
LM Studio is the simplest way to support local open-source large language models. It is plug-and-play, requires no coding, is very simple, and has a beautiful interface. Today, I will introduce this application.
1. What Can LM Studio Do?
-
🤖 Run LLM completely offline on a laptop -
👾 Use models via in-app chat UI or compatible local OpenAI servers -
📂 Download any compatible model files from the HuggingFace 🤗 repository -
🔭 Discover new and noteworthy LLMs on the app’s homepage -
LM Studio supports any ggml Llama, MPT, and StarCoder models on Hugging Face (Llama 2, Orca, Vicuna, Nous Hermes, WizardCoder, MPT, etc.)
Minimum requirements: M1/M2/M3 Mac or Windows PC with AVX2 processor support. Linux is currently in testing.
2. Installation
Currently supports Windows PC, Mac, and Linux. For Windows installation, go directly to the project homepage (https://lmstudio.ai/) to download the corresponding version for Windows and open it to use. The download package is quite large, so leave ample disk space.
3. Model Download
The left side is the sidebar, and the middle is the model download area, which supports direct downloading of huggingface models.
To download, enter the correct model name, for example, to download mixtral.
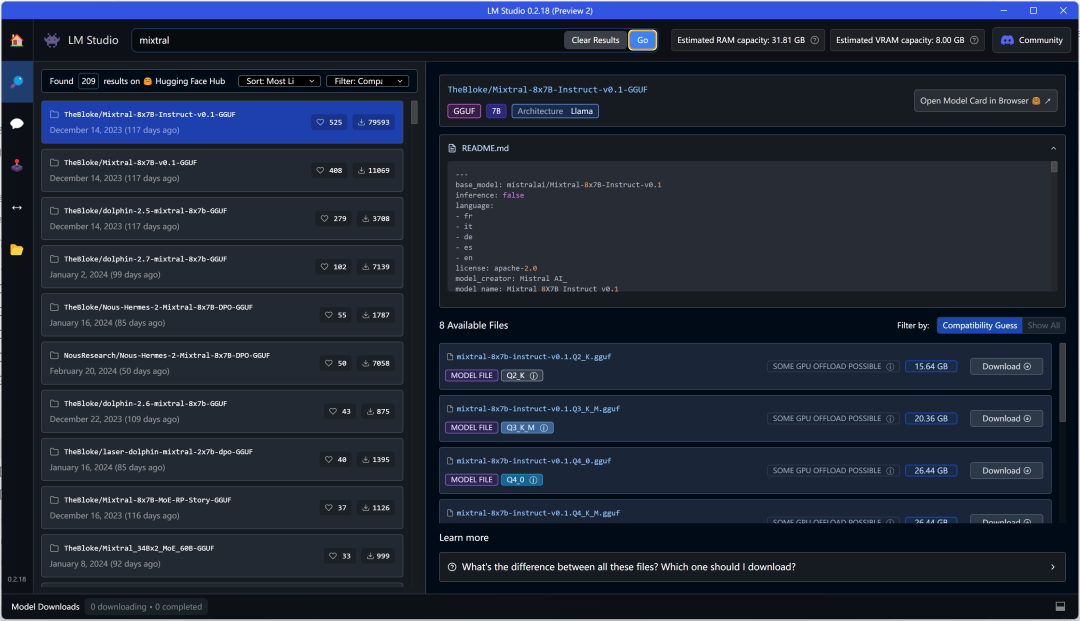
The left side shows all the searched models, and there is a filter box at the top left, which defaults to filtering local compatible models but can also show all models. Below is the provider of each model, model name, number of likes, download volume, etc.
The right side shows detailed information after selecting a model, including various quantized versions of the model, model size, and the option to download by clicking. In the upper right corner is the model card for this model on HuggingFace. At the bottom, there is a Learn More link about the differences between the various versions of the model:
Select # mixtral-8x7b-instruct-v0.1.Q2_K.gguf to download, and at the bottom is the download progress bar, which can be canceled at any time.
4. Chat Functionality
The second bubble icon in the sidebar is the Chat functionality area. 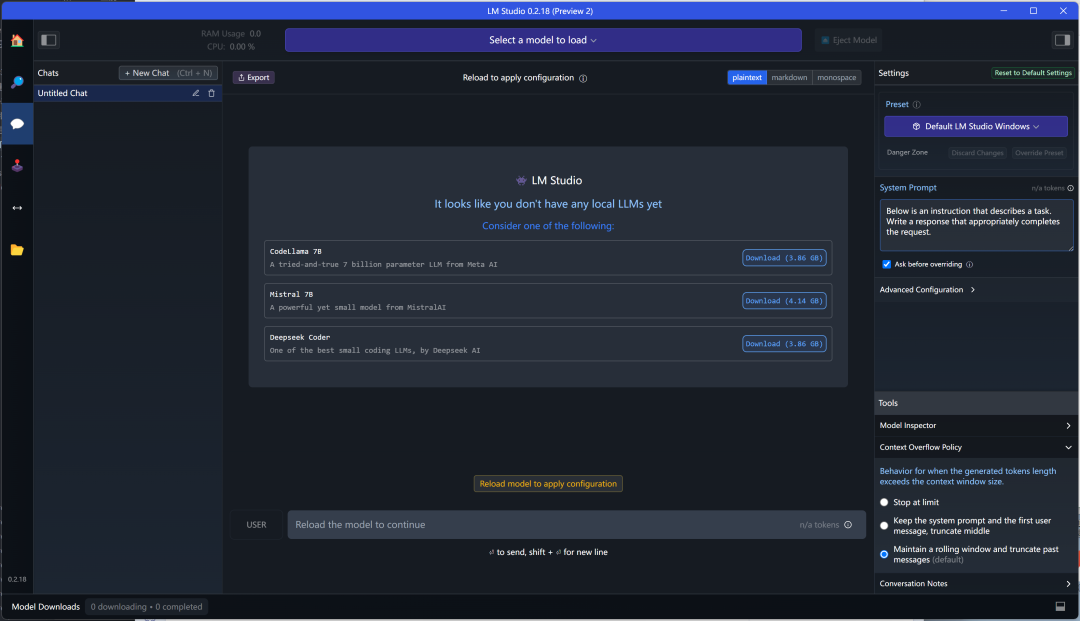 At the top, you can select the downloaded model to chat, and there are recommended models that can be downloaded directly for chatting. The right side is about preset parameters for chatting, such as GPU usage settings, chat context length, temperature settings, and the number of CPU threads allocated, etc. There are also settings for chat roles, system role, user role, assistant role, etc., which can be modified.
At the top, you can select the downloaded model to chat, and there are recommended models that can be downloaded directly for chatting. The right side is about preset parameters for chatting, such as GPU usage settings, chat context length, temperature settings, and the number of CPU threads allocated, etc. There are also settings for chat roles, system role, user role, assistant role, etc., which can be modified.
Select TheBloke/Mistral-7B-Instruct-v0.2-GGUF for a simple chat. 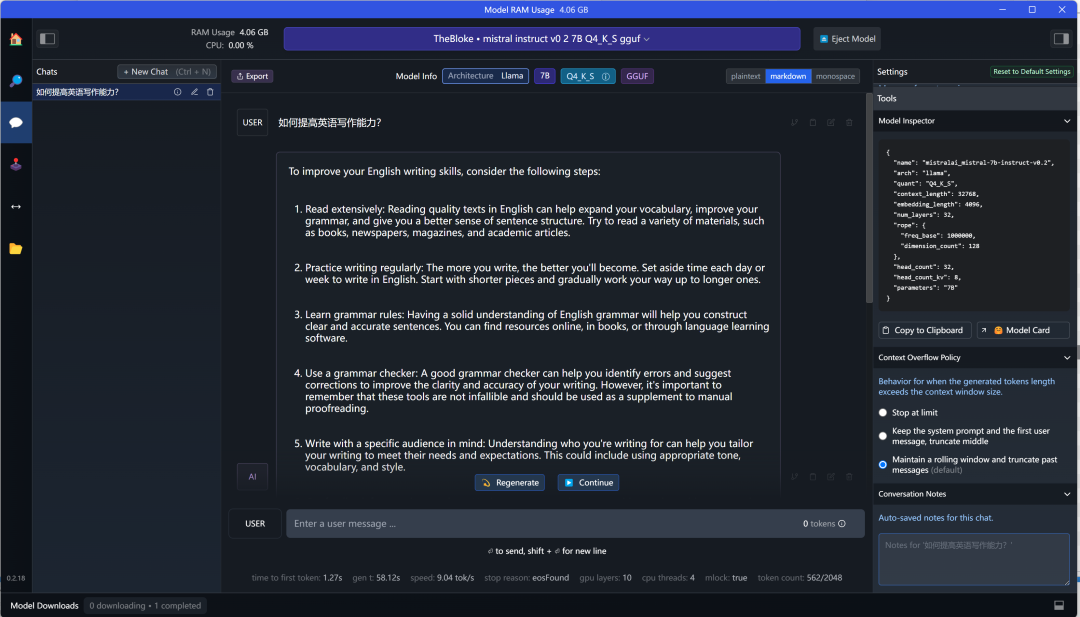
Below the chat is the time taken for this session, how many tokens were consumed, token speed, and other information.
Additionally, GPU is an option; using GPU hardware acceleration can improve inference speed. If you have a GPU, enable GPU usage.
5. Multi-Model Inference
The third button on the left sidebar is for multi-model inference chatting, which loads multiple models at once to answer a question simultaneously.
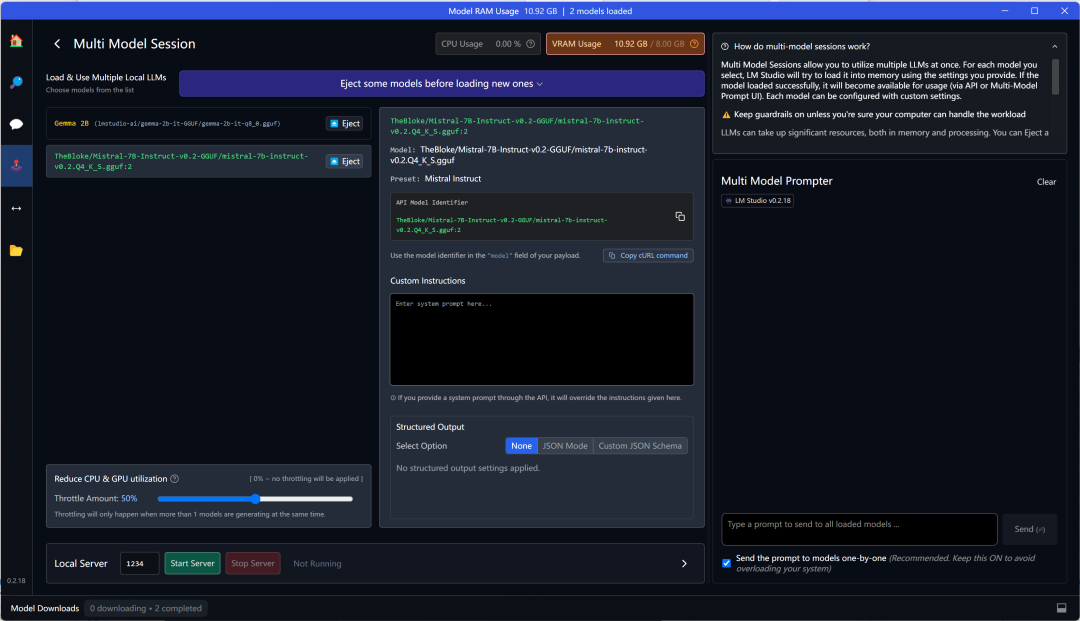
The upper interface shows the situation; the left area is the models used, and you can load them directly. If the models have not been used before, select them from the model selection above, set the model name and preset parameters, and once set, you can load the model.
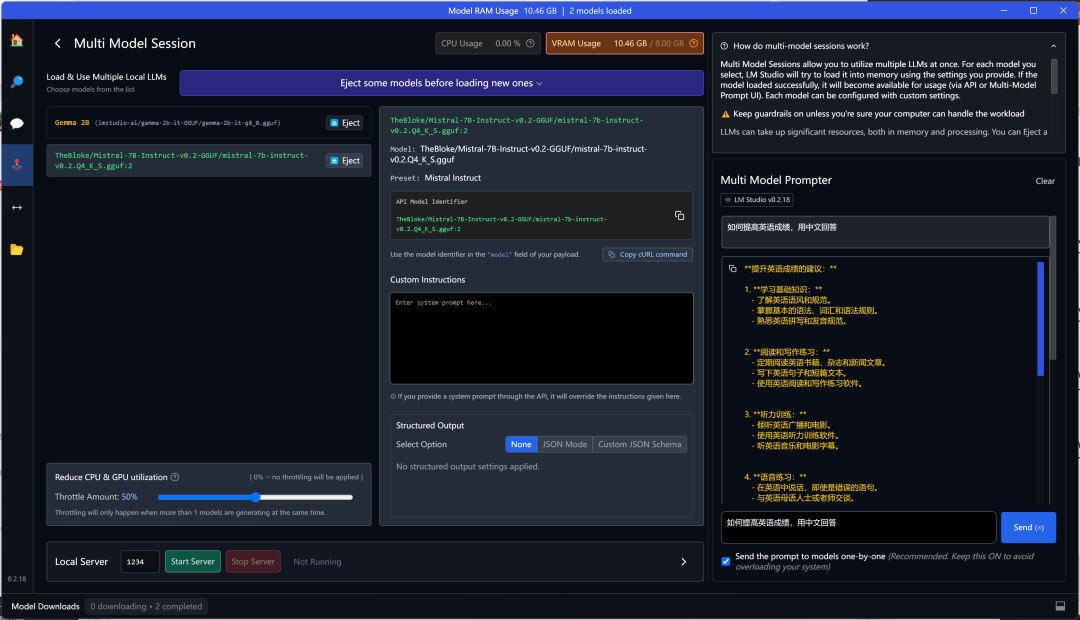
If your hardware configuration is high enough, you can load more models simultaneously. The top shows the CPU and GPU usage. I loaded 2 models, which required 10GB of video memory, exceeding my 8GB video memory limit, so the deficit was supplemented by the CPU.
Once the model is loaded, you can chat on the right side, and in the lower right corner, you can ask questions. The responses will be given in the order of the models listed on the left. Currently, loading 2 models still provides relatively fast response speed. The default output is character format, but you can also choose JSON format output.
This interface also has another feature, which is to provide a web service: 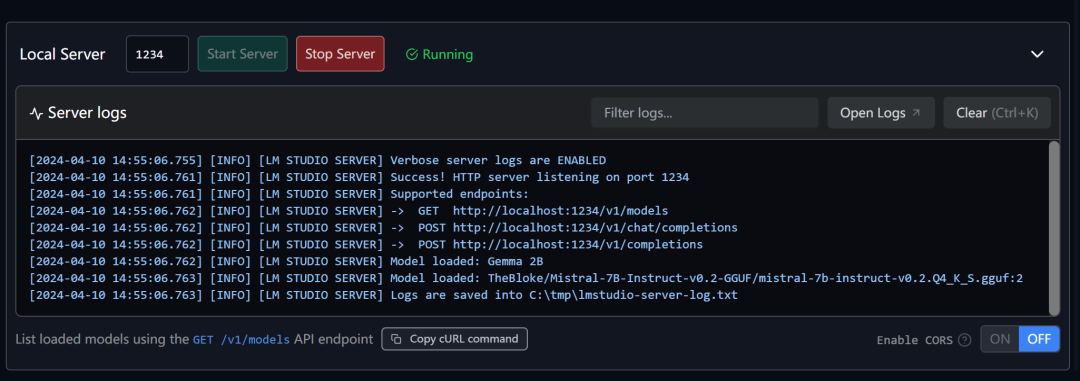
You can define your own port, and after starting the service, you can access it via curl http://localhost:1234/v1/models: 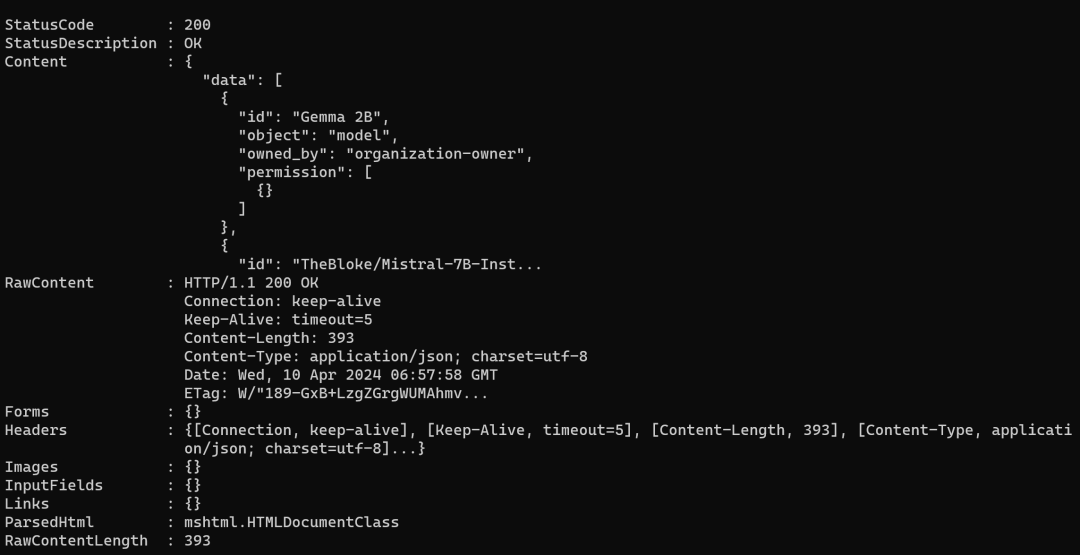
This interface is compatible with the OpenAI interface and can be accessed for testing via Python, JS, or LangChain.
When finished, click Eject next to the model to exit the model loading and stop the service.
6. Local Interface Service
The fifth button on the sidebar is the local interface service. 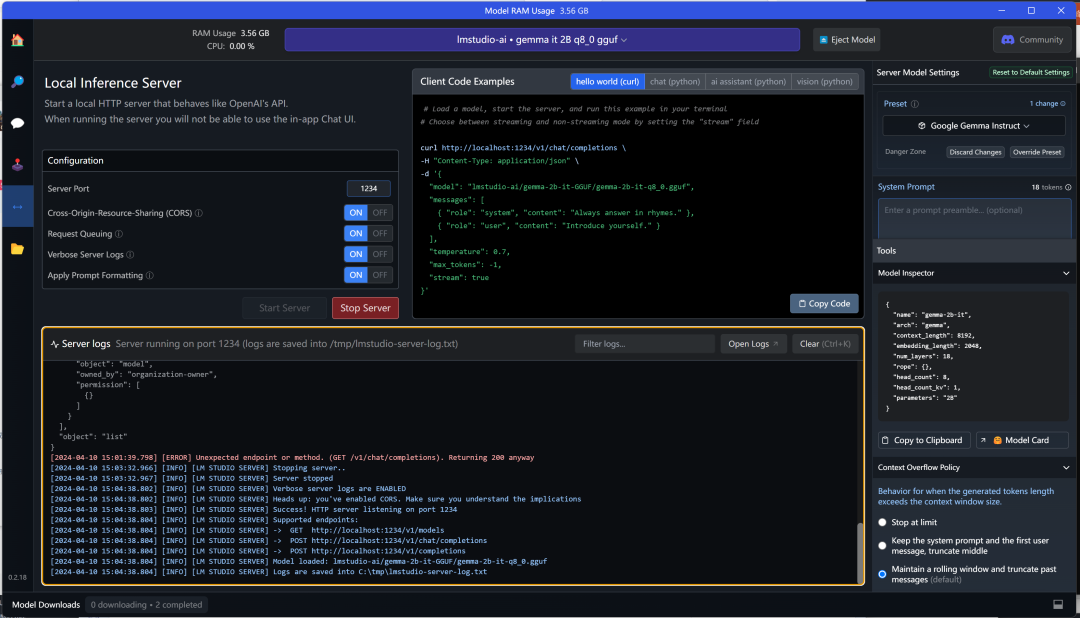 This service is equivalent to ollama serve, but the difference is that ollama serve provides service without specifying a model, while LM Studio requires a specified model to provide service.
This service is equivalent to ollama serve, but the difference is that ollama serve provides service without specifying a model, while LM Studio requires a specified model to provide service.
For example, in the above example, the top shows the loaded model, and there is no GPU option here, showing memory usage of 3.56GB. The Gemma 2b provides local service on port 1234. In the middle part, examples of different application scenarios are provided, such as curl, which can be copied for testing:
curl http://localhost:1234/v1/chat/completions -H "Content-Type: application/json" -d data.json
This code did not run, and I could not figure out how to use curl in Windows.
Let’s try the Python chat code:
# Example: reuse your existing OpenAI setup
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.chat.completions.create(
model="lmstudio-ai/gemma-2b-it-GGUF/gemma-2b-it-q8_0.gguf",
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)

Let’s try the AI assistant mode:
# Chat with an intelligent assistant in your terminal
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
while True:
completion = client.chat.completions.create(
model="lmstudio-ai/gemma-2b-it-GGUF/gemma-2b-it-q8_0.gguf",
messages=history,
temperature=0.7,
stream=True,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print()
history.append({"role": "user", "content": input("> ")})

All services and accesses are logged. If there are any unexplained errors, you can check the log file.
7. Model Management
The sixth button on the left sidebar is model management, where you can download, delete models, and open the model directory. 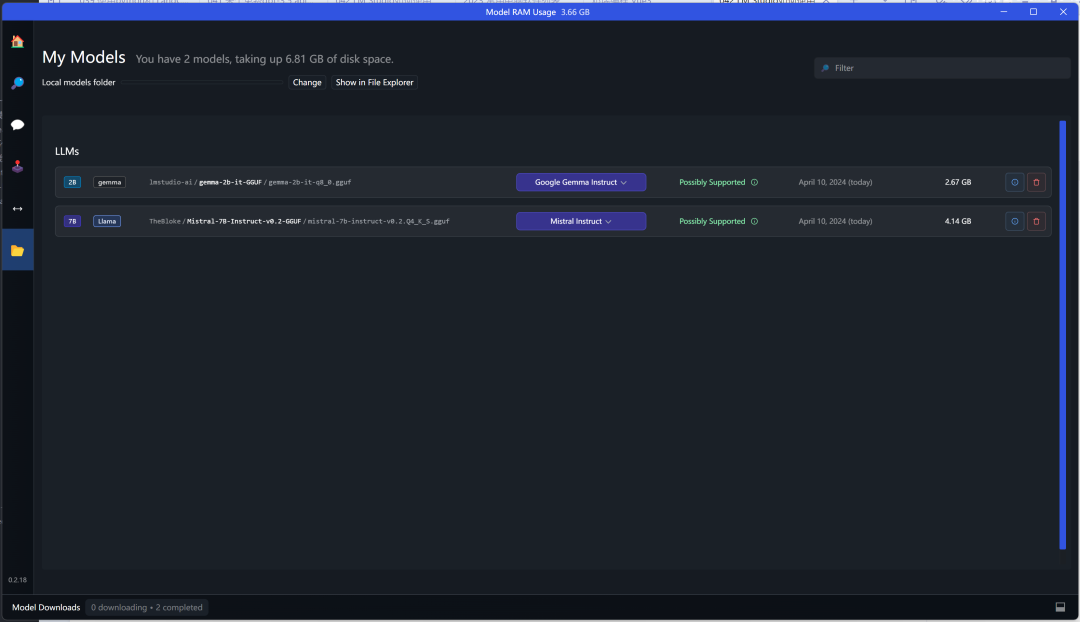
The directory format:
├─lmstudio-ai
│ └─gemma-2b-it-GGUF
└─TheBloke
└─Mistral-7B-Instruct-v0.2-GGUF
The top-level directory is the model provider’s name, the second-level directory is the model name, and the gguf model files are placed underneath. Due to network issues, downloading models from HuggingFace can be very unstable, so you can manually download models and place them in this directory format.
8. Differences Between LM Studio and Ollama
LM Studio supports gguf models on HuggingFace, but it does not support Ollama models, which have their own model format and download platform with a larger number of models. Ollama can import gguf models via the modelfile method. The two platforms are somewhat like PS5 and Switch, each having exclusive models as well as shared models. Ollama has been introduced in previous sessions, and both platforms have their own pros and cons. Excluding model factors, in terms of management and daily usage, LM Studio seems more flexible and easier to use, as all operations are done through a graphical interface, while some configurations in Ollama need to be done via the command line, which is one of their differences.
Regarding ChatOllama, it is a shell for Ollama, currently compatible with OpenAI and some other interfaces. If you are using Ollama, you can use this shell application to access Ollama while also accommodating OpenAI.
The stability of these two platforms has not been tested. If you need stable and continuous service, you may need the Linux version of the software. I have not used it, so I cannot provide specific suggestions.
That’s all for today! Feel free to leave comments and join the discussion group.
9. Text Embedding
Currently, the version I am using (0.2.18) does not support file embedding, but support for text embedding will be provided in version 0.2.19. The local service provides POST /v1/embeddings to achieve embedding through post requests.
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
The embedding models supported are nomic-embed-text-v1.5 and bge-large-en-v1.5.
10. Model Download
HuggingFace provides huggingface-cli for model downloads. Install the cli tool to download the qwen model.
pip install 'huggingface_hub[cli,torch]'
huggingface-cli download Qwen/Qwen1.5-7B-Chat-GGUF qwen1_5-7b-chat-q5_k_m.gguf --local-dir . --local-dir-use-symlinks False

The download speed is quite fast, averaging over 1MB. If you cannot download models using LM Studio, you can try this method.
Change the source for huggingface by setting the environment variable HF_ENDPOINT=https://hf-mirror.com to use third-party mirrors for accelerated downloads. This source change is pending testing; if you have used it, please provide feedback.
Additionally, there is an open-source tool for downloading huggingface models.
git clone https://github.com/LetheSec/HuggingFace-Download-Accelerator.git
cd HuggingFace-Download-Accelerator
python hf_download.py --model lmsys/vicuna-7b-v1.5 --save_dir ./hf_hub
Next, operate your code:
from transformers import pipeline
pipe = pipeline("text-generation", model="./hf_hub/models--lmsys--vicuna-7b-v1.5")
11. Learning and Communication Matrix
Now, various large models are emerging, chatgpt4 is already impressive, and now claude3 has come out, along with open-source large models like ollama, which can run large models on consumer-grade machines. There is also a development framework like LangChain that allows you to quickly set up a chatbot or automate services. Let’s learn about large models! I have formed a group for LLM large model discussions. If you are interested in large models, add me on WeChat, and I will add you to the group. Please make a note when adding me. There are already over 80 people in the group.
Currently, the LLM large model discussion group often has advertisements. Does anyone have methods to filter out those who post ads? To facilitate excluding some advertisers, we ask for a red envelope upon joining the group. If you mind, please do not join. If you add the editor on WeChat to join the group, to avoid awkwardness.
I have been running the PyQt6 Learning Exchange Group 1 for almost a year, and everyone actively exchanges ideas. Now there are over 400 participants, with experts in various fields, forming a great Python PyQt6 exchange ecosystem that has greatly benefited me. The group is relatively loose, and open access can lead to chaos, so now entry to the group is by invitation only. We are forming PyQt6 Learning Exchange Group 2. If you need to join, follow the public account below and enter the group as instructed. The group will periodically distribute learning materials, code, videos, etc.
Additionally, if my writing has helped you, remember to like, share, and click on “View”.
Recently, there has also been a learning group for JavaScript to form a 🏅 International Frontend Technology Discussion Group. If you are interested in learning together, you can join the discussions.

April 10, 2024 evening