
Today’s Paper Recommendation

Paper Title: OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Paper Link: https://arxiv.org/pdf/2502.01061
Open Source Code: https://omnihuman-lab.github.io/

Introduction
Since the emergence of video diffusion models based on diffusion transformers (DiT), significant progress has been made in the field of general video generation, including text-to-video and image-to-video, in generating highly realistic video content. A key factor driving this progress is the large-scale training data, typically presented in the form of video-text pairs. Expanding the training dataset allows the DiT network to learn motion priors of various objects and scenes, demonstrating strong generalization capabilities during inference.
Overview
End-to-end human animation, such as audio-based conversational human generation, has seen significant advancements in recent years. However, existing methods still face challenges in scaling up to large general video generation models, limiting their potential in practical applications. This paper introduces OmniHuman, a diffusion transformer-based framework that expands data by mixing motion-related conditions into the training phase. To this end, we introduce two training principles for mixed conditions and the corresponding model architecture and inference strategy. These designs enable OmniHuman to fully leverage data-driven motion generation, ultimately achieving highly realistic human video generation. More importantly, OmniHuman supports various portrait content (close-ups, portraits, half-body, full-body), supports dialogue and singing, handles human-object interactions and challenging body poses, and adapts to different image styles. Compared to existing end-to-end audio-driven methods, OmniHuman generates not only more realistic videos but also provides greater flexibility in input. It also supports multiple driving modes (audio-driven, video-driven, and combined driving signals).
Methods and Models
In this section, we introduce our framework OmniHuman, which adopts motion-related condition mixing during network training to expand the training data. First, we provide an overview of the framework, including its inputs, outputs, and key design elements. Next, we focus on the design of omni-conditions, covering audio, pose, and reference conditions. We then detail OmniHuman’s training strategy, which utilizes these omni-conditions for mixed data training, allowing the model to learn natural motion from large-scale datasets. Finally, we describe the implementation details of the OmniHuman model during the inference phase.
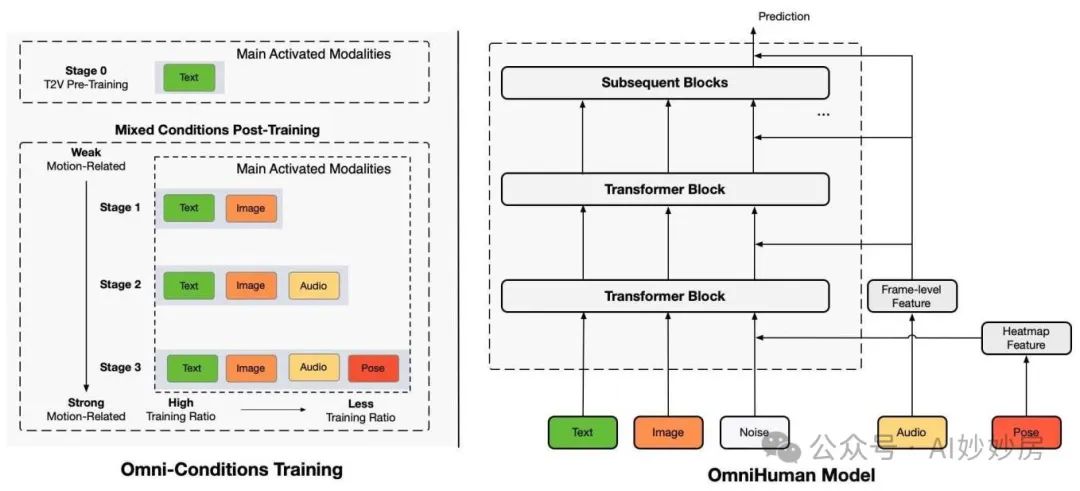
Figure 2. The OmniHuman framework. It consists of two parts: (1) the OmniHuman model, based on the DiT architecture, supporting simultaneous conditional processing using multiple modalities including text, images, audio, and poses; (2) the omni-conditions training strategy, employing progressive multi-stage training based on the conditional motion relevance. Mixed condition training enables the OmniHuman model to benefit from the expansion of mixed data.
1. Overview
As shown in Figure 2, our approach consists of two main parts: the OmniHuman model, a multi-condition diffusion model, and the Omni-Conditions training strategy. For the model, the OmniHuman model starts with a pre-trained Seaweed model [35], which uses MMDiT [14, 42] and was initially trained on general text-video pairs for text-to-video and text-to-image tasks. Given a reference image, the OmniHuman model aims to generate human videos using one or more driving signals (including text, audio, and pose). To this end, we adopt various strategies to integrate frame-level audio features and pose heatmap features into the OmniHuman model. The detailed process will be explained in the following subsections. The OmniHuman model utilizes causal 3DVAE [80] to project videos into latent space at their original size [12] and employs flow matching [36] as the training objective to learn the video denoising process. We adopt a three-stage mixed condition post-training method to gradually transform the diffusion model from a general text-to-video model to a multi-condition human video generation model. As shown on the left side of Figure 2, these stages introduce driving modalities of text, audio, and pose sequentially based on their motion relevance, from weak to strong, balancing their training ratios.
2. Omni-Conditions Design
Driving Conditions. We adopt different approaches to inject audio and pose conditions. For audio conditions, we use the wav2vec [1, 45] model to extract acoustic features, which are then compressed using MLP to align with the hidden size of MMDiT. The features for each frame are concatenated with audio features from adjacent timestamps to generate the audio tokens for the current frame. As shown in Figure 2, these audio tokens are injected into each block of MMDiT through cross-attention, allowing interactions between audio tokens and noisy latent representations. To incorporate pose conditions, we use a pose guider to encode the driving pose heatmap sequences. The generated pose features are concatenated with features from adjacent frames to obtain pose tokens. These pose tokens are then stacked along the channel dimension with the noisy latent features and input into the unified multi-condition diffusion model for visual alignment and dynamic modeling. The text condition remains the same as the text branch of MMDiT.
Appearance Conditions. The goal of OmniHuman is to generate video outputs that preserve the identity of the subject while retaining background details from the reference image. To this end, previous studies have proposed various strategies for injecting appearance representations into the denoising process. The most widely adopted approach involves using a reference network [26, 34, 54], which is a parallel trainable copy of the entire diffusion UNet or DiT, integrated with the self-attention layers of the original denoising network. While this method is effective in transferring appearance features into the denoising process, it requires replicating an entire set of trainable parameters, posing scalability challenges as the model size increases. To address this issue, OmniHuman introduces a simple yet effective reference condition strategy. We do not build additional network modules but reuse the original denoising DiT backbone to encode the reference image. Specifically, the reference image is first encoded into a latent representation using VAE, then the latent representations of the reference and noisy videos are flattened into token sequences. These sequences are then packed together and simultaneously input into DiT, allowing the reference and video tokens to interact through the self-attention of the entire network. To help the network distinguish between reference and video tokens, we modify the 3D rotary position embedding (RoPE) [53] in DiT by zeroing out the temporal components of the reference tokens while keeping the RoPE of the video tokens unchanged. This method effectively combines appearance conditions without increasing additional parameters. In addition to reference images, to support long video generation, we draw on previous methods using motion frames [52], concatenating their features with noisy features.
After introducing these conditions, the motion-related conditions now include text, reference images, audio, and poses. Text describes the current event, reference images define the range of motion, audio determines the rhythm of co-speaking gestures, and poses specify the exact actions. Their relevance strength to human actions can be considered to gradually weaken in this order.
3. Expansion Based on Full Conditional Training
Thanks to the multi-condition design, we can divide model training into multiple tasks, including image and text to video, image and text, audio to video, and image, text, audio, and pose to video. During the training process, different modalities are activated for different data, allowing a broader dataset to participate in the training process, thereby enhancing the model’s generative capabilities. After the conventional text-to-video pre-training phase, we follow two training principles to expand the conditioned human video generation task. Principle 1: During model training, strong conditional tasks can leverage weak conditional tasks and their corresponding data for data expansion. Data excluded from audio and pose condition tasks due to filtering criteria such as lip-sync accuracy, pose visibility, and stability can be used for text and image condition tasks since they meet the standards of weak conditions. Therefore, in Stage 1, we remove audio and pose conditions. Principle 2: The stronger the condition, the lower the training ratio to be used. During training, strong conditions related to motion (such as poses) typically outperform weak conditions (like audio) because they have less ambiguity. When both conditions are present, the model tends to rely on strong conditions for motion generation, hindering effective learning of weak conditions. Therefore, we ensure that the training ratio for weak conditions is higher than that for strong conditions. We construct Stage 2, removing only pose conditions, and in the final Stage 3, we use all conditions. Moreover, the training ratios for text, reference, audio, and pose are gradually halved. This method assigns higher gradient weights to more challenging tasks and prevents overfitting to a single condition during overlapping condition training. Principle 1 allows us to significantly expand the training data, while Principle 2 ensures that the model fully utilizes the advantages of each motion-related condition during mixed condition training and learns their motion generation capabilities. By combining Principles 1 and 2, OmniHuman can effectively leverage mixed condition data for training, benefiting from data expansion and achieving satisfactory results.
4. Inference Strategy
For audio-driven scenarios, all conditions except pose are activated. For combinations related to poses, all conditions are activated, but in cases driven solely by poses, audio is disabled. Generally, when one condition is activated, all conditions with lower motion-related influence are also activated unless unnecessary. During inference, to balance expressiveness and computational efficiency, we specifically apply classifier-free guidance (CFG) [20] across multiple conditions for audio and text applications. However, we observe that increasing CFG leads to noticeable wrinkles in characters, while reducing CFG affects lip-sync and motion expressiveness. To mitigate these issues, we propose a CFG annealing strategy that gradually reduces the amplitude of CFG throughout the inference process, significantly reducing the appearance of wrinkles while ensuring expressiveness. OmniHuman can generate video clips of arbitrary lengths within memory constraints based on the provided reference images and various driving signals. To ensure temporal coherence and identity consistency in long videos, the last five frames of the previous clip are used as motion frames.
Experiments and Results
1. Implementation Details
Dataset. By screening based on aesthetics, image quality, motion amplitude, etc., we obtained hours of human-related data for training. Among them, 13% of the data was selected using lip-sync and pose visibility standards, enabling audio and pose modalities. During training, the data composition was adjusted to fit the full conditional training strategy. For testing, we evaluated according to the portrait animation method Loopy [26] and the half-body animation method CyberHost [34]. We randomly sampled 100 videos from public portrait datasets, including CelebV-HQ [83] (a diverse dataset containing various scenes) and RAVDESS [28] (an indoor dataset containing speeches and songs) as the test set for portrait animation. For half-body animation, we used the test set of CyberHost, which includes a total of 269 body videos, covering 119 identities, involving different races, ages, genders, and initial poses.
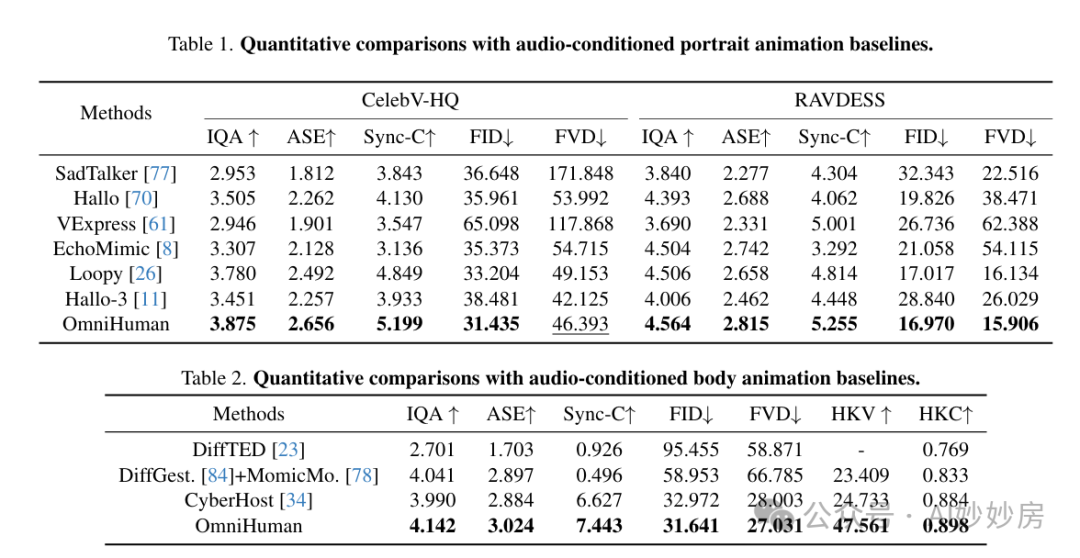
Baseline. To comprehensively evaluate the performance of OmniHuman in different scenarios, we compared it with portrait animation baselines including Sadtalker [77], Hallo [70], Vexpress [62], EchoMimic [8], Loopy [26], Hallo-3 [11], and body animation baselines including DiffTED [23], DiffGest [84] + Mimiction [78], CyberHost [34].
Metrics. For visual quality, we used FID [19] and FVD [59] to assess the distance between generated images and reference images. We also utilized q-align [67], a VLM to evaluate no-reference IQA (Image Quality Assessment) and ASE (Aesthetics). For lip-sync, we adopted the widely used Sync-C [9] to calculate the confidence between visual and audio content. Additionally, HKC (hand keypoint confidence) [34] and HKV (hand keypoint variance) [34] were used to represent hand quality and motion richness, respectively.
2. Comparison with Existing Methods
As shown in Tables 1 and 2, overall, OmniHuman outperforms leading specialized models using a single model for portrait and body animation tasks. For audio-driven animation, the generated results cannot fully match the original videos, especially when the reference image contains only the head. The model’s different preferences for motion styles in different scenarios complicate performance measurement using a single metric. By averaging metrics across the dataset, OmniHuman achieved the best results across all evaluation metrics, reflecting its overall effectiveness. Furthermore, OmniHuman excelled in nearly all metrics on specific datasets. Notably, existing methods use a single model targeting specific body proportions (portrait, half-body) with fixed input sizes and ratios. In contrast, OmniHuman supports various input sizes, ratios, and body proportions, achieving satisfactory results using a single model. This advantage stems from its full conditional training, learning from large-scale diverse content and different sizes during mixed data training.
3. Ablation Study on Full Conditional Training
Here, we primarily analyze and interpret the principles 1 and 2 of full conditional training in OmniHuman. For the first principle, we compared the training data using only data that meets audio and pose animation requirements (i.e., 100% audio training ratio) with training data using weaker conditions (i.e., text). Our experimental results indicate that the ratio of these two parts of data significantly affects final performance. The visual results in Figure 3 clearly show that a high proportion of audio condition-specific data training reduces the dynamic range and may lead to failures with complex input images. However, including weaker condition data at a proportion of can yield satisfactory results (e.g., accurate lip-sync and natural motion). Nevertheless, an excess of weaker condition data can hinder training, reducing relevance to audio. We also conducted subjective evaluations to determine the optimal mixing ratio of these two data types in training. Specifically, we performed blind evaluations where 20 participants compared samples across different dimensions to select the most satisfactory samples, providing a discard option. A total of 50 samples depicting different scenes were evaluated. The results in Table 3 are consistent with the conclusions drawn from visualizations.

The second principle can also be simultaneously verified through experiments of principle 1, but we also conducted another experiment using different pose condition ratios to study the impact of pose condition ratios. Visual comparison results are shown in Figures 4 and 5. When the model is trained with a low pose condition ratio and tested under audio conditions only, the model tends to generate strong, frequent co-speech gestures, as evidenced by the motion blur effect in the first row of Figure 5 and the incorrect fingers in the first row of Figure 4. Conversely, if we train the model with a high pose ratio, the model tends to rely on pose conditions to determine the human poses in the generated video. Therefore, considering the input audio as the only driving signal, the generated results often maintain similar poses, as shown in the bottom rows of Figures 4 and 5. Consequently, we set the pose ratio to 50% as our final training configuration.

Figure 3. Ablation study on different audio condition ratios. The model is trained with different audio ratios (top: 10%, middle: 50%, bottom: 100%) and tested using the same input image and audio in an audio-driven setting.
In addition to analyzing the training ratios of new driving modes in Stages 2 and 3, the training ratio of appearance conditions is equally important. We investigated the impact of reference image ratios on generating 30-second videos through two experiments: (1) setting the reference image ratio to 70%, lower than the text injection ratio but higher than audio; (2) setting the reference image ratio to , lower than the audio and text injection ratios. The comparative results are shown in Figure 6, revealing that a lower reference ratio leads to more pronounced error accumulation, manifested as increased background noise and color shifts, thereby reducing performance. In contrast, a higher reference ratio ensures that the generated output aligns better with the quality and details of the original image. This can be explained by the fact that when the reference image training ratio is lower than audio, the audio dominates video generation, making it difficult to maintain the ID information from the reference image.

Figure 5. Ablation study on different pose condition ratios. The model is trained with different pose ratios (top: 20%, middle: 50%, bottom: 80%) and tested using the same input image and audio in an audio-driven setting.

Figure 6. Ablation study on reference condition ratios. Comparison of visual results for 30-second videos under different reference ratios.
4. Extended Visualization Results
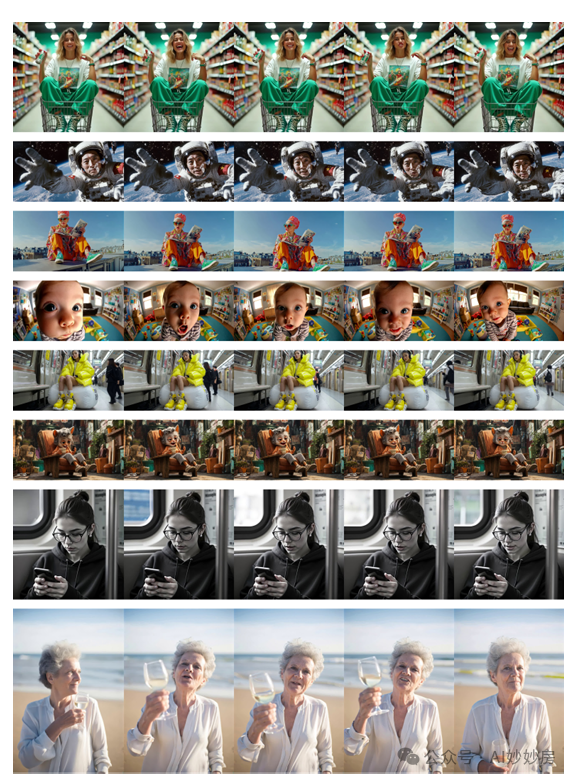
In Figures 7, 8, and 9, we present more visualization results to demonstrate the powerful capabilities of OmniHuman in character animation, which are difficult to reflect through metrics and comparisons with existing methods. OmniHuman is compatible with various input images and can maintain the motion style of the input, such as preserving the lip movements unique to animations. OmniHuman also excels in object interactions, capable of generating videos of natural gestures while singing and playing different instruments or holding objects. Due to its compatibility with pose conditions during training, OmniHuman can conduct pose-driven video generation or joint pose and audio-driven generation. More video samples can be viewed on our project page (highly recommended).

Figure 7. OmniHuman generates videos based on input audio and images. OmniHuman is compatible with stylized humanoids and 2D cartoon characters, even animating non-human images in a personified manner.

Conclusion
We present OmniHuman, an end-to-end multi-modal conditional human video generation framework that can generate human videos based on a single image and motion signals (such as audio, video, or both). OmniHuman employs a mixed data training strategy with multi-modal motion conditions, leveraging the scalability of mixed data to overcome the high-quality data scarcity problem faced by previous methods. It significantly outperforms existing methods and can generate highly realistic human videos from weak signals, especially audio. OmniHuman supports images of any aspect ratio (portrait, half-body, or full-body) and provides realistic, high-quality results in various scenarios.
Acknowledgements
If you find this article helpful or inspiring, please do not hesitate to like, view, and share it to benefit more people. Also, feel free to give a star⭐ to receive my latest updates first. Every interaction is the greatest encouragement for me. Let us move forward together, exploring the unknown and witnessing a hopeful and great future!