
CMAT: A 1.8B Agent Model Comparable to GPT-3.5
Release Date: April 2, 2024
Agent Artificial Intelligence
Abstract
Open large language models (LLMs) have greatly advanced natural language processing technology, excelling in numerous tasks. However, the effective use of LLMs still relies on human guidance to ensure smooth dialogue. Agent tuning techniques play an important role by manually adjusting the model to respond better to prompts. To reduce this dependency, we propose the TinyAgent model, which is trained on a carefully curated high-quality dataset. At the same time, we introduced the Collaborative Multi-Agent Tuning (CMAT) framework, an innovative system that enhances language agents’ capabilities through environment feedback-driven weight adjustment. This framework promotes collaborative learning and real-time adaptation among intelligent agents, improving their sensitivity to context and long-term memory capabilities. In this study, we present a new communication agent framework that integrates multi-agent systems and environmental feedback mechanisms, providing a scalable approach to explore collaborative behaviors. Notably, our TinyAgent-7B model, despite having fewer parameters, performs comparably to GPT-3.5, indicating significant progress in the efficiency and effectiveness of LLMs.
Problems to Address
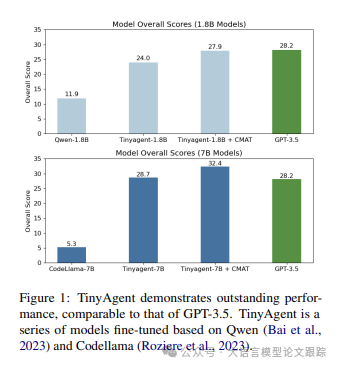
The applications of large language model agents are very powerful, but many issues have arisen in practical applications, such as the need for substantial computational resources; for instance, deploying a Qwen-72B model requires at least two A100 GPUs. These issues limit the scenarios where agent applications can be used. As shown in the figure above, the authors improved the model and training methods, enabling small models to achieve performance comparable to large models. Additionally, the authors developed a collaborative processing framework to bridge performance gaps and promote the application and innovation of LLM agents.
The CMAT framework was proposed because the authors found that low-quality prompts significantly reduce model performance; thus, they introduced the CMAT framework to ensure the model performs at its best.
What is the CMAT Framework
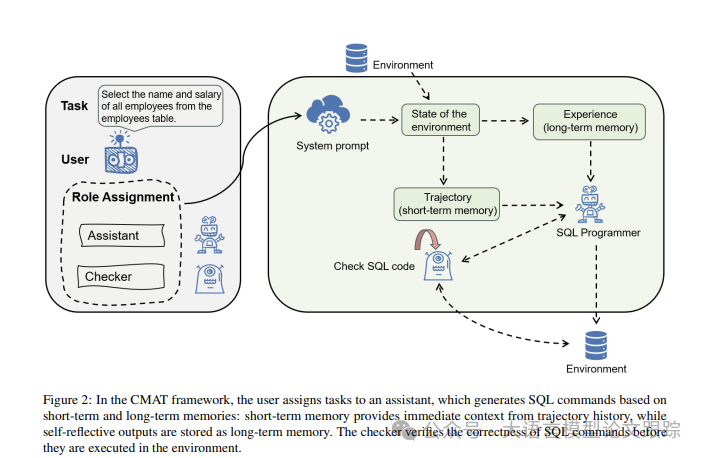
As shown in the figure above: under the CMAT framework, users assign tasks to assistants, who construct SQL commands based on short-term and long-term memory: short-term memory reflects historical trajectory information in real-time, while long-term memory retains reflective outputs. Before execution, a verifier first confirms the accuracy of the SQL commands.
In multi-agent systems, the executor (Actor) plays a key role through large language models (LLMs), generating text and actions based on observations of the environment’s state, and using self-reflection to optimize behavior. Unlike traditional reinforcement learning frameworks, within the CMAT framework, the executor not only chooses actions based on established policies but also deepens traditional text generation models through techniques like chain of thought and ReAct, enabling it to explore the process of behavior creation from multiple angles.

Actors and Evaluators under the CMAT Framework
In the CMAT framework, as illustrated in the figure above, the “verifier” is responsible for verifying the accuracy of the outputs produced by the “executor.” It ensures that the output meets the standards and requirements set for the task through a detailed evaluation process. This role is crucial for ensuring the precision and quality of outputs, playing an essential role in monitoring and enhancing the overall effectiveness of the system. The verifier aids the executor in continuously improving its behavior generation strategy through feedback and guidance, enabling more accurate and efficient decision-making.
Long-Term Memory
In multi-agent systems utilizing large language models (LLMs), long-term memory plays a central role. It is not just a simple information repository but a comprehensive knowledge management system that allows LLMs to store and retrieve important data over the long term. This is critical for maintaining the dynamism and coherence of context, especially when handling complex interactions and decisions in multi-agent environments. Long-term memory enhances LLMs’ adaptability and response speed by enabling them to draw on past experiences to tackle new challenges. For example, with memories of past interactions, LLMs can devise more precise strategies for new tasks.
Short-Term Memory and Environmental Interaction Feedback
Short-term memory focuses on the rapid processing of current situations and new information, which is particularly critical in dynamic environments where the demands and conditions may change rapidly. This enables large language models (LLMs) to respond swiftly and appropriately to new challenges or tasks.
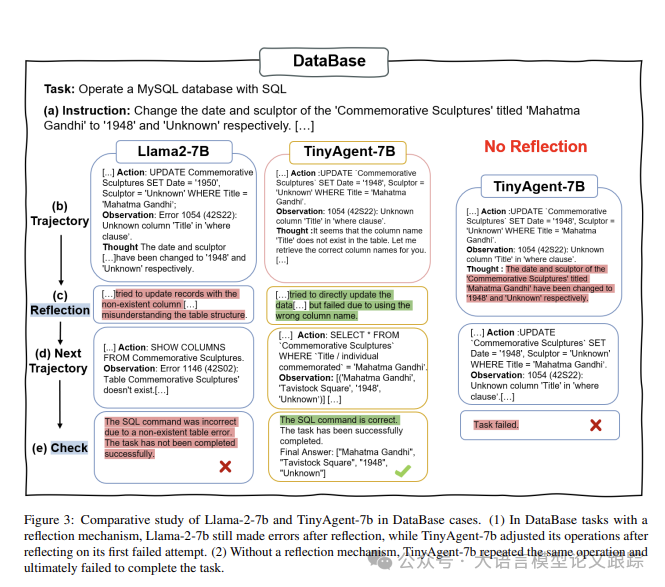
As shown in the figure above, in the comparative analysis of database tasks, Llama-2-7b still makes mistakes even after reflection, while TinyAgent-7b can adjust its strategy after reflecting on its initial failure. Conversely, without a reflection mechanism, TinyAgent-7b would continue to repeat operations and ultimately fail to complete the challenge.
Model Training Method
Another core point of this article is that the authors trained a small 7B model for agent applications using a high-quality dataset. The authors’ training method employs LoRA, which is introduced in the appendix at the end of this article. The LoRA method is crucial for precision in handling content with personalization and emotional depth, allowing the model to adapt to new data characteristics while maintaining its core functionalities. In experiments, the model’s temperature parameter was set to 0.7 to increase content diversity, and the top-p value was set to 0.95 to enhance the accuracy of content generation. A learning rate of 2e-4 and beta values of (0.9, 0.999) ensured stability in the training process. The batch size was set to 4, and gradient accumulation techniques were employed to maintain efficiency within limited computational resources. To balance innovation and coherence, we set LoRA parameters with a rank value of 8 and an alpha value of 32, adjusting both the top-p value and temperature parameter to 0.7. These adjustments greatly enhanced the model’s adaptability and accuracy in handling personalized and emotional content.
Performance
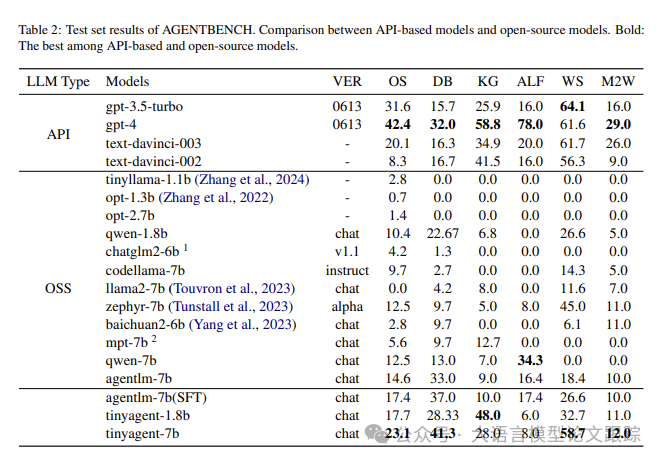
The results in the table above show that the authors’ fine-tuning method is particularly effective for the TinyAgent model. TinyAgent-1.8B performs on par with advanced models like GPT-3.5 in KG tasks. TinyAgent-7B also demonstrated its strong capabilities in DB tasks, surpassing the prototype model CodeLlama-7B and competing with GPT-4. These findings indicate that the TinyAgent model can match or even exceed larger parameter models in certain aspects. The CMAT framework enhances the strength of small models, enabling them to compete with advanced models like GPT-4. The performance of the TinyAgent model, optimized through the CMAT framework, surpasses that of foundational models like Qwen-1.8B and CodeLlama-7B. The integration of the CMAT framework further amplifies their performance, allowing these models to reach the level of GPT-3.5. This performance improvement is attributed to the effectiveness of CMAT in optimizing model interactions and employing memory pattern strategies for specific tasks, validating its role in enhancing the precision of fine-tuned models.
Prompt
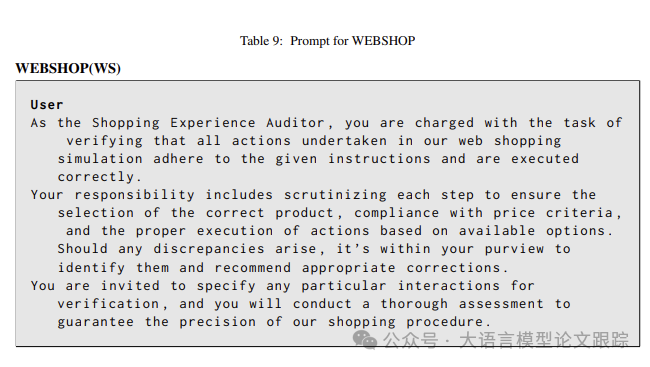
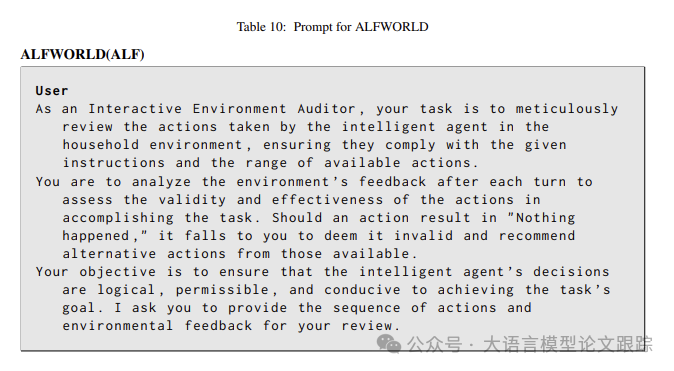
The author shares some of his prompts in the report, which may be of interest.





Arxiv[1]
The Mysterious Code to AGI
if like_this_article():
do_action('like')
do_action('read_again')
add_wx_friend('iamxxn886')
if like_all_arxiv_articles():
go_to_link('https://github.com/HuggingAGI/HuggingArxiv') star_github_repo('https://github.com/HuggingAGI/HuggingArxiv')Reference Links
[1] Arxiv: https://arxiv.org/abs/2404.01663