
I have an AI assistant named “Lao Liu”. Why? Because it sometimes speaks nonsense seriously.
That’s right, this is a drawback of large models — “hallucination”. Therefore, LLMs + knowledge base is a solution to the “hallucination” problem.
At the same time, for enterprises, information security must be considered; a privately owned knowledge base obviously cannot utilize public large models. Thus, building a personal/enterprise knowledge base based on a local large model is a great solution.
1. Build a Local Large Model
Install Ollama
First, visit the official Ollama website and download the installation package for your operating system. After downloading, simply install it without any options.
https://ollama.com
Pull the Large Model
On the Ollama website, you can go to the Models page to view the models available for download. The Meta Llama2 7b version requires about 8GB of memory to run. If your conditions are sufficient, you can run the 13b and 70b versions, which correspond to 16GB and 64GB of memory, respectively. In addition to Meta’s Llama model, you can also download other models.
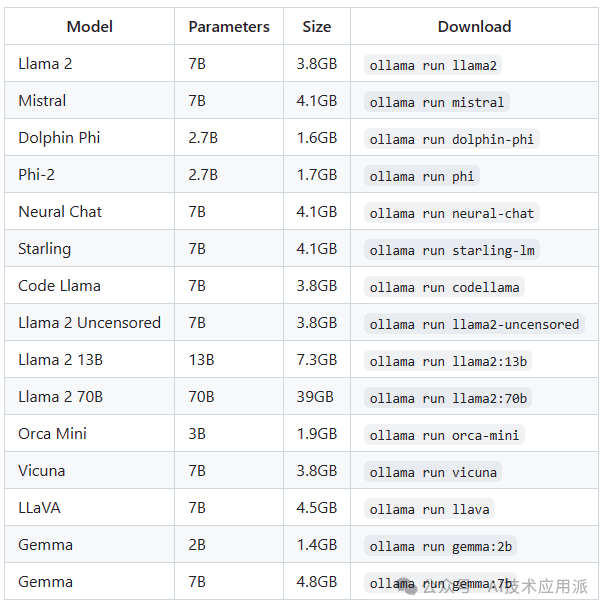
Open the terminal and type the following code to automatically download the model.
ollama run llama2
Once the download is complete, you can directly chat with the large model in the terminal. How easy is that? You now have your own private chat AI.
But isn’t chatting in the terminal a bit unattractive? You might want to chat on a webpage like chatGPT. No problem, let Open WebUI help you with that.
2. Set Up the User Interface
Open WebUI is an extensible, feature-rich, user-friendly self-hosted web user interface designed to run completely offline. It supports various LLM runtimes, including those compatible with Ollama and OpenAI APIs.
Install Docker
Before this, you need to install Docker, which acts like a container, loading the necessary environment and requirements for each project.
First, go to the Docker official website, download the Docker Desktop installation package, and install it.
After the installation is complete, wait for the program to load, and you can enter Docker. If this is your first time using it, there won’t be any projects in Containers.
Install Open WebUI
Having installed Ollama and successfully run the model, you can run the following code in the terminal to start installing WebUI.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main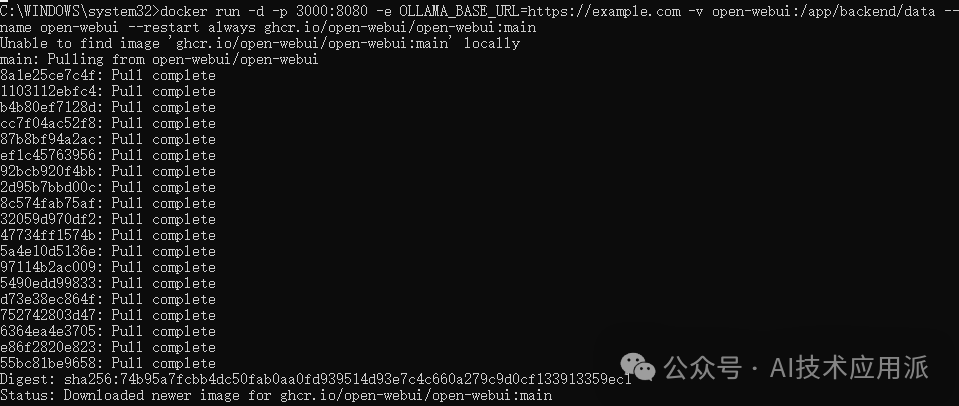
After waiting for the download and installation to complete, you can see the successfully installed WebUI project in Docker Desktop.
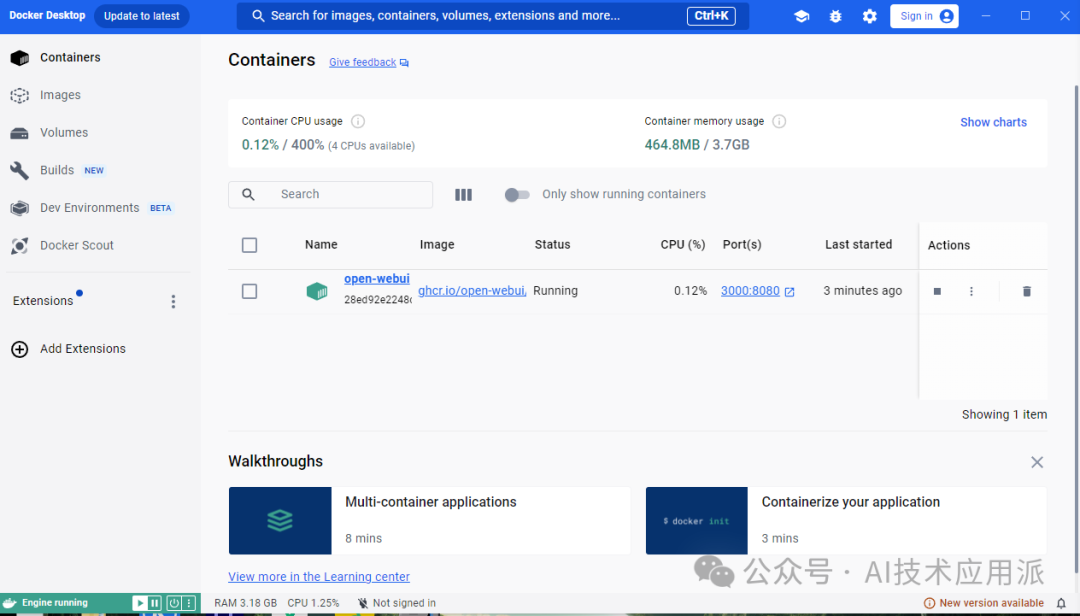
At this point, open any browser and enter:http://localhost:3000 to access WebUI.
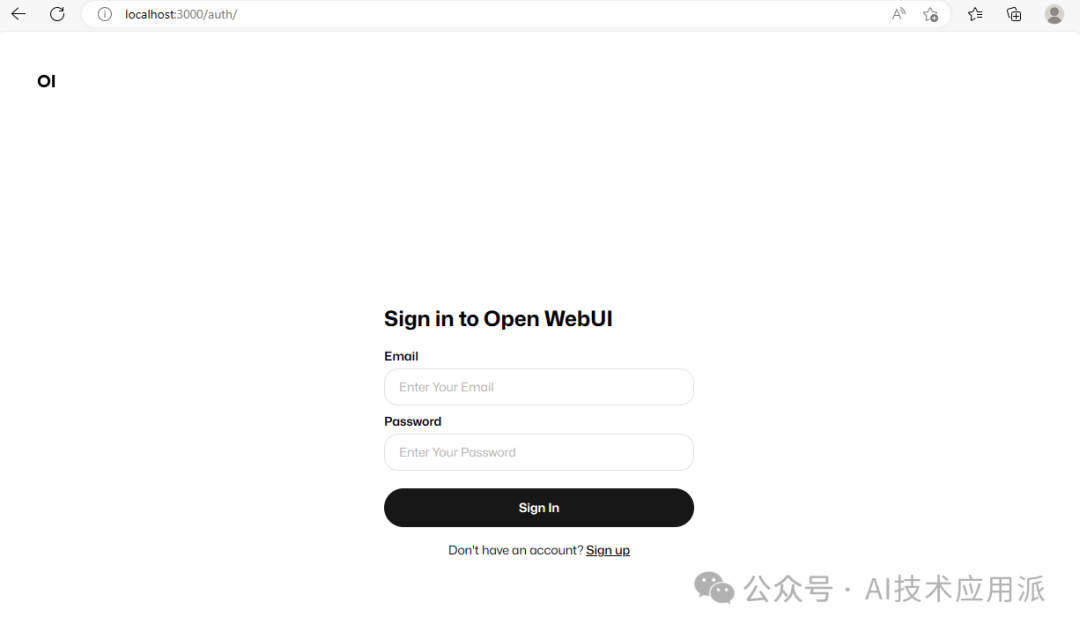
On your first login, register by entering your email and password, and you can log in.
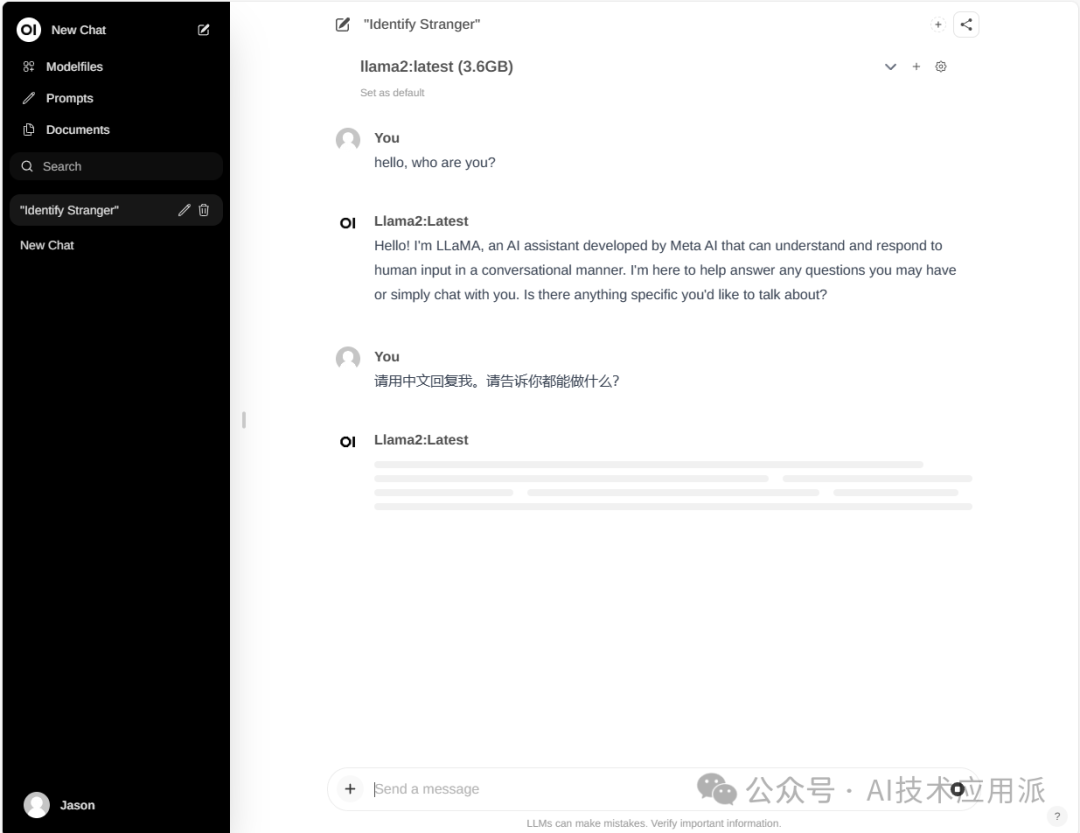
Select the model llama2, and you can start chatting by entering text in the dialog box. Doesn’t the interface look familiar? It’s very similar to chatGPT, making it much more convenient to use.
Open WebUI also has many other features, such as built-in RAG. You can enter “#” followed by a URL in the dialog box to access the implementation information of the webpage and generate content.
You can also upload documents for deeper knowledge interaction based on text. If your requirements for the knowledge base are not high, achieving this will basically meet the needs of most individuals.
3. Connect with the Knowledge Base
If you have greater demands for knowledge base interaction, you can install the following application.
AnythingLLM
https://useanything.com
This is a knowledge base interaction software based on large models that can use local large models or call public large model APIs. The knowledge base can also be local and hardly occupies much resources.
After installation, you will first be asked to configure the large model. Here, you can choose Ollama’s local model, selecting Llama2 7b.
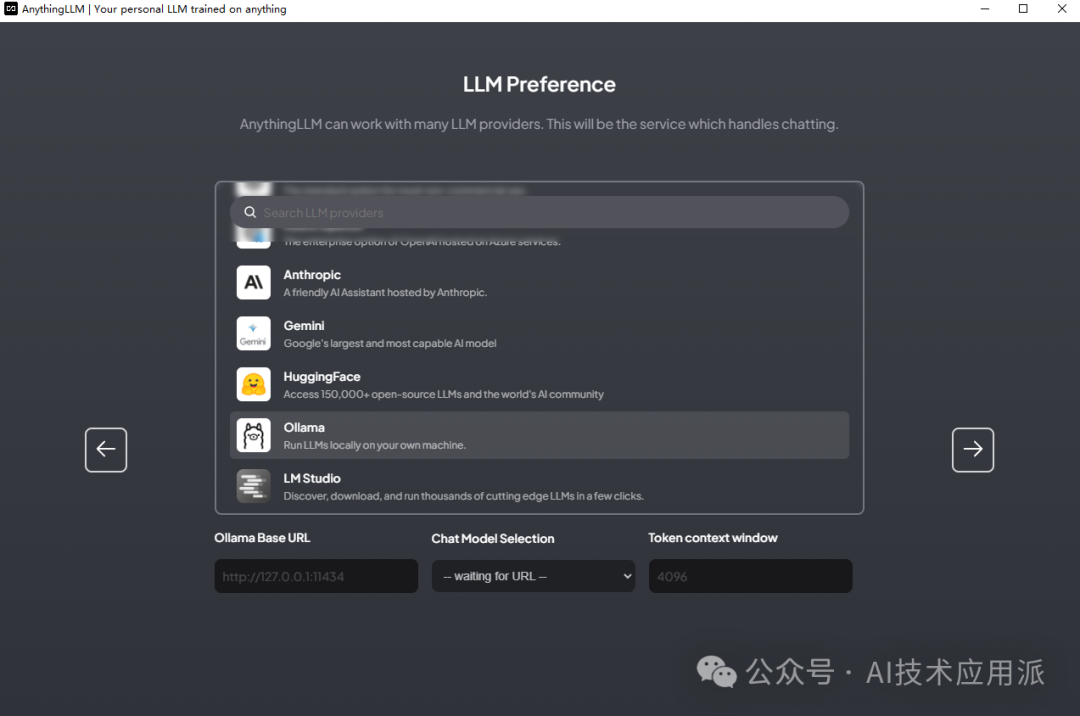
You will then be asked to select the embedding mode and vector database; we can choose the default or connect to an external API.
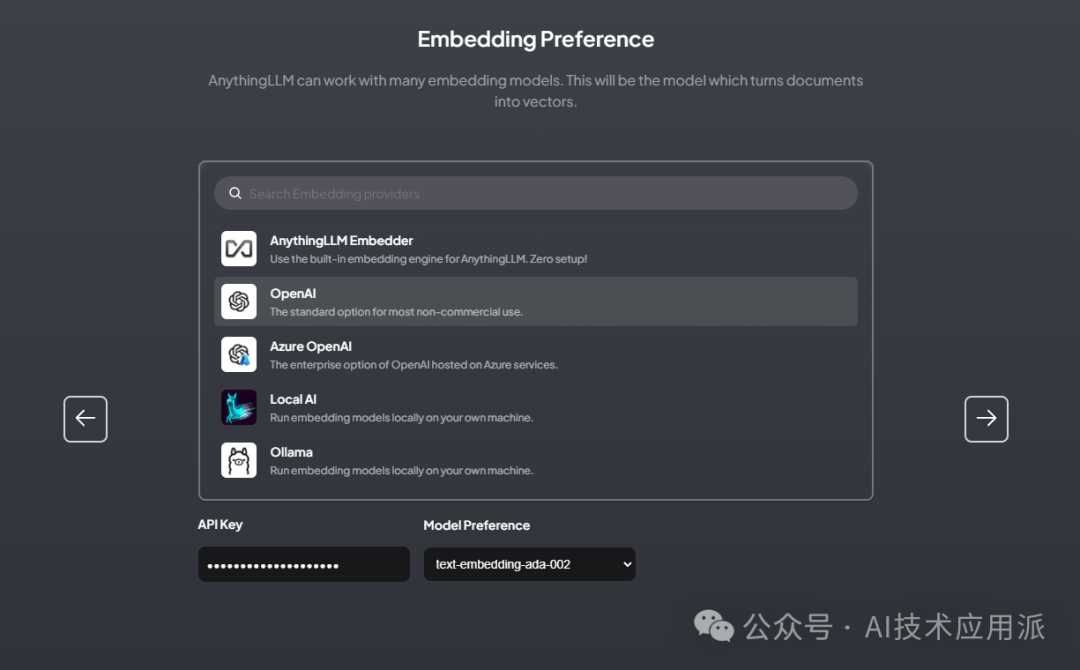
After configuration, give your workspace a name, and you can enter AnythingLLM.
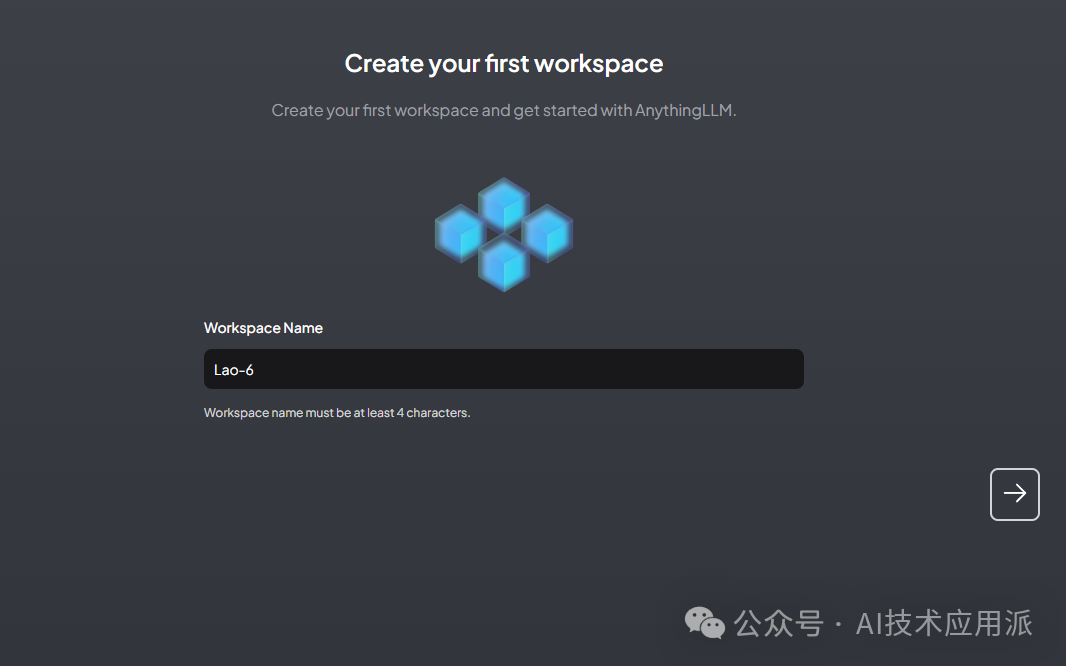
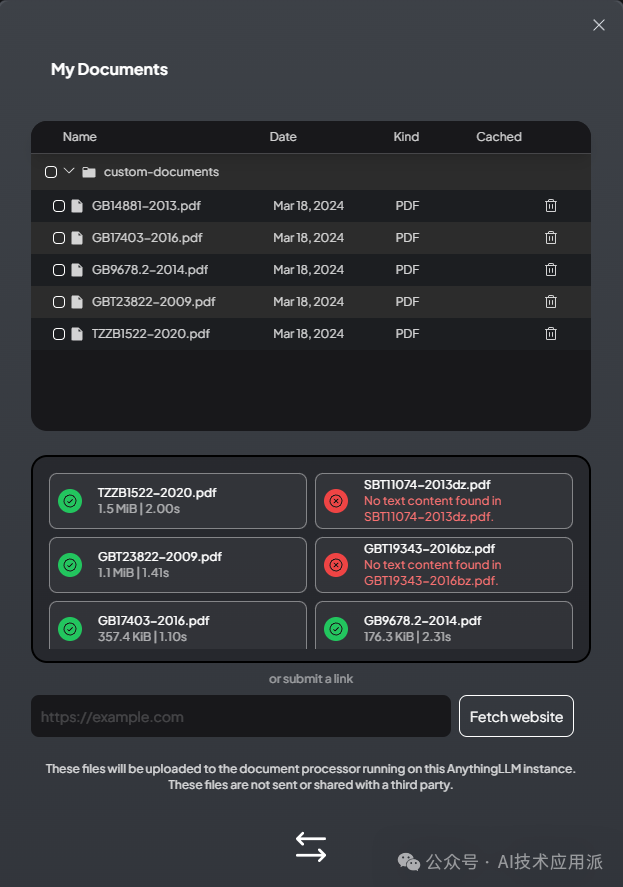
Before officially using it, you need to upload your knowledge documents, supporting various formats, but images in PDF format cannot be read.
Finally, you can chat with your knowledge in the dialog box.
In this way, you have a localized large model that can interact with your own knowledge base, ensuring information security and content reliability. So what are you waiting for? Get it configured now.