Deep Learning Frameworks
Author: Horace He
Revise: louwill
source: https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/
For many practitioners in the deep learning industry, mastering one or more deep learning frameworks is one of the essential skills for daily work. After a period of chaos in the deep learning framework market, a dominant market structure has gradually formed with TensorFlow and PyTorch leading the way.
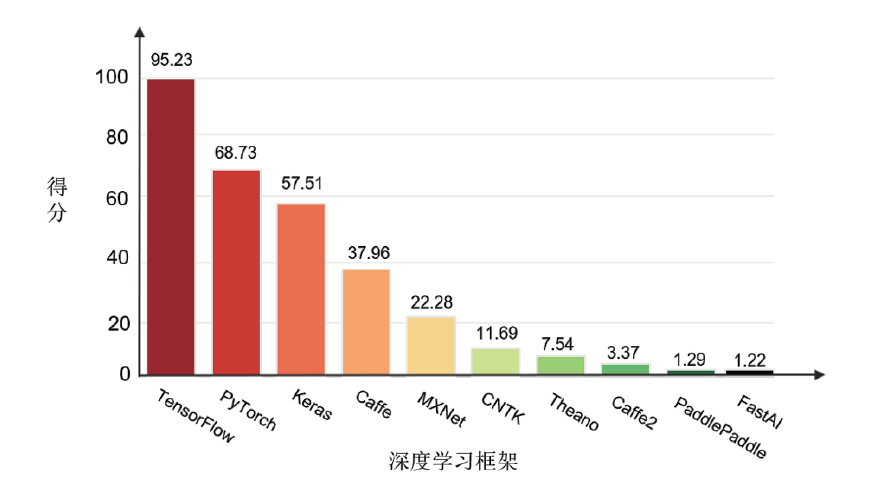
Figure 1 shows a comparison of the comprehensive scores of various deep learning frameworks in 2019. It can be seen that although PyTorch has developed rapidly in the past year, TensorFlow still firmly occupies the top position in the market. With the integration of Keras as the frontend framework in version 2.0, TensorFlow will remain the big brother for a considerable amount of time in the future.
Looking back at the development characteristics of TensorFlow and PyTorch over the past two years, although TensorFlow has lost some market share for various reasons, it is still the undeniable choice in the industry. However, in academic papers and research fields, PyTorch has gradually taken the lead.
In China, a significant feature of the deep learning market in the past two years is the emergence of domestic deep learning frameworks. These include Baidu’s PaddlePaddle, Megvii’s MegEngine, Tsinghua’s Jittor, and Huawei’s MindSpore. In a world where competition among deep learning frameworks is stabilizing, the concentrated emergence of domestic frameworks in the past two years is indeed a gratifying phenomenon.
PyTorch Dominates in Academia
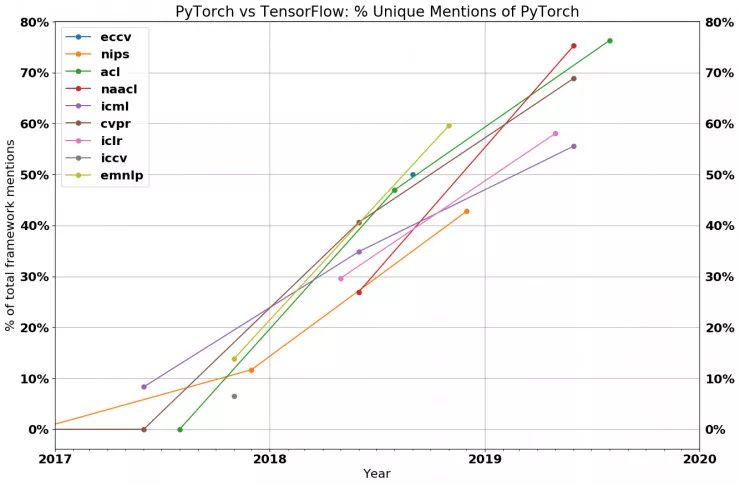
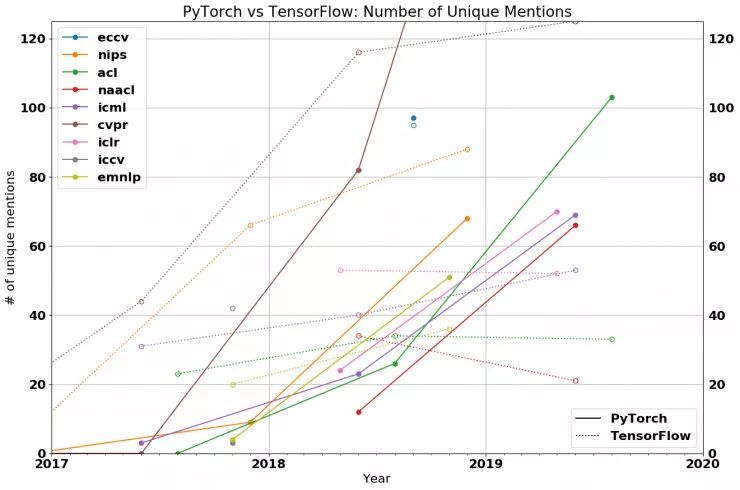
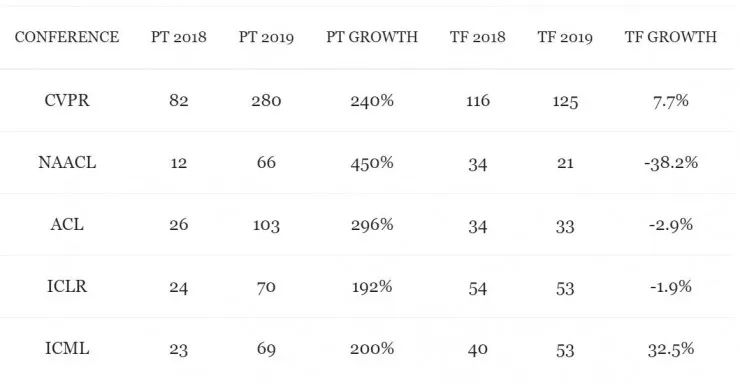
Let’s take a look at the actual data. The following figure shows the number of papers that used only the PyTorch framework in recent top research conferences and the proportion of papers that used either TensorFlow or PyTorch. As shown in the figure, each curve (representing different conferences) is inclined upwards (indicating that the proportion of PyTorch is increasing), and in each major conference in 2019, most papers adopted PyTorch for implementation.
-
-
Details of the data collection process
Source of the chart: https://chillee.github.io/pytorch-vs-tensorflow/
If you need more evidence to illustrate how quickly PyTorch has gained attention in the research community, please look at the original statistics on the usage of PyTorch and TensorFlow below.
In 2018, PyTorch held a small proportion in deep learning frameworks. Now, PyTorch has become overwhelmingly dominant. Statistics show that 69% of CVPR papers, over 75% of NAACL and ACL papers, and over 50% of ICLR and ICML papers chose to use PyTorch. The frequency of PyTorch usage is most evident in vision and language conferences (with ratios of 2:1 and 3:1 over TensorFlow respectively), and PyTorch is also more popular than TensorFlow in general machine learning conferences such as ICLR and ICML.
While some believe that PyTorch is still an emerging framework trying to carve out a market in a TensorFlow-dominated world, the actual data suggests otherwise. Except for ICML, the growth rate of papers using TensorFlow at other academic conferences has not kept pace with the overall growth rate of papers. This year, the number of papers using TensorFlow at NAACL, ICLR, and ACL is actually less than last year. It seems that TensorFlow indeed needs to be more proactive about its future development.
1. Why Do Researchers Prefer PyTorch?
-
Simplicity. PyTorch is very similar to numpy, has a strong Python style, and is easy to integrate with other components in the Python ecosystem. For example, you can simply add a “PDB” breakpoint anywhere in a PyTorch model for debugging. In the TensorFlow framework, debugging requires a running session, making it difficult to debug.
-
User-friendly API. Compared to TensorFlow’s API, most researchers prefer the API provided by PyTorch. This is partly due to better design in PyTorch, and partly because TensorFlow requires multiple API switches (e.g., “layers” -> “slim” -> “estimators” -> “tf.keras”) which limits its usability.
-
Excellent performance. Although PyTorch’s dynamic graph leaves little room for optimization, there have been many reports indicating that PyTorch runs as fast as TensorFlow (https://www.reddit.com/r/MachineLearning/comments/cvcbu6/d_why_is_pytorch_as_fast_as_and_sometimes_faster/), and even faster (https://arxiv.org/abs/1608.07249). It remains unclear whether this statement is true, but at least TensorFlow does not have an absolute advantage in this regard.
2. What Is the Future of TensorFlow in Research?
Even if TensorFlow has similar functionality to PyTorch, PyTorch has already captured most of the users in the research community. This means it is easier to find implementations of algorithms in PyTorch, and authors are more motivated to release code in PyTorch versions (so that people will use it), and your collaborators are likely to prefer PyTorch as well. Therefore, porting code back to the TensorFlow 2.0 platform would be a lengthy process (if it is done at all).
TensorFlow will always have a fixed user base within Google/DeepMind, but I am not sure if Google will eventually open this up. Even now, many researchers that Google wants to recruit have shown a preference for PyTorch to varying degrees. I have also heard complaints that many Google researchers wish to use frameworks other than TensorFlow.
Additionally, PyTorch’s dominance may begin to sever the connection between Google researchers and other research communities. Not only will Google researchers find it more challenging to build on others’ research, but external researchers are also less likely to base their work on code released by Google.
Whether TensorFlow 2.0 can regain some researchers for TensorFlow remains to be seen. Although its dynamic graph mode (TensorFlow 2.0’s dynamic graph mode) is certainly attractive, the Keras API is not.
TensorFlow Remains the Preferred Choice for Industrial Implementation
While PyTorch currently dominates in research, a quick analysis of the industrial landscape reveals that TensorFlow remains the mainstream framework in the industry. For instance, data from 2018 to 2019 shows that there were 1541 new job postings related to TensorFlow on public recruitment websites, while there were 1437 new postings related to PyTorch; there are 3230 new articles about TensorFlow on the well-known tech media “Medium”, while there are only 1200 articles about PyTorch; on GitHub, projects written in TensorFlow have received 13700 stars, while those written in PyTorch have only received 7200 stars.
So, since PyTorch is so popular among researchers, why hasn’t it achieved the same success in the industry? The first obvious answer is inertia. TensorFlow was born several years before PyTorch, and the industry is generally slower to adopt new technologies compared to researchers. Another reason is that TensorFlow is more suitable for production environments than PyTorch. But what does this mean?
To answer this question, we need to understand how the needs of researchers and industry differ.
Researchers care about how quickly they can iterate in their research, which is typically done on relatively small datasets (datasets that can be run on a single machine) using fewer than 8 GPUs. The biggest limiting factor is often not performance considerations, but rather their ability to quickly implement new ideas. In contrast, the industry prioritizes performance. While a 10% speed improvement during runtime may not matter much to researchers, it can save the company millions of dollars.
Another difference is deployment. Researchers will experiment on their own machines or on a server cluster dedicated to running research work. On the other hand, the industry has a series of restrictions/requirements for deployment:
-
Cannot use Python. For some companies’ servers, the computational overhead of running Python is too high.
-
Portability. You cannot embed a Python interpreter in mobile binaries.
-
Serviceability. Various needs must be met, such as updating models without downtime, seamlessly switching between models, and batch processing during inference, etc.
TensorFlow is built specifically around these needs and provides solutions for all these issues: the layout of the computation graph and the execution engine itself do not require Python, and it handles mobile and server-side issues through TensorFlow Lite and TensorFlow Serving respectively.
Previously, PyTorch could not meet the above requirements well, so most companies currently choose to use TensorFlow in production environments. However, with the release of PyTorch version 1.6, support for production environments has become more user-friendly, and it is believed that PyTorch will gradually close the gap with TensorFlow in this regard.
Emerging Domestic Frameworks
Entering 2020, we are pleasantly surprised to find that top domestic technology companies and research institutions have gradually begun to open-source their own deep learning computing frameworks. These include Baidu’s PaddlePaddle, Megvii’s MegEngine, Tsinghua’s Jittor, Huawei’s MindSpore, and OneFlow from a leading tech company.
As the big brother of domestic deep learning frameworks, PaddlePaddle is based on Baidu’s years of deep learning technology research and business application. It is China’s first open-source, technologically advanced, and fully functional industrial-grade deep learning platform, integrating core training and inference frameworks, basic model libraries, end-to-end development kits, and rich tool components. Currently, PaddlePaddle has accumulated 1.94 million developers and serves 84,000 enterprises, generating 233,000 models based on the PaddlePaddle open-source deep learning platform. PaddlePaddle helps developers quickly realize AI ideas and rapidly launch AI businesses, assisting more and more industries in completing AI empowerment and achieving industrial intelligent upgrades.
MegEngine is a core component of Brain++, which, like Baidu’s PaddlePaddle, provides a domestic original deep learning framework for developers and researchers. Brain++ is a comprehensive solution with large-scale algorithm development capabilities. This framework is mainly used internally by Megvii for algorithm development in the field of computer vision, including large-scale image detection, segmentation, recognition tasks, etc., thus possessing unique advantages in the field of computer vision.
import megengine as mge
import megengine.functional as F
import megengine.module as M
import numpy as np
# Classic Module-based network construction interface
class LeNet(M.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = M.Conv2d(1, 6, 5)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2, 2)
# Omitted part of the code...
self.classifer = M.Linear(84, 10)
# Pythonic style computation flow code
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
# Omitted part of the code...
x = self.classifer(x)
return x
China’s artificial intelligence industry is developing rapidly, and there is an urgent need to build its own open-source deep learning ecosystem. Professor Hu Shimin’s research team from Tsinghua University has proposed a brand new deep learning framework—Jittor. Jittor is a deep learning framework that uses meta-operators to express neural network computing units and is entirely based on dynamic compilation (Just-in-Time). Jittor is the first open-source deep learning framework from a research institution in a domestic university.
Convolutional neural networks used in deep learning are composed of a computational network made up of operators. Due to architecture design and constant expansion, current deep learning frameworks have as many as 2000 operators, making the system complex and optimization and migration difficult. Jittor further decomposes operator calculations, forming more fundamental three categories of over 20 meta-operator closures. Currently, commonly used operators in neural networks can be expressed using combinations of meta-operators. Facing the future development trend of deep learning frameworks, Jittor takes advantage of the combination of meta-operators to propose a unified computation graph for optimization and has designed a completely new dynamic compilation architecture from the ground up. This architecture supports various compilers, achieves instant compilation and dynamic execution of all code, ensures separation of implementation and optimization, and greatly enhances the flexibility, scalability, and portability of application development.