
Follow our public account to discover the beauty of CV technology
This article is reprinted from Machine Heart.
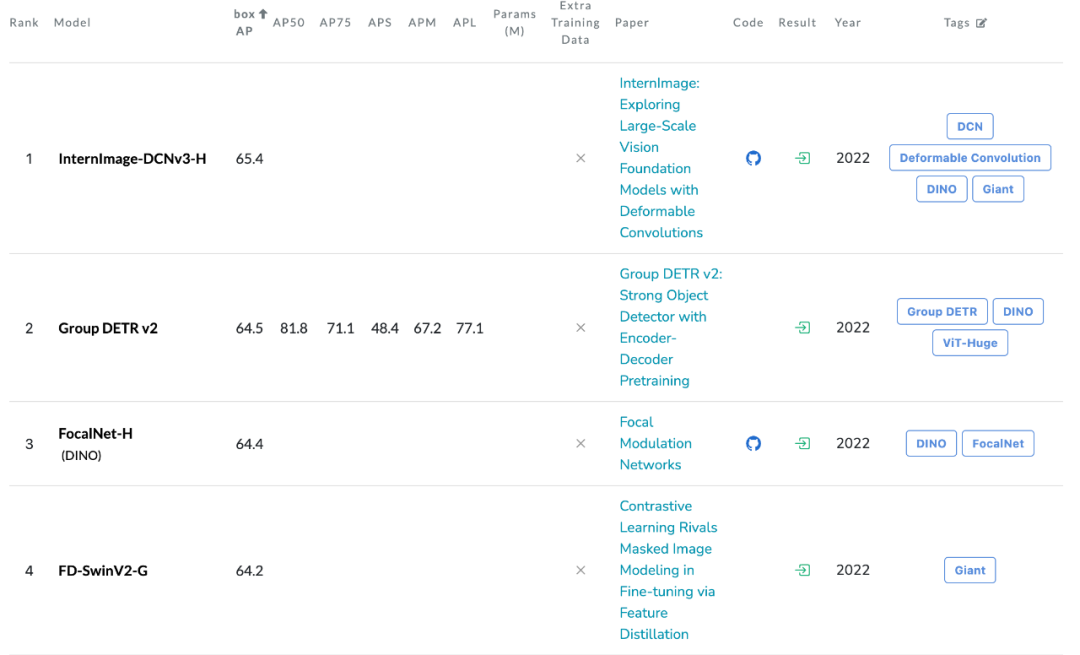
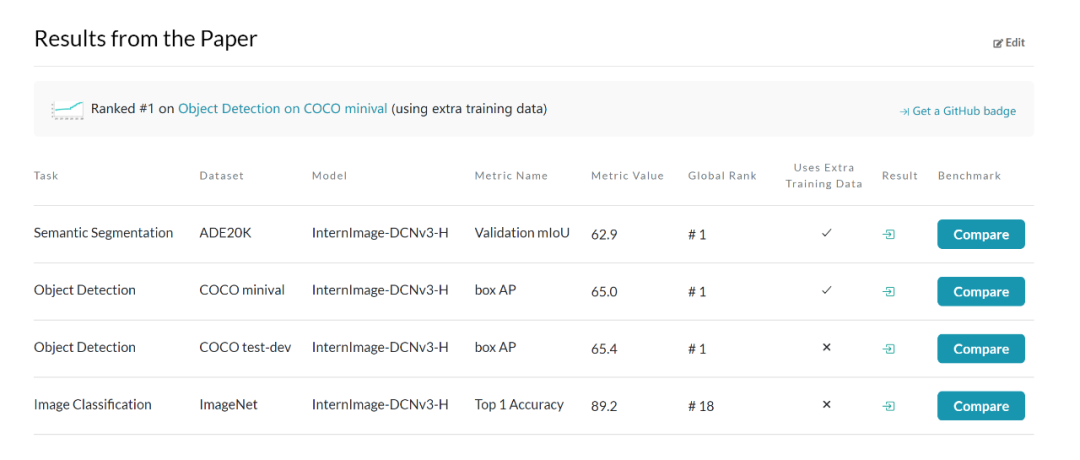
Researchers from Pujiang Laboratory, Tsinghua University, and other institutions proposed a new convolution-based foundational model called InternImage. Unlike transformer-based networks, InternImage uses deformable convolution as the core operator, enabling the model to have a dynamically effective receptive field required for downstream tasks such as detection and segmentation, and to perform adaptive spatial aggregation conditioned on input information and tasks. InternImage-H achieved 65.4 mAP on COCO object detection and 62.9 on ADE20K, setting new records for detection and segmentation.
To address the above technical issues, researchers from Pujiang Laboratory, Tsinghua University, and other institutions innovatively proposed a large-scale model based on convolutional neural networks, called InternImage, which uses sparse dynamic convolution as the core operator to achieve adaptive spatial aggregation conditioned on input-related information.
InternImage learns more powerful and robust large-scale parameter patterns from massive data by reducing the strict inductive bias of traditional CNNs. Its effectiveness has been validated across visual tasks including image classification, object detection, and semantic segmentation. It has achieved competitive results on challenging benchmark datasets, including ImageNet, COCO, and ADE20K, surpassing visual transformer structures at the same parameter level, providing a new direction for large image models.

-
Paper link: https://arxiv.org/abs/2211.05778 -
Open source code: https://github.com/OpenGVLab/InternImage
Limitations of Traditional Convolutional Neural Networks
Expanding the scale of models is an important strategy for improving feature representation quality. In the field of computer vision, increasing model parameters can effectively enhance the representation learning capability of deep models and enable learning and knowledge acquisition from massive data.
ViT and Swin Transformer first expanded deep models to 2 billion and 3 billion parameter levels, respectively, achieving classification accuracies exceeding 90% on the ImageNet dataset, far surpassing traditional CNN networks and smaller models, breaking through technical bottlenecks. However, traditional CNN models lack the long-range dependence and spatial relationship modeling capabilities necessary to achieve model scale expansion capabilities similar to those of transformer structures. Researchers summarized the differences between traditional convolutional neural networks and visual transformers:
(1) From the operator level, the multi-head attention mechanism of visual transformers possesses long-range dependencies and adaptive spatial aggregation capabilities. Benefiting from this, visual transformers can learn more powerful and robust representations from massive data than CNN networks.
(2) From the model architecture level, in addition to the multi-head attention mechanism, visual transformers have more advanced modules that CNN networks do not possess, such as Layer Normalization (LN), Feedforward Neural Networks (FFN), GELU, etc.
Although some recent works have attempted to use large-kernel convolutions to capture long-range dependencies, they still fall short in model scale and accuracy compared to state-of-the-art visual transformers.
Further Expansion of Deformable Convolution Networks
InternImage enhances the scalability of convolutional models and mitigates inductive bias by redesigning operators and model structures, including (1) DCNv3 operator, which introduces shared projection weights, multi-group mechanisms, and sampling point modulation based on the DCNv2 operator. (2) Foundational modules, integrating advanced modules as the basic unit of model construction (3) Module stacking rules, standardizing model hyperparameters such as width, depth, and group number during model expansion.
This work aims to construct a CNN model that can effectively scale to large parameter sizes. First, the redesigned deformable convolution operator DCNv2 adapts to long-range dependencies and weakens inductive bias; then, the adjusted convolution operator is combined with advanced components to establish foundational unit modules; finally, stacking and scaling rules for modules are explored and implemented to build a foundational model with large-scale parameters that can learn powerful representations from massive data.
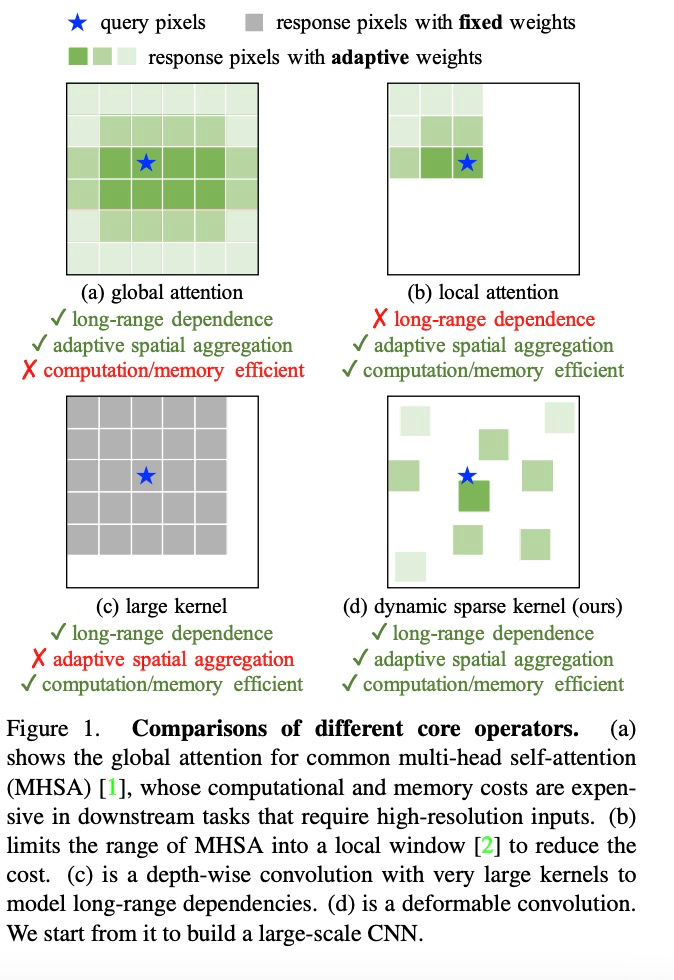
At the operator level, this research first summarizes the main differences between convolution operators and other mainstream operators. Current mainstream transformer series models mainly rely on the multi-head self-attention mechanism to achieve large model construction, which has long-range dependencies sufficient to establish connections between distant features and possesses spatial adaptive aggregation capabilities for pixel-level relationships. However, this global attention mechanism demands significant computational and storage resources, making efficient training and rapid convergence difficult. Similarly, local attention mechanisms lack long-range feature dependencies. Large-kernel dense convolutions, due to the absence of spatial aggregation capabilities, struggle to overcome the inherent inductive bias of convolutions, making it challenging to scale models. Therefore, InternImage achieves global attention effects while minimizing computational and storage waste by designing dynamic sparse convolution operators for efficient training.
Based on the DCNv2 operator, researchers redesigned and proposed the DCNv3 operator, with specific improvements including the following parts.
(1) Shared projection weights. Similar to conventional convolutions, different sampling points in DCNv2 have independent projection weights, resulting in a linear relationship between parameter size and the total number of sampling points. To reduce parameter and memory complexity, inspired by separable convolutions, position-independent weights replace grouped weights, sharing projection weights across different sampling points while retaining all sampling location dependencies.
(2) Introduction of multi-group mechanisms. The multi-group design was first introduced in grouped convolutions and is widely used in the multi-head self-attention of transformers, effectively enhancing feature diversity when combined with adaptive spatial aggregation. Inspired by this, researchers divided the spatial aggregation process into several groups, each with independent sampling offsets. Consequently, different groups within a single DCNv3 layer exhibit distinct spatial aggregation patterns, generating rich feature diversity.
(3) Sampling point modulation scalar normalization. To alleviate instability during model capacity expansion, researchers set the normalization mode to softmax normalization per sampling point, making the training process of large-scale models more stable and establishing connections among all sampling points.
After constructing the DCNv3 operator, the next step is to standardize the overall details of the foundational modules and other layers, and then explore stacking strategies for these foundational modules to build InternImage. Finally, based on the proposed model scaling rules, models with different parameter sizes are constructed.
Foundational Modules. Unlike the bottleneck structures widely used in traditional CNNs, this study adopts foundational modules closer to ViTs, equipped with more advanced components, including GELU, Layer Normalization (LN), and Feedforward Networks (FFN), which have proven to be more efficient in various visual tasks. The details of the foundational modules are shown in the above image, where the core operator is DCNv3, predicting sampling biases and modulation scales through a lightweight separable convolution. For other components, the design follows the same principles as conventional transformers.
Stacking Rules. To clarify the block stacking process, this study proposes two module stacking rules, where the first rule states that the number of channels in the last three stages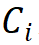 is determined by the number of channels in the first stage
is determined by the number of channels in the first stage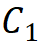 ; the second rule corresponds the module group numbers to the number of channels in each stage, that is
; the second rule corresponds the module group numbers to the number of channels in each stage, that is ; third, the stacking pattern is fixed as “AABA”, meaning the module stacking numbers of the 1st, 2nd, and 4th stages are the same
; third, the stacking pattern is fixed as “AABA”, meaning the module stacking numbers of the 1st, 2nd, and 4th stages are the same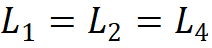 and not greater than that of the 3rd stage
and not greater than that of the 3rd stage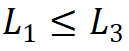 . Thus, a model with around 30M parameters was chosen as the basis, with specific parameters being:Steam output channel number
. Thus, a model with around 30M parameters was chosen as the basis, with specific parameters being:Steam output channel number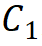 being 64; the number of groups is 1/16 of the input channel number for each stage, with the number of module stackings for the 1st, 2nd, and 4th stages
being 64; the number of groups is 1/16 of the input channel number for each stage, with the number of module stackings for the 1st, 2nd, and 4th stages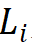 being 4, and the number of module stackings for the 3rd stage
being 4, and the number of module stackings for the 3rd stage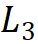 being 18, resulting in a model with 30M parameters.
being 18, resulting in a model with 30M parameters.
Model Scaling Rules. Based on the optimal model under the above constraints, this study standardized two scaling dimensions of the network model: depth D (number of module stackings) and width C (number of channels), using limiting factors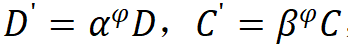 and
and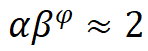 along the composite coefficient
along the composite coefficient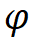 to scale depth and width, that is,
to scale depth and width, that is,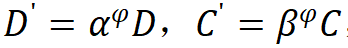 , where
, where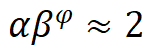 , according to experiments, the optimal settings are
, according to experiments, the optimal settings are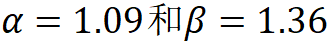 .
.
Following this rule, this study constructed models of different scales, namely InternImage-T, S, B, L, XL. The specific parameters are:

Experimental Results
Image Classification Experiments: By using a public dataset of 427M: Laion-400M, YFCC15M, CC12M, InternImage-H achieved an accuracy of 89.2% on ImageNet-1K.
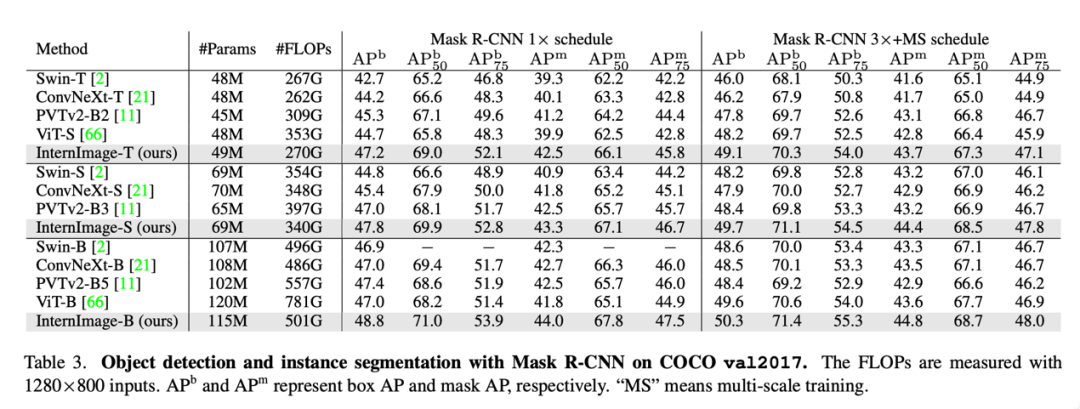
Object Detection: Using the largest scale InternImage-H as the backbone network and DINO as the base detection framework, the DINO detector was pre-trained on the Objects365 dataset and then fine-tuned on COCO. This model achieved an optimal result of 65.4% in object detection tasks, breaking the performance boundaries of COCO object detection.
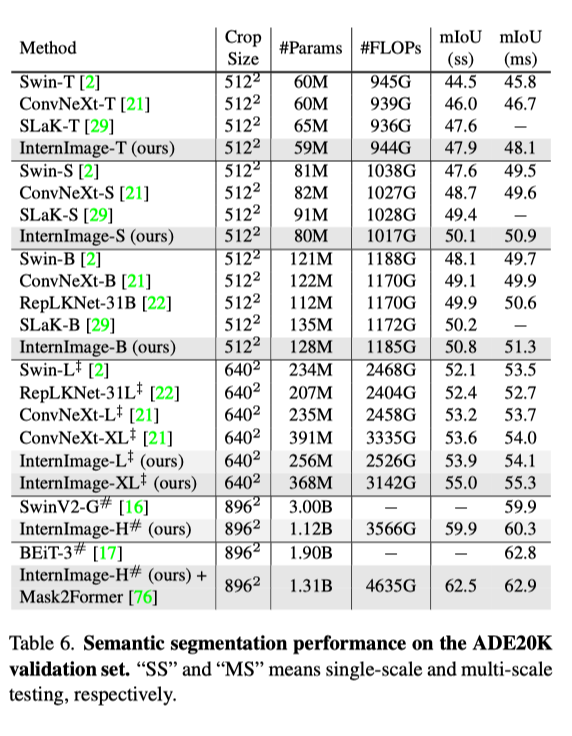
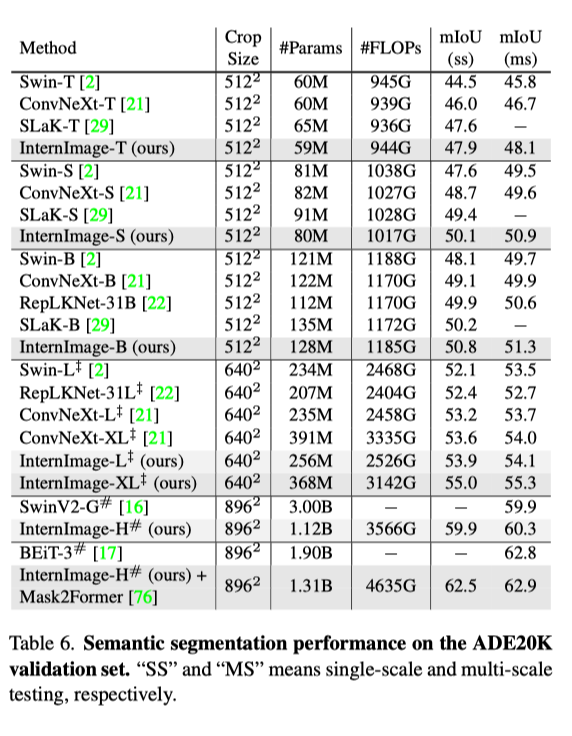
Semantic Segmentation: In semantic segmentation, InternImage-H also achieved excellent performance, achieving the current highest score of 62.9% on ADE20K when combined with Mask2Former.
Conclusion
This study proposed InternImage, a new large-scale foundational model based on CNNs that can provide powerful representations for multi-functional visual tasks such as image classification, object detection, and semantic segmentation. Researchers adjusted the flexible DCNv2 operator to meet the needs of foundational models, and developed a series of block, stacking, and scaling rules centered around the core operator. Extensive experiments on object detection and semantic segmentation benchmarks validated that InternImage can achieve performance comparable to or better than large-scale visual transformers trained on massive data and meticulously designed, indicating that CNNs are also a significant option for research on large-scale visual foundational models. Nevertheless, large-scale CNNs are still in the early stages of development, and researchers hope that InternImage can serve as a good starting point.

END
Welcome to join the “Object Detection” group chat👇 Please note:OD
