
Click on "Xiaobai Studies Vision" above, select to add "Star" or "Top"
Heavy content, delivered first time
1
Basic Configuration
1
Basic Configuration
import torch
import torch.nn as nn
import torchvision
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.get_device_name(0))
Reproducibility
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
CUDA_VISIBLE_DEVICES=0,1 python train.py
torch.cuda.empty_cache()
nvidia-smi --gpu-reset -i [gpu_id]
2
Tensor Processing
2
Tensor Processing
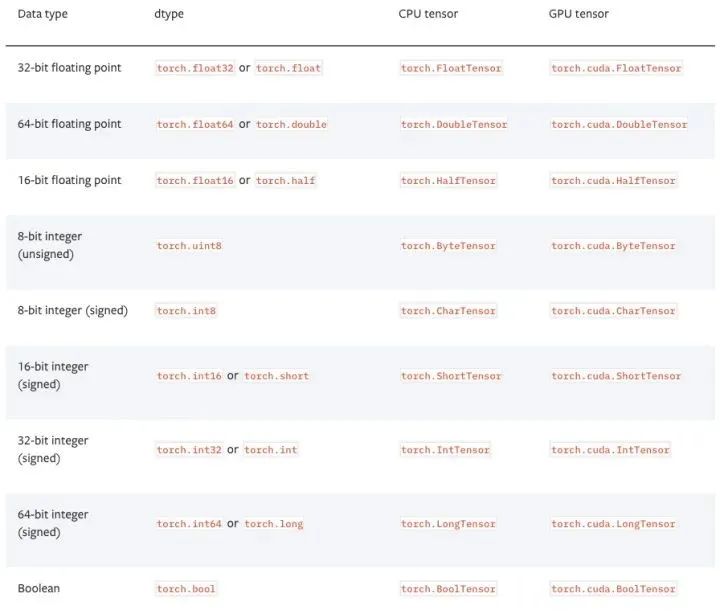
Basic Tensor Information
tensor = torch.randn(3,4,5)
print(tensor.type()) # Data type
print(tensor.size()) # Shape of the tensor, returns a tuple
print(tensor.dim()) # Number of dimensions
Named Tensors
# Before PyTorch 1.3, comments were needed
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)
# After PyTorch 1.3
NCHW = ['N', 'C', 'H', 'W']
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C')
images.select('C', index=0)
# Tensor can also be set this way
tensor = torch.rand(3,4,1,2,names=('C', 'N', 'H', 'W'))
# Using align_to for convenient dimension sorting
tensor = tensor.align_to('N', 'C', 'H', 'W')
# Set default type, FloatTensor is much faster than DoubleTensor in pytorch
torch.set_default_tensor_type(torch.FloatTensor)
# Type conversion
tensor = tensor.cuda()
tensor = tensor.cpu()
tensor = tensor.float()
tensor = tensor.long()
ndarray = tensor.cpu().numpy()
tensor = torch.from_numpy(ndarray).float()
tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride.
# Tensors in pytorch default to [N, C, H, W] order, with data range in [0,1], need to transpose and normalize
# torch.Tensor -> PIL.Image
image = PIL.Image.fromarray(torch.clamp(tensor*255, min=0, max=255).byte().permute(1,2,0).cpu().numpy())
image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way
# PIL.Image -> torch.Tensor
path = r'./figure.jpg'
tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2,0,1).float() / 255
tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently way
image = PIL.Image.fromarray(ndarray.astype(np.uint8))
ndarray = np.asarray(PIL.Image.open(path))
value = torch.rand(1).item()
# Reshaping is often required when inputting tensors from convolutional layers to fully connected layers,
# Compared to torch.view, torch.reshape can automatically handle cases where the input tensor is not contiguous.
tensor = torch.rand(2,3,4)
shape = (6, 4)
tensor = torch.reshape(tensor, shape)
tensor = tensor[torch.randperm(tensor.size(0))] # Shuffle the first dimension
# Pytorch does not support negative stride operations like tensor[::-1], horizontal flipping can be achieved through tensor indexing
# Assuming tensor dimensions are [N, D, H, W].
tensor = tensor[:,:,:,torch.arange(tensor.size(3) - 1, -1, -1).long()]
Copying Tensors
# Operation | New/Shared memory | Still in computation graph |
tensor.clone() # | New | Yes |
tensor.detach() # | Shared | No |
tensor.detach().clone() # | New | No |
Tensor Concatenation
'''Note the difference between torch.cat and torch.stack: torch.cat concatenates along the given dimension, while torch.stack adds a new dimension. For example, when the parameters are 3 tensors of size 10x5, torch.cat results in a tensor of size 30x5, while torch.stack results in a tensor of size 3x10x5.'''
tensor = torch.cat(list_of_tensors, dim=0)
tensor = torch.stack(list_of_tensors, dim=0)
Converting Integer Labels to One-Hot Encoding
# PyTorch labels default from 0
tensor = torch.tensor([0, 2, 1, 3])
N = tensor.size(0)
num_classes = 4
one_hot = torch.zeros(N, num_classes).long()
one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())
Getting Non-Zero Elements
torch.nonzero(tensor) # index of non-zero elements
torch.nonzero(tensor==0) # index of zero elements
torch.nonzero(tensor).size(0) # number of non-zero elements
torch.nonzero(tensor == 0).size(0) # number of zero elements
Checking If Two Tensors Are Equal
torch.allclose(tensor1, tensor2) # float tensor
torch.equal(tensor1, tensor2) # int tensor
Expanding Tensors
# Expand tensor of shape 64*512 to shape 64*512*7*7.
tensor = torch.rand(64,512)
tensor = torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)
Matrix Multiplication
# Matrix multiplication: (m*n) * (n*p) -> (m*p).
result = torch.mm(tensor1, tensor2)
# Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p)
result = torch.bmm(tensor1, tensor2)
# Element-wise multiplication.
result = tensor1 * tensor2
Calculating Pairwise Euclidean Distances Between Two Sets of Data
dist = torch.sqrt(torch.sum((X1[:,None,:] - X2) ** 2, dim=2))
3
Model Definition and Operations
3
Model Definition and Operations
Example of a Simple Two-Layer Convolutional Network
# convolutional neural network (2 convolutional layers)
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model = ConvNet(num_classes).to(device)
Bilinear Pooling
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization
Multi-GPU Synchronized BN (Batch Normalization)
sync_bn = torch.nn.SyncBatchNorm(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
def convertBNtoSyncBN(module, process_group=None):
'''Recursively replace all BN layers with SyncBN layers.
Args:
module[torch.nn.Module]. Network
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
sync_bn = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum,
module.affine, module.track_running_stats, process_group)
sync_bn.running_mean = module.running_mean
sync_bn.running_var = module.running_var
if module.affine:
sync_bn.weight = module.weight.clone().detach()
sync_bn.bias = module.bias.clone().detach()
return sync_bn
else:
for name, child_module in module.named_children():
setattr(module, name, convert_syncbn_model(child_module, process_group=process_group))
return module
class BN(torch.nn.Module)
def __init__(self):
...
self.register_buffer('running_mean', torch.zeros(num_features))
def forward(self, X):
...
self.running_mean += momentum * (current - self.running_mean)
num_parameters = sum(torch.numel(parameter) for parameter in model.parameters())
params = list(model.named_parameters())
(name, param) = params[28]
print(name)
print(param.grad)
print('-------------------------------------------------')
(name2, param2) = params[29]
print(name2)
print(param2.grad)
print('----------------------------------------------------')
(name1, param1) = params[30]
print(name1)
print(param1.grad)
Similar to Keras’s model.summary() Output Model Information, Use pytorch-summary
# Common practice for initialization.
for layer in model.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out',
nonlinearity='relu')
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.BatchNorm2d):
torch.nn.init.constant_(layer.weight, val=1.0)
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.Linear):
torch.nn.init.xavier_normal_(layer.weight)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
# Initialization with given tensor.
layer.weight = torch.nn.Parameter(tensor)
# Extract the first two layers
new_model = nn.Sequential(*list(model.children())[:2])
# If you want to extract all convolutional layers from the model, you can operate like this:
for layer in model.named_modules():
if isinstance(layer[1], nn.Conv2d):
conv_model.add_module(layer[0], layer[1])
model.load_state_dict(torch.load('model.pth'), strict=False)
model.load_state_dict(torch.load('model.pth', map_location='cpu'))
# model_new represents the new model
# model_saved represents another model, such as a saved model imported using torch.load
model_new_dict = model_new.state_dict()
model_common_dict = {k:v for k, v in model_saved.items() if k in model_new_dict.keys()}
model_new_dict.update(model_common_dict)
model_new.load_state_dict(model_new_dict)
4
Data Processing
4
Data Processing
import os
import cv2
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
def compute_mean_and_std(dataset): # Input PyTorch dataset, output mean and standard deviation
mean_r = 0
mean_g = 0
mean_b = 0
for img, _ in dataset:
img = np.asarray(img) # change PIL Image to numpy array
mean_b += np.mean(img[:, :, 0])
mean_g += np.mean(img[:, :, 1])
mean_r += np.mean(img[:, :, 2])
mean_b /= len(dataset)
mean_g /= len(dataset)
mean_r /= len(dataset)
diff_r = 0
diff_g = 0
diff_b = 0
N = 0
for img, _ in dataset:
img = np.asarray(img)
diff_b += np.sum(np.power(img[:, :, 0] - mean_b, 2))
diff_g += np.sum(np.power(img[:, :, 1] - mean_g, 2))
diff_r += np.sum(np.power(img[:, :, 2] - mean_r, 2))
N += np.prod(img[:, :, 0].shape)
std_b = np.sqrt(diff_b / N)
std_g = np.sqrt(diff_g / N)
std_r = np.sqrt(diff_r / N)
mean = (mean_b.item() / 255.0, mean_g.item() / 255.0, mean_r.item() / 255.0)
std = (std_b.item() / 255.0, std_g.item() / 255.0, std_r.item() / 255.0)
return mean, std
import cv2
video = cv2.VideoCapture(mp4_path)
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(video.get(cv2.CAP_PROP_FPS))
video.release()
K = self._num_segments
if is_train:
if num_frames > K:
# Random index for each segment.
frame_indices = torch.randint(
high=num_frames // K, size=(K,), dtype=torch.long)
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.randint(
high=num_frames, size=(K - num_frames,), dtype=torch.long)
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), frame_indices)))[0]
else:
if num_frames > K:
# Middle index for each segment.
frame_indices = num_frames / K // 2
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), torch.arange(K - num_frames))))[0]
assert frame_indices.size() == (K,)
return [frame_indices[i] for i in range(K)]
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
5
Model Training and Testing
5
Model Training and Testing
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i ,(images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch: [{}/{}], Step: [{}/{}], Loss: {}' .format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model
model.eval() # eval mode(batch norm uses moving mean/variance #instead of mini-batch mean/variance)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test accuracy of the model on the 10000 test images: {} %' .format(100 * correct / total))
class MyLoss(torch.nn.Module):
def __init__(self):
super(MyLoss, self).__init__()
def forward(self, x, y):
loss = torch.mean((x - y) ** 2)
return loss
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
""" Convert labels to one hot vectors
Args: labels: torch tensor in format [label1, label2, label3, ...] classes: int, number of classes value: label value in one hot vector, default to 1
Returns: return one hot format labels in shape [batchsize, classes] """
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth them.
Args: target: target in form with [label1, label2, label_batchsize] length: length of one-hot format(number of classes) smooth_factor: smooth factor for label smooth
Returns: smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1 - smooth_factor)
one_hot += smooth_factor / (length - 1)
return one_hot.to(target.device)
def forward(self, x, target):
if x.size(0) != target.size(0):
raise ValueError('Expected input batchsize ({}) to match target batch_size({})' .format(x.size(0), target.size(0)))
if x.dim() < 2:
raise ValueError('Expected input tensor to have least 2 dimensions(got {})' .format(x.size(0)))
if x.dim() != 2:
raise ValueError('Only 2 dimension tensor are implemented, (got {})' .format(x.size()))
smoothed_target = self._smooth_label(target, x.size(1), self.e)
x = self.log_softmax(x)
loss = torch.sum(- x * smoothed_target, dim=1)
if self.reduction == 'none':
return loss
elif self.reduction == 'sum':
return torch.sum(loss)
elif self.reduction == 'mean':
return torch.mean(loss)
else:
raise ValueError('unrecognized option, expect reduction to be one of none, mean, sum')
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
score = model(images)
log_prob = torch.nn.functional.log_softmax(score, dim=1)
loss = -torch.sum(log_prob * smoothed_labels) / N
optimizer.zero_grad()
loss.backward()
optimizer.step()
beta_distribution = torch.distributions.beta.Beta(alpha, alpha)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
# Mixup images and labels.
lambda_ = beta_distribution.sample([]).item()
index = torch.randperm(images.size(0)).cuda()
mixed_images = lambda_ * images + (1 - lambda_) * images[index, :]
label_a, label_b = labels, labels[index]
# Mixup loss.
scores = model(mixed_images)
loss = (lambda_ * loss_function(scores, label_a) + (1 - lambda_) * loss_function(scores, label_b))
optimizer.zero_grad()
loss.backward()
optimizer.step()
l1_regularization = torch.nn.L1Loss(reduction='sum')
loss = ... # Standard cross-entropy loss
for param in model.parameters():
loss += torch.sum(torch.abs(param))
loss.backward()
bias_list = (param for name, param in model.named_parameters() if name[-4:] == 'bias')
others_list = (param for name, param in model.named_parameters() if name[-4:] != 'bias')
parameters = [{'parameters': bias_list, 'weight_decay': 0}, {'parameters': others_list}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=20)
# If there is one global learning rate (which is the common case).
lr = next(iter(optimizer.param_groups))['lr']
# If there are multiple learning rates for different layers.
all_lr = []
for param_group in optimizer.param_groups:
all_lr.append(param_group['lr'])
Learning Rate Decay
# Reduce learning rate when validation accuracy plateaus.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)
for t in range(0, 80):
train(...)
val(...)
scheduler.step(val_acc)
# Cosine annealing learning rate.
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)
# Reduce learning rate by 10 at given epochs.
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)
for t in range(0, 80):
scheduler.step() train(...)
val(...)
# Learning rate warmup by 10 epochs.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)
for t in range(0, 10):
scheduler.step() train(...)
val(...)
Optimizer Chaining Updates
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR, StepLR
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = StepLR(optimizer, step_size=3, gamma=0.1)
for epoch in range(4):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()
pip install tensorboard
tensorboard --logdir=runs
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
# VGG-16 relu5-3 feature.
model = torchvision.models.vgg16(pretrained=True).features[:-1]
# VGG-16 pool5 feature.
model = torchvision.models.vgg16(pretrained=True).features
# VGG-16 fc7 feature.
model = torchvision.models.vgg16(pretrained=True)
model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])
# ResNet GAP feature.
model = torchvision.models.resnet18(pretrained=True)
model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
with torch.no_grad():
model.eval()
conv_representation = model(image)
class FeatureExtractor(torch.nn.Module):
"""Helper class to extract several convolution features from the given pre-trained model.
Attributes: _model, torch.nn.Module. _layers_to_extract, list<str> or set<str>
Example: >>> model = torchvision.models.resnet152(pretrained=True) >>> model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1])) >>> conv_representation = FeatureExtractor(
pretrained_model=model,
layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image) """
def __init__(self, pretrained_model, layers_to_extract):
torch.nn.Module.__init__(self)
self._model = pretrained_model
self._model.eval()
self._layers_to_extract = set(layers_to_extract)
def forward(self, x):
with torch.no_grad():
conv_representation = []
for name, layer in self._model.named_children():
x = layer(x)
if name in self._layers_to_extract:
conv_representation.append(x)
return conv_representation
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, 100) # Replace the last fc layer
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)
model = torchvision.models.resnet18(pretrained=True)
finetuned_parameters = list(map(id, model.fc.parameters()))
conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)
parameters = [{'params': conv_parameters, 'lr': 1e-3}, {'params': model.fc.parameters()}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
6
Other Considerations
6
Other Considerations
x = torch.nn.functional.relu(x, inplace=True)
with torch.autograd.profiler.profile(enabled=True, use_cuda=False) as profile:
...
print(profile)
# Or run in command line
python -m torch.utils.bottleneck main.py
# pip install torchsnooper
import torchsnooper
# For functions, use the decorator @torchsnooper.snoop()
# If not a function, use the with statement to activate TorchSnooper, putting the training loop within the with statement.
with torchsnooper.snoop():
Original code
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Xiaobai Studies Vision" public account to download the first OpenCV extension module tutorial in the network, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the background of the "Xiaobai Studies Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Xiaobai Studies Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, it will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~