Introduction
This article will compare the evaluation methods of RAG from a timeline perspective. These evaluation methods are not limited to the RAG process, and the evaluation methods based on LLM are more applicable across various industries.
Common Evaluation Methods for RAG
In the previous section, we discussed how to use the ROUGE method to evaluate the similarity of summaries. Due to space limitations, we did not cover the evaluation between images and text, as the scenarios involving image and text evaluation are commonly found in the RAG process, including retrieval evaluation methods and generation evaluation methods. Among them, the generation evaluation method evaluates the model’s generation capability indirectly by assessing the answers, which is also applicable to our evaluation of images and context.
Additionally, this article will provide a detailed explanation of the evaluation methods for other important content in RAG.
Retrieval Evaluation Metrics
The common retrieval evaluation methods include various types of evaluations for text and images, each focusing on different aspects without any good or bad distinctions.
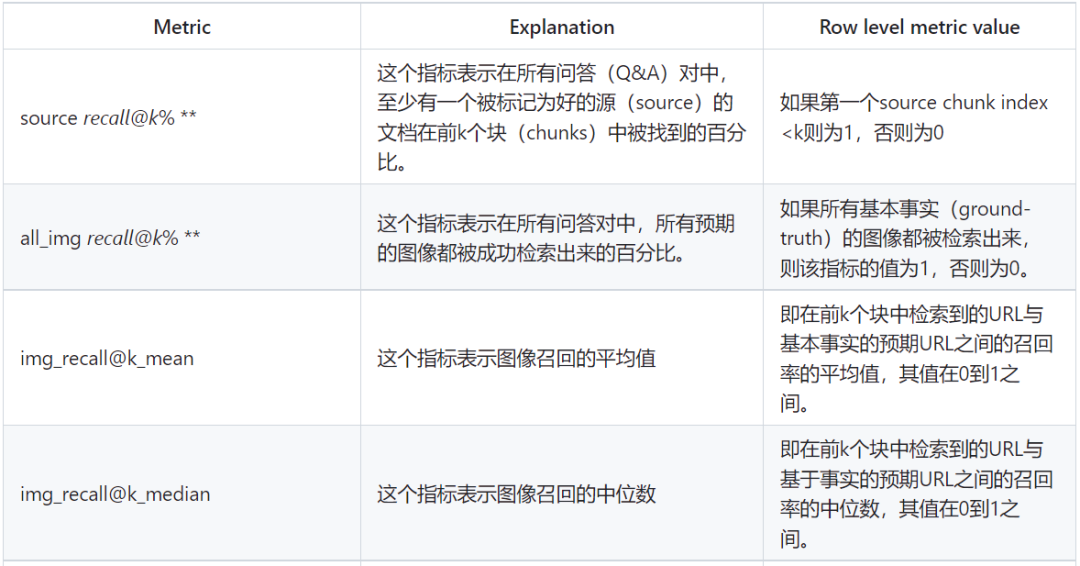
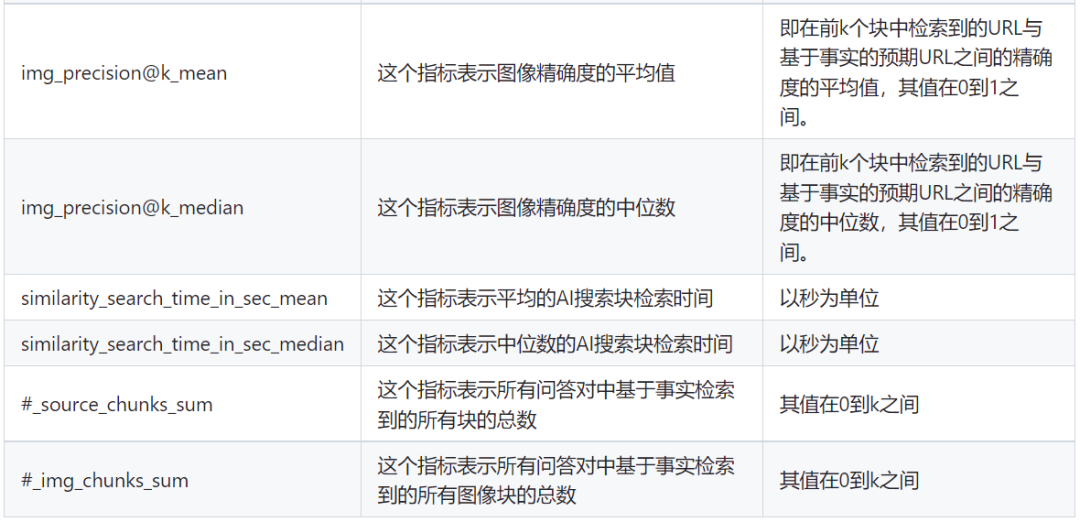
Here, **k is generally taken as 10, 5, or 3.
Generation Evaluation Metrics
These metrics are used to measure a system’s performance in handling question and answer (Q&A) tasks, especially when involving large language models (LLM) and visual enhancement services. Below is an explanation of each metric in the table:
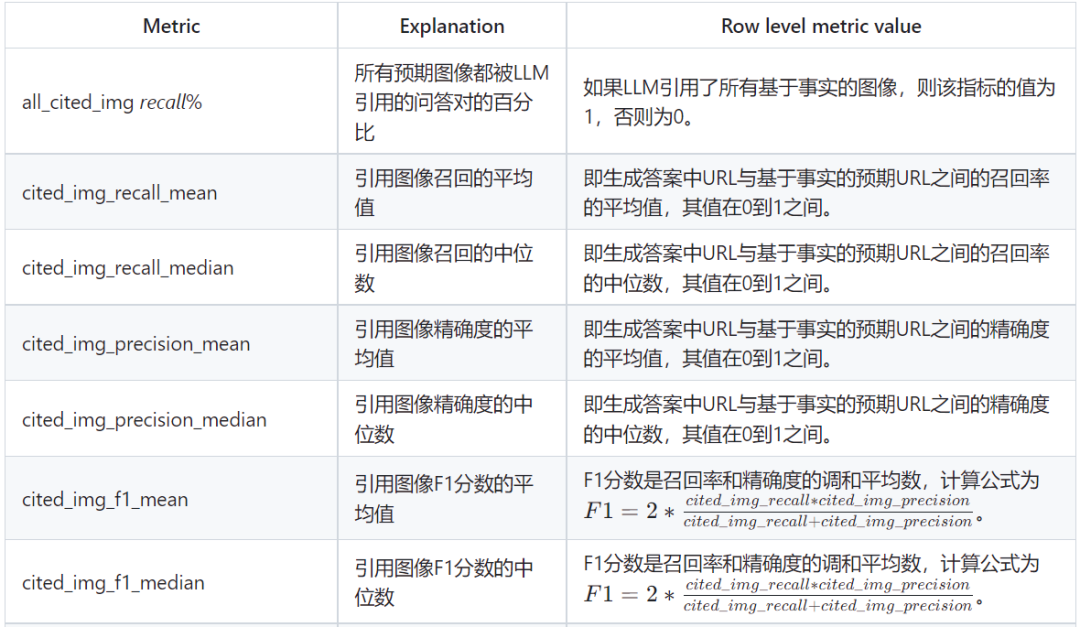
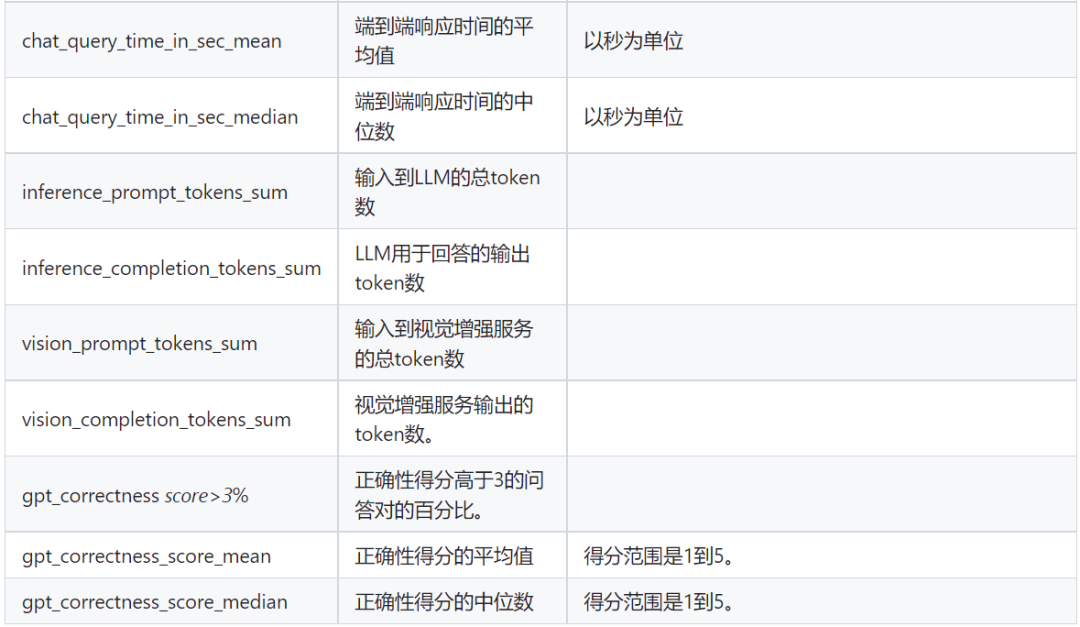
The description of the table emphasizes the importance of these metrics, providing valuable insights into the effectiveness of each part of the system. These metrics help to measure the search capability and generation part of the system separately, in order to understand the impact of experiments on each component.
Common Experimental Improvement Processes for RAG
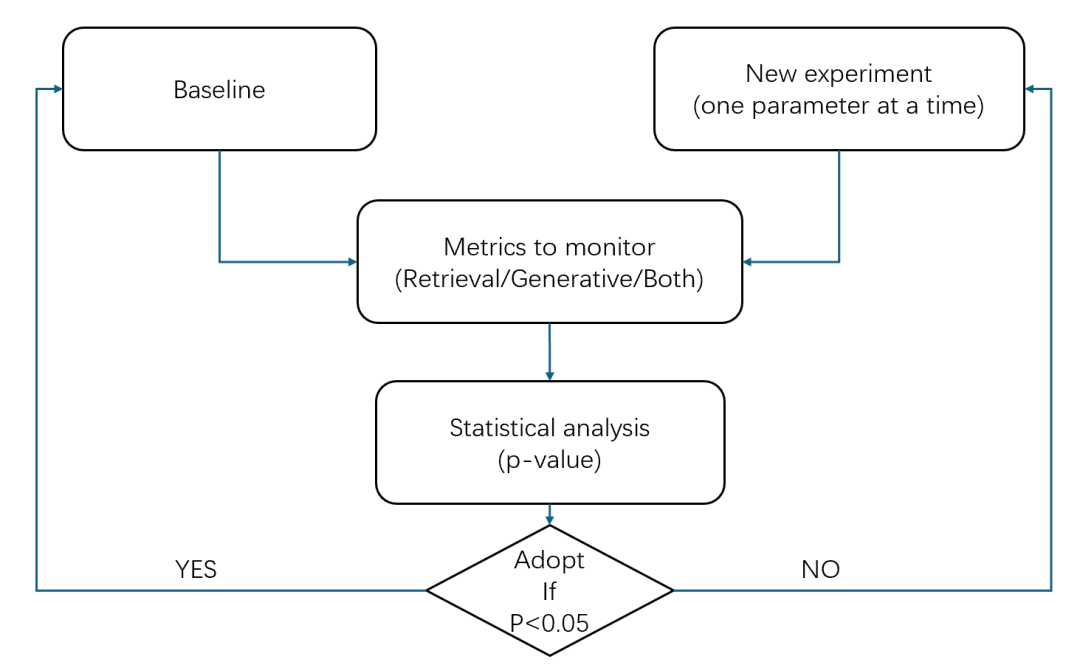
We conduct experiments by systematically testing different methods, adjusting one configuration at a time, and assessing its impact on a predefined baseline. We use the specific retrieval and generation metrics outlined below to evaluate performance. A detailed analysis of these metrics helps us decide whether to update the baseline with new configurations or retain existing ones.
Q&A Evaluation Dataset
To conduct accurate evaluations during experiments, it is crucial to compile a diverse set of question and answer pairs. These Q&A pairs should cover a range of articles, encompassing various data formats, lengths, and topics. This diversity ensures comprehensive testing and evaluation, enhancing the reliability of the results and insights obtained. Below are examples of Q&A datasets for reference.
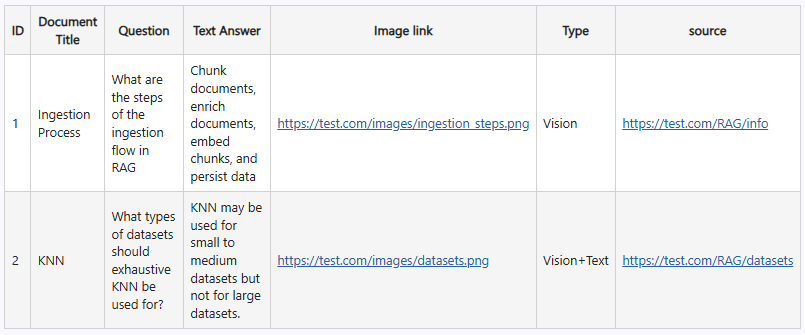
The dataset should ensure a balanced representation of questions in the Q&A dataset, including questions from both text and images, as well as some questions solely from images. Additionally, ensure that questions are distributed across various source documents.
When the evaluation set is relatively small, diversity can be ensured by incorporating various edge cases. This can start with thorough exploratory data analysis (EDA), extracting features such as article length, table length, number of text tables, and types of images, resolutions, and numbers of images. Then, carefully distribute the evaluation set across these features to achieve comprehensive representation and robust coverage in the feature space. Moreover, the system also supports alternative sources and images for the same question.
Practical Evaluation of Images
# Simulated retrieval results, i.e., results returned by the retrieval algorithm
retrieved_images = ['img1.jpg', 'img2.jpg', 'img3.jpg', 'img4.jpg', 'img5.jpg']
# True labeled results, i.e., all images related to the query
ground_truth_images = ['img1.jpg', 'img2.jpg', 'img3.jpg', 'img6.jpg', 'img7.jpg']
# Calculate recall rate
def calculate_recall(retrieved, ground_truth):
# Convert lists to sets for set operations
retrieved_set = set(retrieved)
ground_truth_set = set(ground_truth)
# Calculate recall rate
recall = len(retrieved_set.intersection(ground_truth_set)) / len(ground_truth_set)
return recall
# Call the function to calculate recall rate
recall = calculate_recall(retrieved_images, ground_truth_images)
print(f"Recall Rate: {recall:.2f}")Here, we abstract it in a relatively simple way. The specifics of extracting image tags from markdown will not be elaborated on, as they are quite similar.

Overview of Evaluation Methods
Evaluation methods measure the performance of our system. Manual evaluation (human review) of each summary is both time-consuming and costly, and it is not scalable, so automatic evaluation is usually used to supplement it. Many automatic evaluation methods attempt to measure the text quality that human evaluators would consider. These qualities include fluency, coherence, relevance, factual consistency, and fairness. The content or style similarity to reference texts is also an important quality of generated texts.
The following figure includes many metrics used to evaluate LLM-generated content and their classification methods.
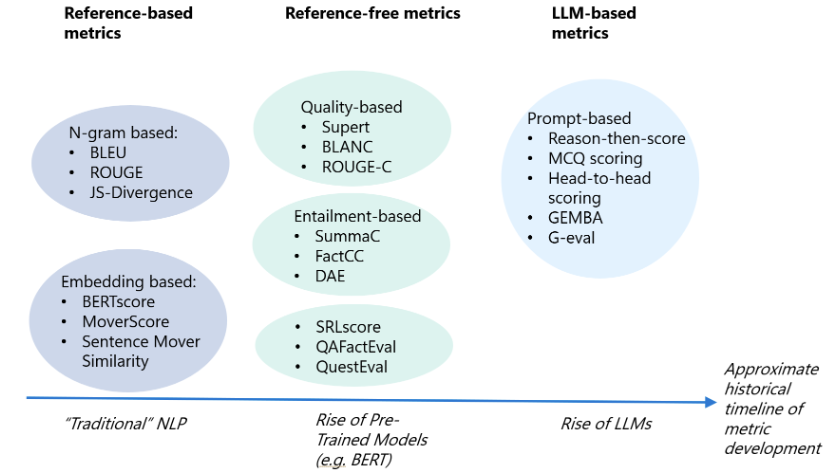
Reference-based Metrics
Reference-based metrics are used to compare generated text with references (human-annotated ground truth texts). Many such metrics were developed for traditional NLP tasks before LLM development, but they are still applicable to text generated by LLMs.
N-gram based metrics
Metrics like BLEU (Bilingual Evaluation Understudy), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), and JS divergence (JS2) are overlap-based metrics that use n-grams to measure the similarity between output text and reference text.
BLEU Score
BLEU (Bilingual Evaluation Test) score is used to evaluate the quality of machine-translated text from one natural language to another. Therefore, it is commonly used in machine translation tasks, but also in other tasks such as text generation, paraphrase generation, and text summarization. The basic idea is to calculate precision, which is the ratio of candidate words in the reference translation. The score is calculated by comparing individual translation segments (usually sentences) to a set of high-quality reference translations. Then, these scores are averaged across the entire corpus to estimate the overall quality of the translation. Punctuation or grammatical correctness is not considered during scoring.
It is rare for human translations to achieve a perfect BLEU score, as a perfect score indicates that the candidate translation is identical to one of the reference translations. Therefore, there is no need to achieve a perfect score. Considering that the chances of matching increase with multiple reference translations, we encourage providing one or more reference translations, which will help maximize the BLEU score.

Typically, the above calculations consider candidate words or token phrases that appear in the target. However, to evaluate matching more accurately, bi-grams or even tri-grams can be calculated, and the scores obtained from various n-grams can be averaged to calculate the overall BLEU score.
ROUGE
In contrast to the BLEU score, Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics measure recall. It is commonly used to evaluate the quality of generated text and machine translation tasks. However, since it measures recall, it is used for summarization tasks. In these types of tasks, it is more important to assess the number of words the model can recall.
The most popular evaluation metrics in the ROUGE category are ROUGE-N and ROUGE-L:

Text Similarity Metrics
Text similarity metrics focus on calculating similarity by comparing the overlap of words or sequences of words between text elements. They can be used to generate similarity scores for the predicted outputs of LLMs and reference standard texts. These metrics can also indicate how well the model performs across various tasks.
Levenshtein Similarity Ratio
The edit similarity ratio is a string metric used to measure similarity between two sequences. This metric is based on edit distance. Simply put, the edit distance between two strings is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one string into another. The edit similarity ratio can be calculated using the edit distance value and the total length of both sequences, defined as follows:
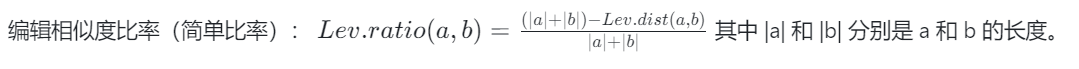
Several different methods have derived from the simple edit similarity ratio:
Partial ratio: Similarity is calculated by taking the shortest string and comparing it with the same-length substring in the longer string.
Token sorting ratio: The string is first split into individual words or tokens, then the tokens are sorted alphabetically, and finally, they are reassembled into a new string to calculate similarity. This new string is then compared using the simple ratio method.
Token-set Ratio: The string is first split into individual words or tokens, and then the intersection and union of the token sets between the two strings are calculated to determine similarity.
Semantic Similarity Metrics
BERTScore, MoverScore, and Sentence Mover Similarity (SMS) are metrics that rely on contextual embeddings to measure similarity between two pieces of text. Although these metrics are relatively simple, fast, and computationally inexpensive compared to LLM-based metrics, research shows that they have poor correlation with human evaluators, lack interpretability, have inherent biases, poor adaptability to various tasks, and fail to capture nuances in language.
The semantic similarity between two sentences refers to how closely related their meanings are. To achieve this, each string is first represented as a feature vector to capture its semantic meaning. A common approach is to generate embeddings for the strings (e.g., using LLM) and then use cosine similarity to measure the similarity between the two embedding vectors. More specifically, given an embedding vector (A) representing the target string and an embedding vector (B) representing the reference string, the cosine similarity is calculated as follows:
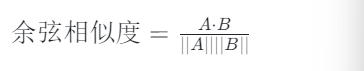
As shown above, this metric measures the cosine of the angle between two non-zero vectors, ranging from -1 to 1. A value of 1 indicates that the two vectors are the same, while -1 indicates that they are dissimilar.
Reference-free Metrics
Reference-free (context-based) metrics generate scores for the generated text without relying on ground truth facts. They evaluate based on context or source documents. Many such metrics were developed to address the challenges of creating ground truth data. These methods tend to be more up-to-date than reference-based techniques, reflecting the growing demand for scalable text evaluation as PTMs become increasingly powerful. These metrics include quality-based, entailment-based, factuality-based, QA-based, and QG-based metrics.
Quality-based summary metrics. These methods detect whether the summary contains relevant information. SUPERT quality measures the similarity of the summary to a BERT-based pseudo-reference, while BLANC quality measures the accuracy difference of two masked tokens reconstructed. ROUGE-C is a modified version of ROUGE that does not require references and uses the source text as contextual comparison.
Entailment-based metrics. Entailment-based metrics are based on natural language inference (NLI) tasks, determining whether the output text (hypothesis) entails, contradicts, or undermines the given text (premise). This helps to detect factual inconsistencies. SummaC (Summary Consistency) benchmark, FactCC, and DAE (Dependency Arc Entailment) metrics can be used to detect factual inconsistencies with the source text. Entailment-based metrics are designed as classification tasks with “consistent” or “inconsistent” labels.
Factuality, QA, and QG-based metrics. Factuality-based metrics (e.g., SRLScore (Semantic Role Labeling) and QAFactEval) assess whether the generated text contains inaccurate information that does not align with the source text. QA-based (e.g., QuestEval) and QG-based metrics are used as another way to measure factual consistency and relevance.
Compared to reference-based metrics, reference-free metrics show improved correlation with human evaluators, but using reference-free metrics as a single measure of task progress has limitations. Some limitations include biases in the underlying model outputs and biases towards higher-quality texts.
LLM-based Evaluators
The outstanding capabilities of LLMs allow them to be used not only for generating text but also for text evaluation. These evaluators offer scalability and interpretability.
Prompt-based Evaluators
LLM-based evaluators request LLMs to judge some text. The judgment can be based on (i) the text itself (no reference), where LLM evaluates qualities such as fluency and coherence; (ii) the generated text, original text, and possibly the topic or question (no reference), where LLM evaluates qualities like consistency and relevance; (iii) the comparison between the generated text and ground truth (reference-based), where LLM evaluates quality and similarity. Some evaluation prompt frameworks include reasoning then scoring (RTS), multiple-choice question scoring (MCQ), face-to-face scoring (H2H), and G-Eval (see the page on evaluating the performance of LLM summarization prompts with G-Eval). GEMBA is an indicator for evaluating translation quality.
LLM evaluation is an emerging research area that has not yet been systematically studied. Researchers have found issues with the reliability of LLM evaluators, such as positional bias, verbosity bias, self-enhancement bias, limited mathematical and reasoning abilities, and challenges with LLMs assigning numerical scores. Strategies proposed to mitigate positional bias include multi-evidence calibration (MEC), balanced positional calibration (BPC), and human-machine interaction calibration (HITLC).
Example of a Prompt-based Evaluator
We can obtain the output generated by the model and prompt the model to determine the quality of the generated completion. Using this evaluation method typically requires the following steps:
1. Generate output predictions from a given test set.
2. Prompt the model to focus on assessing the quality of the output—given reference text and sufficient context (e.g., evaluation criteria).
3. Input the prompt into the model and analyze the results.
With sufficient prompts and context provided, the model should be able to score. While GPT-4 has achieved quite good results with this evaluation method, human verification is still needed for the model’s generated output. In specific domain tasks or when evaluating outputs involving application-specific methods, the model may perform poorly. Therefore, the model’s behavior should be carefully studied based on the nature of the dataset. Remember that executing LLM-based evaluations requires its own prompt engineering. Below is an example prompt template used in the NL2Python application.
You are an AI-based evaluator. Given an input (starts with --INPUT) that consists of a user prompt (denoted by STATEMENT) and the two completions (labelled EXPECTED and GENERATED), please do the following:
1- Parse user prompt (STATEMENT) and EXPECTED output to understand task and expected outcome.
2- Check GENERATED code for syntax errors and key variables/functions.
3- Compare GENERATED code to EXPECTED output for similarities/differences, including the use of appropriate Python functions and syntax.
4- Perform a static analysis of the GENERATED code to check for potential functional issues, such as incorrect data types, uninitialized variables, and improper use of functions.
5- Evaluate the GENERATED code based on other criteria such as readability, efficiency, and adherence to best programming practices.
6- Use the results of steps 2-5 to assign a score to the GENERATED code between 1 to 5, with a higher score indicating better quality. The score can be based on a weighted combination of the different criteria.
7- Come up with an explanation for the score assigned to the GENERATED code. This should also mention if the code is valid or not.
When the above is done, please generate an ANSWER that includes outputs:
--ANSWER
EXPLANATION:
SCORE:
Below are two examples:
# Example 1
--INPUT
STATEMENT = create a cube
EXPECTED = makeCube()
GENERATED = makeCube(n='cube1')
--ANSWER
SCORE: 4
EXPLANATION: Both completions are valid for creating a cubes. However, the GENERATED one differs by including the cube name (n=cube1), which is not necessary.
# Example 2
--INPUT
STATEMENT = make cube1 red
EXPECTED = changeColor(color=(1, 0, 0), objects=["cube1"])
GENERATED = makeItRed(n='cube1')
--ANSWER
SCORE: 0
EXPLANATION: There is no function in the API called makeItRed. Therefore, this is a made-up function.
Now please process the example below
--INPUT
STATEMENT = {prompt}
EXPECTED = {expected_output}
GENERATED = {completion}
--ANSWERThe output of LLM evaluators is typically a score (e.g., 0-1) and an optional explanation, which is something we may not necessarily obtain through traditional metrics.
LLM Embedding-based Metrics
Recently, embedding models from LLMs (e.g., GPT3’s text-embedding-ada-002) have also been used to compute semantic similarity-based metrics.
Metrics for LLM-generated Code
When using LLMs to generate code, the following metrics apply.
Functional Correctness
When LLMs are responsible for generating code for specific tasks in natural language, functional correctness assesses the accuracy of the NL to code generation task. In this case, functional correctness evaluation is used to assess whether the generated code produces the desired output for given inputs.
For example, to use functional correctness evaluation, we can define a set of test cases that cover different inputs and their expected outputs. For instance, we can define the following test cases:
Input: 0
Expected Output: 1
Input: 1
Expected Output: 1
Input: 2
Expected Output: 2
Input: 5
Expected Output: 120
Input: 10
Expected Output: 3628800Then, we can use the code generated by the LLM to calculate the factorial for each input and compare the generated output with the expected output. If the generated output matches the expected output for each input, we conclude that the LLM is functionally correct for that task.
The limitation of functional correctness evaluation is that sometimes the cost of setting up the execution environment for the generated code is too high. Additionally, functional correctness evaluation does not consider the following important factors of the generated code:
-
Readability
-
Maintainability
-
Efficiency
Furthermore, defining a comprehensive set of test cases to cover all possible inputs and edge cases for a given task is quite challenging. This difficulty limits the effectiveness of functional correctness evaluation.
Rule-based Metrics
For specific domain applications and experiments, implementing rule-based metrics can be quite useful. For example, suppose we ask the model to generate multiple completions for a given task. We might be interested in selecting outputs that maximize the probability of certain keywords appearing in the prompt. Additionally, in some cases, the entire prompt might not be useful—only key entities matter. Creating a model that performs entity extraction on the generated output can also be used to evaluate the quality of the predicted output. Considering many possibilities, it is a good practice to consider custom metrics tailored to specific domain tasks. Here, we provide some widely used rule-based evaluation metrics for NL2Code and NL2NL use cases:
Syntax correctness: This metric assesses whether the generated code adheres to the syntax rules of the programming language used. A set of rules for checking common syntax errors can be used to evaluate this metric. Common examples of syntax errors include missing semicolons, incorrect variable names, or incorrect function calls.
Format checking: Another metric that can be used to evaluate the format of the generated code for NL2Code models. This metric assesses whether the generated code follows a consistent and readable format. A set of rules for checking common formatting issues can be employed for evaluation, such as indentation, line breaks, and spacing.
Language checking: The language checking metric evaluates whether the generated text or code is easy to understand and consistent with user input. A set of rules can be used for this check, examining common language issues like incorrect word choice or grammar.
Keyword presence: This metric measures whether the generated text contains keywords or key phrases used in the natural language input. A set of rules can be employed to evaluate this. These rules check for the presence of specific keywords or key phrases relevant to the task being performed.
Automated Test Generation
We can also use LLMs for automated test generation, where LLMs generate a variety of test cases, including different input types, contexts, and difficulty levels:
Generated test cases: The LLM being evaluated is tasked with solving the generated test cases.
Predefined metrics: The LLM-based evaluation system uses predefined metrics (e.g., relevance and fluency) to measure the model’s performance.
Comparison and ranking: The results are compared with baselines or other LLMs, providing insights into the relative strengths and weaknesses of the model.
Metrics for RAG Pattern
Retrieval-Augmented Generation (RAG) pattern is a commonly used method to enhance LLM performance. This pattern involves retrieving relevant information from a knowledge base and then using a generation model to produce the final output. Both retrieval and generation models can be LLMs. The following metrics derived from RAGAS (Retrieval-Augmented Generation Assessment Framework – see below) require the context retrieved for each query and can be used to evaluate the performance of both retrieval and generation models:
Metrics related to generation:
Fidelity: Measures the factual consistency of the generated answer with the given context. Any claims in the answer that cannot be inferred from the context will be penalized. This is accomplished using a two-step paradigm, including creating statements from the generated answer and then validating each statement against the context (inference). It is calculated based on the answer and the retrieved context. The answers are scaled to the range (0,1), where 1 is the best value.
Answer relevance: Refers to the degree to which the answer directly addresses the given question or context. It does not consider the truthfulness of the answer but penalizes any redundant information or incomplete answers present in the question. It is calculated based on the question and answer.
Metrics related to retrieval:
Context relevance: Measures the relevance of the retrieved context to the question. Ideally, the context should only contain the information necessary to answer the question. The presence of redundant information in the context will be penalized. It reflects the quality of the retrieval pipeline. It is calculated based on the question and the retrieved context.
Context recall rate: Measures the recall rate of the retrieved context using annotated answers as ground truth facts. Annotated answers are treated as proxies for the ground truth context. It is calculated based on the ground truth facts and the retrieved context.
Implementation Framework
Azure Machine Learning prompt flow: Provides nine built-in evaluation methods, including classification metrics.

OpenAI Evals: Evals is a framework for evaluating LLMs and LLM systems, as well as a benchmark open registry (github.com).
RAGAS: RAG-specific metrics.
Recruitment Requirements
Complete qualified robot-related video production
Total duration must exceed 3 hours
Video content must be high-quality courses, ensuring professionalism
Instructor Rewards
Enjoy course revenue sharing
Gift 2 courses from Guyu Academy’s premium courses (excluding training camps)
Contact Us
Add staff WeChat: GYH-xiaogu




