranking and prompt compression of the retrieved content are key strategies. Re-ranking methods include prioritizing document diversity, alternating the best documents at the beginning and end of the context window, and recalculating semantic similarity between relevant text and queries. Prompt compression methods include utilizing small language models to compute mutual information or perplexity of prompts and designing summarization techniques to enhance LLM’s key information perception.
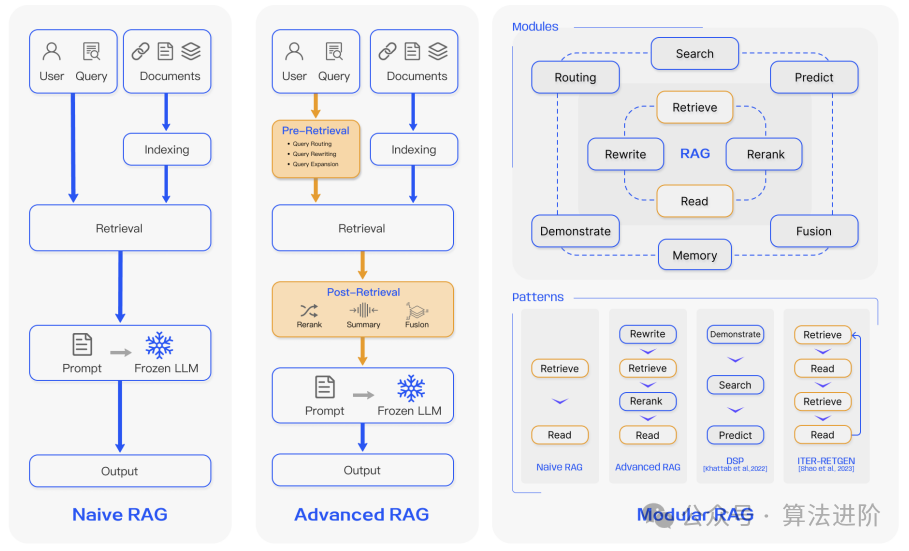
Figure 3 Comparison of RAG Paradigms
Modular RAG structure is a new type of RAG framework that offers greater flexibility and adaptability, allowing for the integration of various methods to enhance functional modules and address specific problems. The modular RAG paradigm is gradually becoming the norm, allowing for serial pipelines or end-to-end training methods across multiple modules. Advanced RAG is a specialized form of modular RAG, while Naive RAG is a special case of advanced RAG. The relationship between these three paradigms is one of inheritance and development.
The new module search module is customized for specific scenarios and incorporates direct search of additional corpora, achieving integration through code, query languages, and other customized tools generated by LLMs, with data sources including search engines, text data, tabular data, and knowledge graphs.
The memory module utilizes the memory capabilities of LLMs to guide retrieval, identifying memories most similar to the current input and iteratively creating an unbounded memory pool through the retrieval-augmented generator, making the text more consistent with the data distribution during inference.
The fusion method enhances traditional search systems by employing multi-query approaches, using LLMs to expand user queries to multiple different perspectives, revealing deeper transformative knowledge. The fusion process includes parallel vector searches of original and expanded queries, intelligent re-ranking to optimize results, and pairing the best results with new queries.
The RAG system’s retrieval process utilizes multiple sources, alternately or jointly using them as needed, with query routing determining subsequent actions for user queries, including summarization, searching specific databases, or merging different paths into a single response. The query router selects the appropriate data storage for the query, with decisions predefined and executed via LLM calls.
The prediction module utilizes LLMs to generate necessary content, addressing redundancy and noise issues in retrieved content, with generated content more likely to contain relevant information.
The task adapter enables RAG to adapt to various downstream tasks, UPRISE automatically retrieves prompts from pre-built data pools, supporting zero-shot task inputs, enhancing cross-task and model generalization. PROMPTAGATOR uses LLMs as few-shot query generators, creating task-specific retrievers, leveraging a few examples to develop task-specific end-to-end retrievers.
Modular RAG exhibits high adaptability, allowing for the replacement or rearrangement of modules in the RAG process to fit specific problem contexts. Current research primarily explores two organizational paradigms: one is adding or replacing modules, and the other is adjusting the organizational processes between modules. This flexibility enables the customization of the RAG process as needed, effectively addressing various tasks.
Optimizing the RAG Pipeline
Optimizing the RAG pipeline to enhance information efficiency and quality by integrating various search techniques, improving retrieval steps, incorporating cognitive backtracking, implementing multifunctional query strategies, and utilizing embedding similarities, achieving a balance between retrieval efficiency and the depth of contextual information. Methods such as hybrid search exploration, recursive retrieval and query engines, backtracking prompt methods, subqueries, and hypothesis document embeddings are used to optimize the RAG pipeline. These methods help generate responses to backtracking prompts and the final answer generation process. However, this approach may not always yield satisfactory results, especially when the language model is unfamiliar with the topic, potentially leading to more erroneous instances.
In RAG, the key to efficiently retrieving relevant documents lies in addressing three issues: 1) how to achieve precise semantic representation; 2) how to coordinate the semantic spaces of queries and documents; 3) how to align the output of the retriever with the preferences of large language models.
4.1 Strengthening Semantic Representation
The semantic space in RAG is crucial for the multi-dimensional mapping of queries and documents, and its retrieval accuracy significantly impacts results. This section introduces two methods to establish accurate semantic spaces.
When managing external documents, determining the appropriate chunk size is vital to ensure the accuracy and relevance of retrieval results. Selecting an appropriate chunking strategy requires consideration of the nature of indexed content, the embedding model, the expected length and complexity of user queries, and the application’s use case. Current research in the RAG field explores various chunk optimization techniques to improve retrieval efficiency and accuracy. The combination of diverse methods such as summarization embedding techniques, metadata filtering techniques, and graph indexing techniques has made significant progress, thereby enhancing retrieval results and RAG performance.
Fine-tuning Embedding Models
Once the chunk size is determined, the next step is to use embedding models to embed chunks and queries into the semantic space. The effectiveness of the embedding model is crucial as it affects the model’s ability to represent the corpus. Recent studies have introduced notable embedding models such as AngIE, Voyage, and BGE. These models are pre-trained on extensive corpora, but their ability to accurately capture domain-specific information may be limited when dealing with specialized fields. Fine-tuning embeddings for specific tasks is essential to ensure that the model understands user queries in a contextually relevant manner. Embedding fine-tuning methods primarily include two main paradigms: domain knowledge fine-tuning and downstream task fine-tuning. Domain knowledge fine-tuning requires using domain-specific datasets, while the datasets for model fine-tuning include queries, corpora, and relevant documents. Downstream task fine-tuning is a critical step to enhance model performance, such as methods like PROMPTAGATOR and LLM-Embedder that leverage LLM capabilities to fine-tune embedding models.
4.2 Aligning Queries and Documents
In RAG applications, the retriever can use embedding models to encode queries and documents or use different models for each. Original queries may be affected by imprecise wording and lack of semantic information; thus, aligning the semantic space of user queries with that of documents is crucial. This section introduces two basic techniques to achieve this alignment.
Query rewriting is a method used to align the semantics of queries and documents by combining the original query with additional guidance to create pseudo-documents, or using textual clues to construct query vectors to generate “hypothetical” documents, or altering the traditional retrieval and reading order to focus on query rewriting, or leveraging LLMs for advanced concept abstraction reasoning and retrieval. Multi-query retrieval methods also utilize LLMs to simultaneously generate and execute multiple search queries to address complex problems with multiple sub-questions.
LlamaIndex optimizes the representation of query embeddings by introducing adapter modules, mapping them into latent spaces more closely aligned with the intended tasks. SANTA enhances the retriever’s sensitivity to structured information through two pre-training strategies: first, leveraging intrinsic alignment between structured and unstructured data to guide contrastive learning in pre-training schemes under structured awareness; second, implementing masked entity prediction to encourage the language model to predict and fill in masked entities, thereby facilitating a deeper understanding of structured data. SANTA particularly addresses the differences between structured and unstructured data, improving the retriever’s ability to identify structured information by aligning queries with structured external documents.
4.3 Aligning the Retriever and LLM
In the RAG pipeline, improving retrieval hit rates does not necessarily enhance final results, as retrieved documents may not meet the needs of LLMs. This section introduces two methods to align the output of the retriever with the preferences of LLMs.
Fine-tuning the Retriever
Several studies utilize feedback signals from language models (LLMs) to refine retrieval models. Among them, Yu et al. use an encoder-decoder architecture to provide supervisory signals for the retriever, identifying LM-preferred documents through FiD cross-attention scores, and fine-tuning the retriever using hard negative sampling and standard cross-entropy loss. Additionally, it is suggested that LLMs may prefer readable documents over information-rich ones. Shi et al. leverage the retriever and LLM to compute the probability distribution of retrieved documents, supervising training through KL divergence. UPRISE uses a frozen LLM to fine-tune the retriever, supervising the retriever’s training based on scores provided by the LLM. Furthermore, four methods for supervised fine-tuning embedding models are proposed to enhance the synergy between the retriever and LLM, thereby improving retrieval performance and accurately responding to user queries.
Challenges can arise during fine-tuning models, such as integrating functionality through APIs or addressing limited local computational resources. Some methods choose to adopt external adapters to assist alignment. PRCA trains adapters through a context extraction phase and a reward-driven phase, optimizing the output of the retriever using a token-based autoregressive strategy. Additionally, PKG introduces an innovative method to integrate knowledge into white-box models through instruction fine-tuning, which helps address difficulties encountered during fine-tuning and enhances model performance. Furthermore, RECOMP introduces extractive and generative compressors for summarization generation.
One of the key components of RAG is the generator, which is responsible for converting retrieved information into coherent, fluent text. The generator enhances accuracy and relevance by integrating retrieved data and is guided by the retrieved text to ensure consistency between the generated text and the retrieved information. This comprehensive input enables the generator to gain a deeper understanding of the context of the question, providing more informative and contextually relevant responses. The introduction of the generator helps improve large models’ adaptability to input data.
5.1 Using Frozen LLM for Post-Retrieval
In the realm of non-callable LLMs, research relies on large models like GPT-4 to synthesize information, but there are issues with context length limitations and susceptibility to redundant information. To address these issues, research has shifted to post-retrieval processing, which involves handling, filtering, or optimizing relevant information retrieved from large document databases to improve the quality of retrieval results, making them more aligned with user needs or subsequent tasks. Common operations in post-retrieval processing include information compression and result re-ranking.
The context length limitation of large language models poses a challenge, and information compression is significant for reducing noise, addressing context length limitations, and enhancing generation effects. PRCA and RECOMP are two research projects that tackle this issue by training information extractors and using contrastive learning to train information compressors. Another research project proposes the “Filter-Reranker” paradigm, which combines the advantages of LLMs and small language models (SLMs) to reduce the number of documents, enhancing the accuracy of model responses.
Re-ranking models play a crucial role in optimizing the set of documents retrieved by the retriever, prioritizing the most relevant items through reordering document records, thus limiting the total number of documents and improving retrieval efficiency and response speed. This approach also incorporates context compression to provide more accurate retrieval information. Re-ranking models serve a dual role throughout the information retrieval process, acting as both optimizers and refiners.
5.2 Fine-tuning LLM for RAG
Optimizing the generator within the RAG model is a critical aspect, as the role of the generator is to receive retrieved information and generate relevant text. Fine-tuning the model becomes essential to adapt to input queries and retrieved documents. In RAG, the fine-tuning methods for the generator align with general fine-tuning methods for LLMs. To enhance the performance of the generator, post-processing of retrieved documents is necessary, along with exploring representative work for data and optimization functions.
Overall Optimization Process
Part of the overall optimization process involves training data typically comprising input-output pairs, aimed at training the model to generate output y based on input x. In self-memory work, a traditional training process is employed, where given input x, relevant documents z are retrieved, and after integration of (x, z), the model generates output y. Training data usually includes input-output pairs, designed to train the model to generate output based on input. In joint encoder and dual encoder paradigms, a standard encoder-decoder model or two independent encoders are used to encode inputs and documents, followed by using a decoder for bidirectional cross-attention processing. Both architectures use Transformers as foundational blocks and are optimized.
Utilizing Contrastive Learning
Traditional methods in training language models may lead to “exposure bias,” where the model is trained based solely on a single, correct output example, limiting its range of potential outputs. To address this issue, SURGE proposes using graph-text contrastive learning methods to encourage the model to generate a series of plausible and coherent responses, reducing overfitting and enhancing the model’s generalization ability. For retrieval tasks involving structured data, the SANTA framework implements a three-part training scheme, including preliminary training phases for the retriever and generator, and another phase for generator training, effectively encapsulating the subtle differences between structure and semantics, fostering the model’s understanding of the semantic structure of text data, and facilitating the alignment of relevant entities within structured data.
Three key technologies in the development of RAG: enhancement stages, data sources, and processes. Figure 4 illustrates the classification of RAG’s core components.
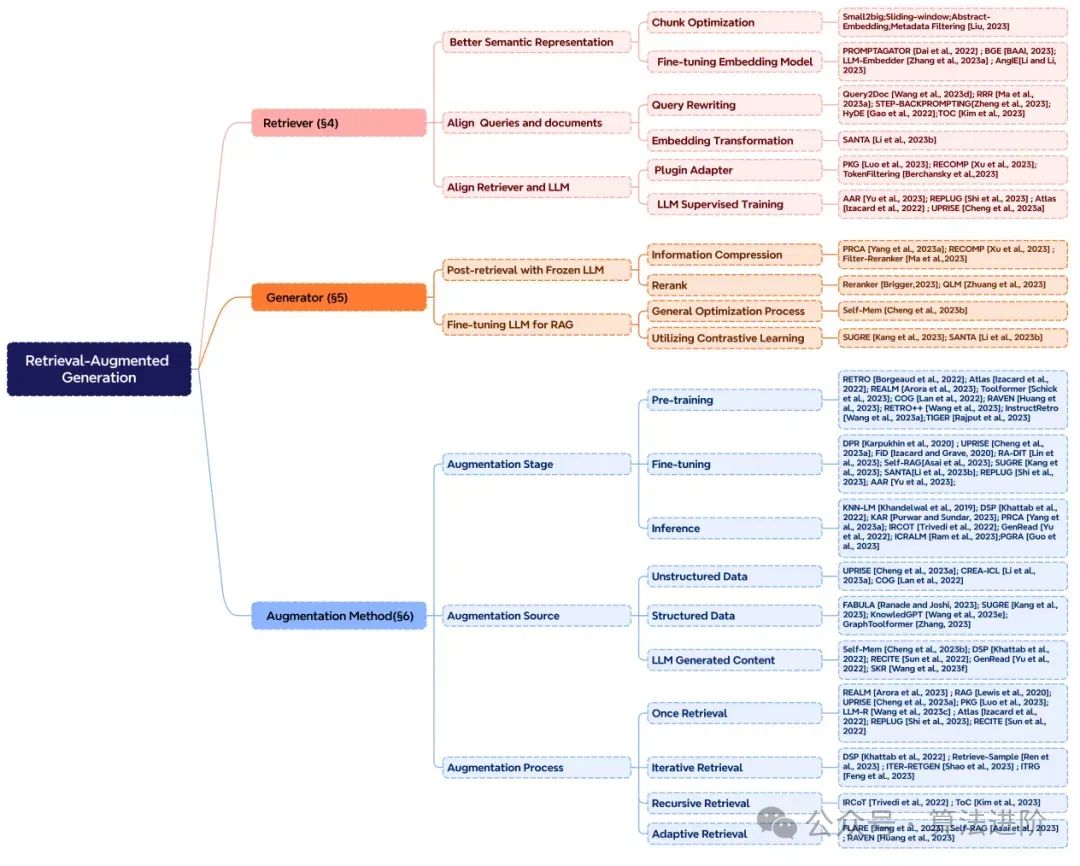
Figure 4 Classification System of RAG’s Core Components
6.1 Enhancement Stages of RAG
RAG is a knowledge-intensive work that integrates various technical methods during the pre-training, fine-tuning, and inference stages of language model training.
During the pre-training stage, researchers enhance open-domain QA PTMs through retrieval-based strategies. The REALM model employs a structured, interpretable method for knowledge embedding and utilizes retrieval augmentation for large-scale pre-training. RETRO pre-trains from scratch using retrieval augmentation and reduces model parameters to surpass standard GPT models in perplexity. COG introduces a novel text generation method that simulates copying text snippets from existing collections. Enhanced pre-training methods exhibit strong performance and parameter utilization but face challenges such as the need for large pre-training datasets and resources, as well as decreasing update frequencies with increasing model scale. Empirical evidence highlights significant improvements in knowledge-intensive applications through this approach.
RAG and fine-tuning are important tools for enhancing LLMs, and their combination can better meet specific contextual needs. Fine-tuning the retriever can optimize semantic representation, coordinate retrieval with generation models, and enhance generalization and adaptability. Fine-tuning the generator can customize and stylize outputs, adapt to different input formats, and build specific instruction datasets. Collaborative fine-tuning can enhance model generalization and avoid overfitting, but it is resource-intensive. While fine-tuning requires dedicated datasets and significant computational resources, it can reduce pre-training resource consumption and customize models to meet specific needs. In summary, fine-tuning is crucial for RAG models to adapt to specific tasks, refining both the retriever and generator, enhancing model diversity and adaptability.
The inference stage of RAG models is critical, with extensive integration with LLMs. Traditional RAG introduces retrieval content to guide generation during the inference stage. To improve this, advanced technologies have introduced richer contextual information in inference. The DSP framework facilitates natural language text exchange between frontier LMs and retrieval models, enriching context and improving generation results. The PKG method equips LLMs with knowledge-guided modules that can retrieve information to execute complex tasks without modifying LLM parameters. CREAICL enhances context through cross-lingual knowledge retrieval, while RECITE generates context by directly sampling paragraphs from LLMs. ITRG identifies the correct reasoning path through iterative retrieval, enhancing task adaptability. ITERRETGEN employs an iterative strategy, merging retrieval and generation into a cyclical process, alternating between