Click the above “AI Youdao” and select “Star” public account
Heavyweight content delivered immediately
Editor: Yi Zhen
https://www.zhihu.com/question/337470480
This article is for academic sharing only. If there is an infringement, it will be deleted.
Reports on machine learning algorithms and natural language processing
What Bold and Innovative Neural Network Structures Exist in Convolutional Neural Networks?
Author:Long Peng – Yan You Sanhttps://www.zhihu.com/question/337470480/answer/766380855
You are probably already familiar with basic convolutional structures, well-versed in residual networks, and proficient in grouped convolutions, and you know some model compression techniques, but what we are going to discuss today may not be known to most of you.
We will not discuss popular model structures; today we will introduce several models from various aspects such as convolution methods, channel variations, and topological structures. Students who are determined to write articles in this direction should pay close attention.
1. Gradual Width – Pyramidal Structure
This is a network structure related to the variation of the number of channels.
Generally speaking, the variation in the number of channels in network structures is abrupt. Is there a network where the increase is gradual?This is the pyramidal structure, named Pyramidal Residual Networks.
As we all know, structures like CNN typically increase the number of channels in feature maps as the scale of the feature maps decreases to enhance the expressive power of higher layers, which guarantees model performance. Most models increase the number of channels in feature maps abruptly, for example, from 128 to 256.
Previously, we discussed that randomly reducing the depth of residual networks demonstrated that the depth of deep residual networks is not as deep as imagined. Research in the paper “Residual networks behave like ensembles of relatively shallow networks[C]” also shows that deleting some blocks does not significantly degrade performance, except for downsampling network layers.
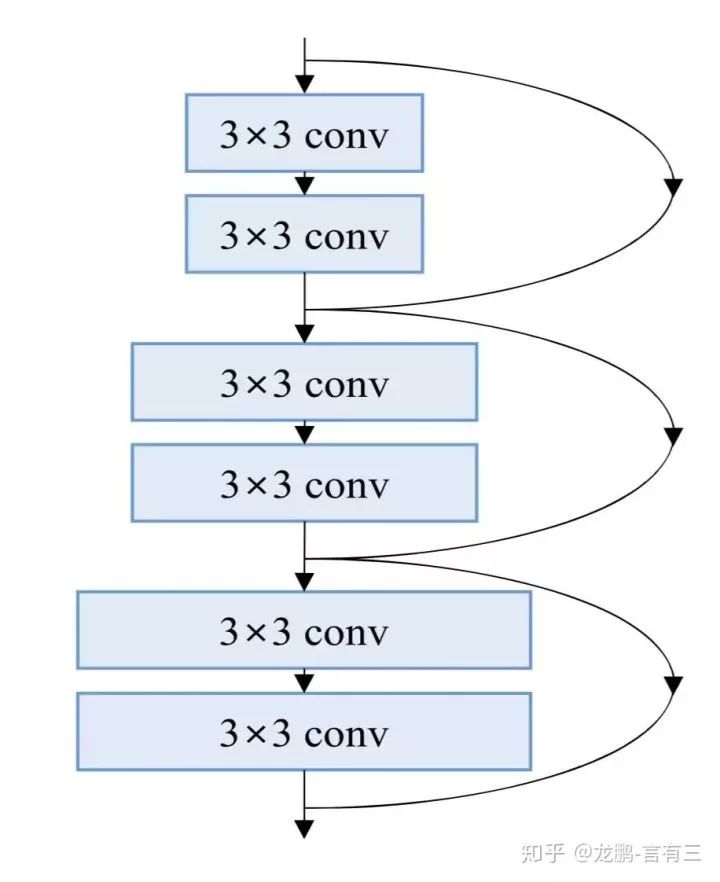
This article is based on this phenomenon, suggesting that to reduce the sensitivity to downsampling, the variation in channels must be gradual, meaning that as the number of layers increases, each layer gradually increases in width, termed the pyramidal structure, as shown below.
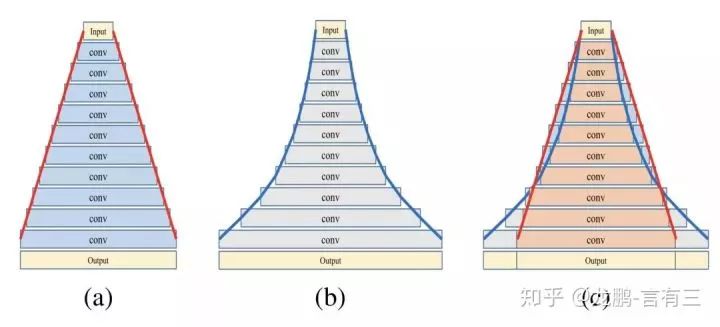
Here, image a shows linear increase, while image b shows exponential increase.
So how is the performance?First, let’s look at the comparison of training curves:
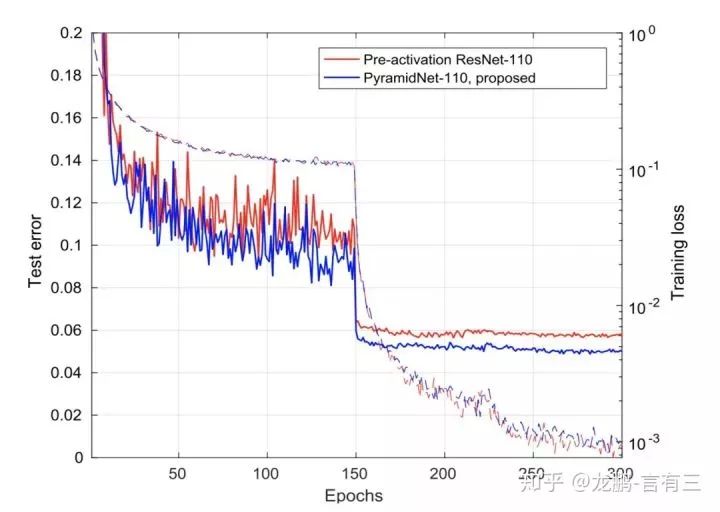
Both networks have similar parameters, around 1.7M, and from the curves, performance is also comparable.
Another point of concern is whether the pyramidal ResNet achieves its original intention of improving performance degradation caused by the deletion of layers that reduce resolution. The results are as follows:
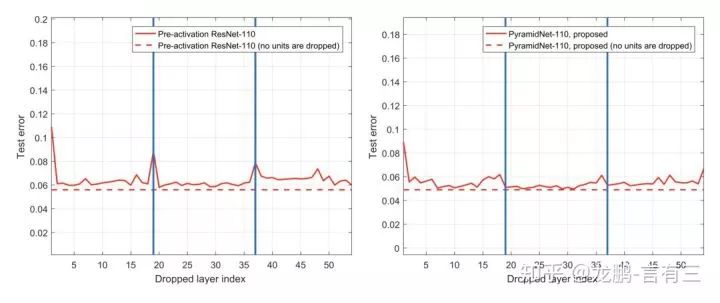
From the results, the error rate has indeed decreased.For more specific experimental results, please refer to the paper yourself.
[1] Han D, Kim J, Kim J. Deep pyramidal residual networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 5927-5935.
2. Many Branches – Fractal Structure
This is a network structure related to multi-branch structures.
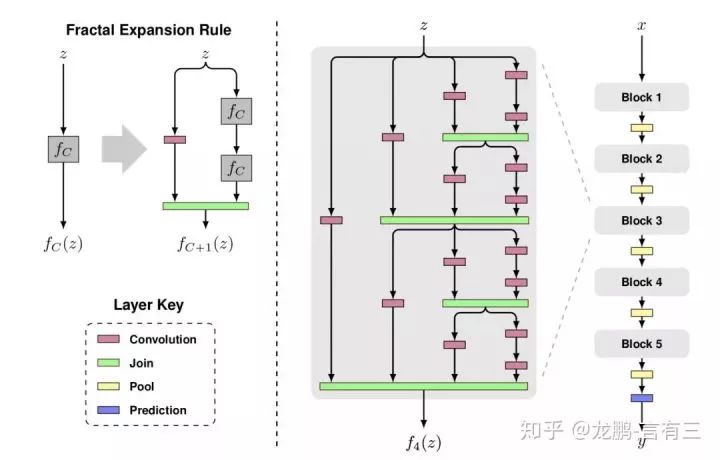
Residual networks make it possible to design networks with thousands of layers, but FractalNet (Fractal Network) can do this as well.
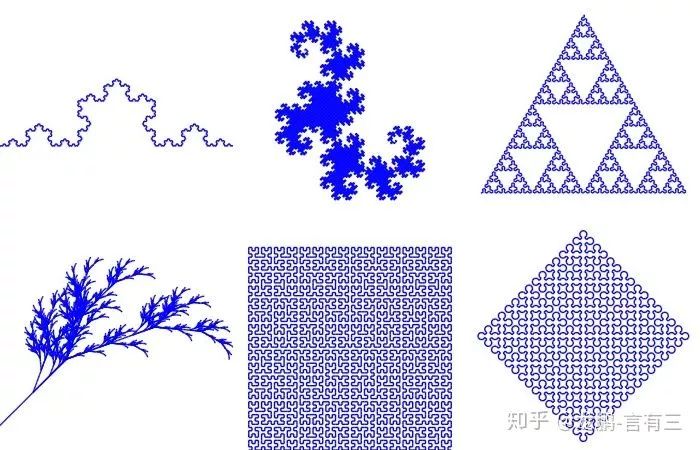
Fractals are a mathematical concept referring to shapes that fill space in a non-integer dimensional form, meaning their effective dimension is not an integer.However, we can ignore its mathematical definition here and focus on its characteristic that part of the fractal geometric structure is self-similar to the whole, as shown in the following figure:
Fractal networks, as the name suggests, also have this characteristic, where the local structure is similar to the global structure, as shown in the figure below:
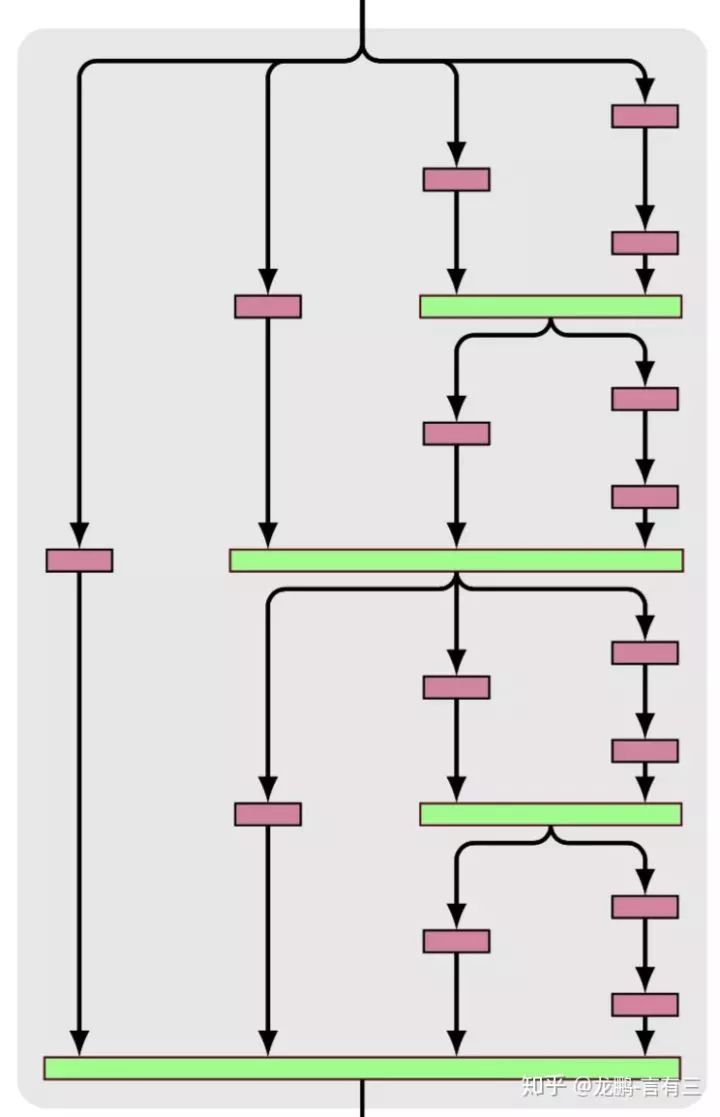
It can be seen that it contains various sub-paths of different lengths, from left to right:
The first column has only one path, of length l.
The second column has two paths, of length l/2.
The third column has four paths, of length l/4.
The second column has eight paths, of length l/8.
Its difference from residual networks lies in the nonlinear transformations represented by the green modules, meaning that the next layer cannot directly obtain the signal from the previous layer, but must go through a transformation.
This type of structure, which contains sub-networks of different depths, is similar to the previously mentioned stochastic depth, and it can also be viewed as an ensemble of networks of different depths.
The authors also conducted experiments by randomly dropping certain depths, as shown in the samples below:
The above shows two paths that are mixed during training.
Global: Only one path is chosen, and it is from the same column; this path is an independent strong prediction path.
Local:It contains multiple paths, but ensures that each layer has at least one input.
So what are the results?
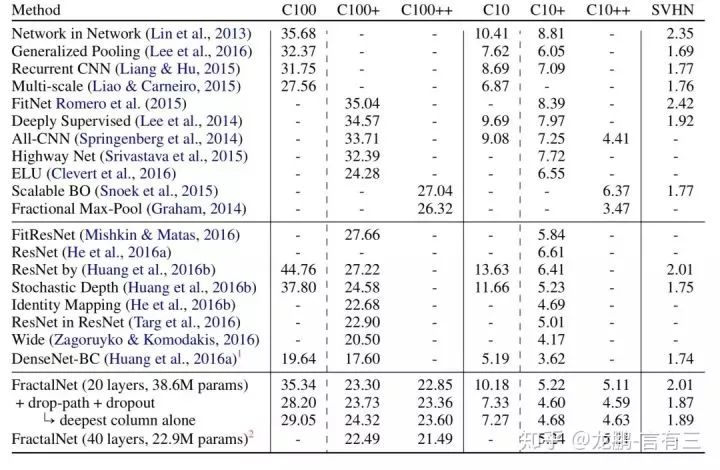
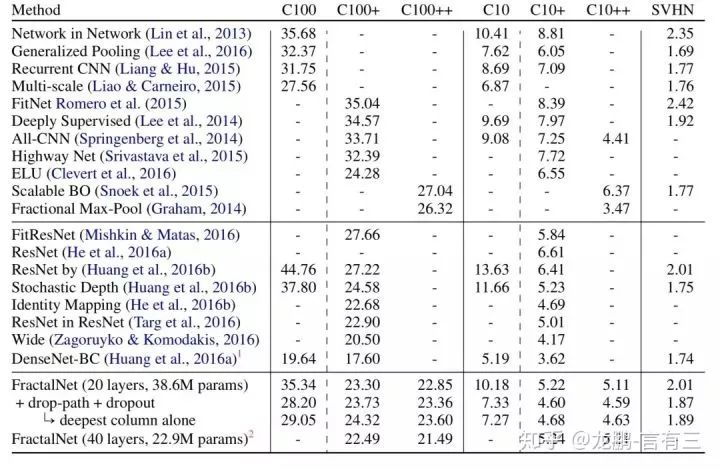
As shown, it performed well compared to various networks.After adding the drop-path technique, there was a significant improvement, and even the network obtained from the deepest path alone performed close to the best model.
Similar to the research on residual networks, the study of fractal networks also indicates that the effective length of the path is the true influencing factor for training deep networks; whether fractal networks or residual networks, they have shorter effective gradient propagation paths, thereby making deep network training less prone to overfitting.
[1] Larsson G, Maire M, Shakhnarovich G. Fractalnet: Ultra-deep neural networks without residuals[J]. arXiv preprint arXiv:1605.07648, 2016.
3. Everything Connectable – Circular Network
This is a complex topological network structure based on skip layers.
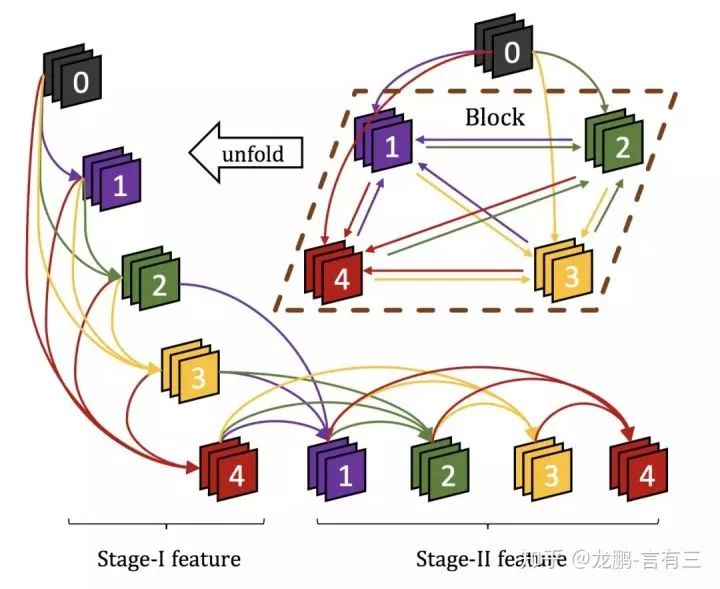
DenseNet improves channel utilization by reusing feature maps of different levels; however, its connections are forward, meaning information can only be transmitted from shallow to deep layers, while CliqueNet takes it a step further, allowing for bidirectional information transmission.
The structure is shown in the above figure; CliqueNet not only has forward transmission but also backward transmission. This network architecture is inspired by recurrent networks like RNN and attention mechanisms, allowing for repeated and refined use of feature maps.
Training CliqueNet involves two phases. The first phase is the same as DenseNet, where shallow features are transmitted to deep layers, which can be seen as an initialization process.
In the second phase, each layer receives feature maps from all previous layers and feedback from subsequent layers. This is a feedback structure that can utilize higher-level visual information to refine the features of earlier layers, achieving spatial attention effects.Experimental results show that it effectively suppresses activations of background and noise.
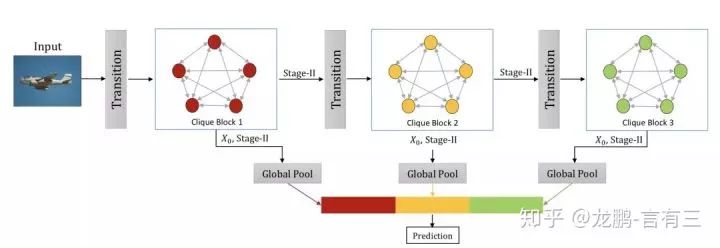
The overall network architecture is shown above:The network is composed of many blocks, and the features of each block’s stage II are concatenated through global pooling to generate the final features.Unlike DenseNet, the input and output feature maps of each block do not need to increase with the network architecture, making it more efficient, as shown in the results below:
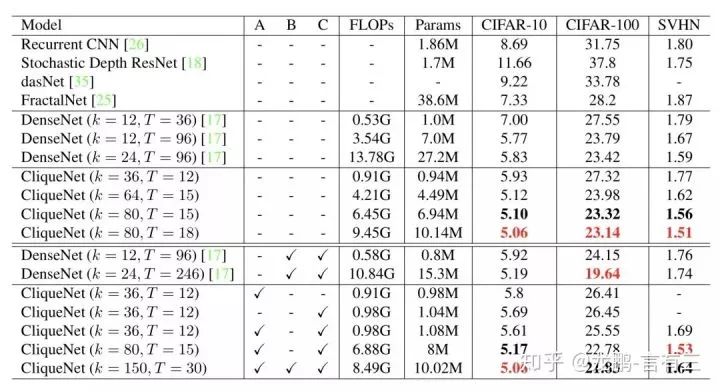
The table shows that the parameter count and accuracy are very advantageous.
[1] Yang Y, Zhong Z, Shen T, et al. Convolutional neural networks with alternately updated clique[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2413-2422.
4. Irregular Convolution Kernels – Deformable Networks
This is a network structure related to the shape of convolution kernels.
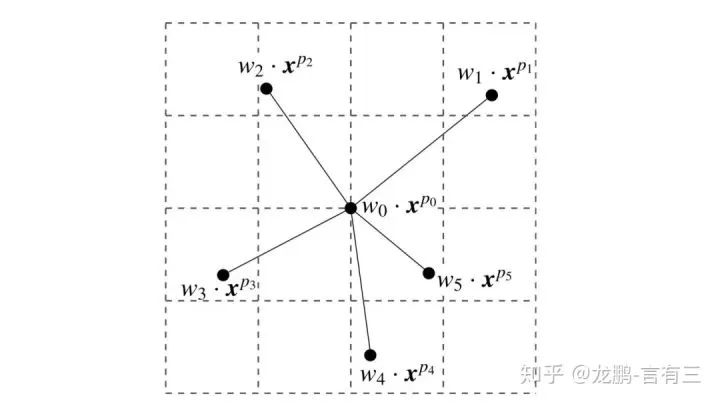
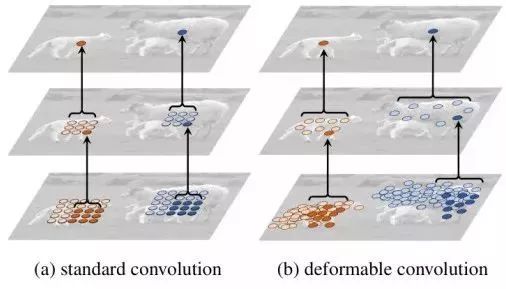
The convolution operation itself has a very fixed geometric structure. The standard convolution operation is a very regular sampling, usually square; if the convolution kernel uses non-regular sampling, meaning its shape is no longer standard square but arbitrary shape, it is called deformable convolution (Deformable Convolution).
To describe the above convolution kernel, it is necessary not only to have weight coefficients but also to have offsets for each point. The idea of deformable convolution was first proposed in the form of Active Convolution.
In Active Convolution, each component of the convolution kernel has its own offset. For a 3*3 convolution, it contains 18 coefficients, with 9 offsets in the X direction and 9 in the Y direction.However, each channel shares this coefficient, so it is independent of the number of input and output channels.
For an input channel of M and output channel of N using a 3*3 convolution in Active Convolution, the weight parameter count is M*N*3*3, and the offset parameter count is 2*3*3, which is much smaller than the weight parameter count, so the increase in parameter count can be ignored.
In Deformable Convolutional Networks, each channel does not share offsets, and the offset parameter count is 2*M*3*3; the increase in parameter count is more than Active Convolution, but compared to the weight parameter count M*N*3*3, it is still much smaller, so it will not significantly increase the model size, and in practical implementation, output channels can be grouped.
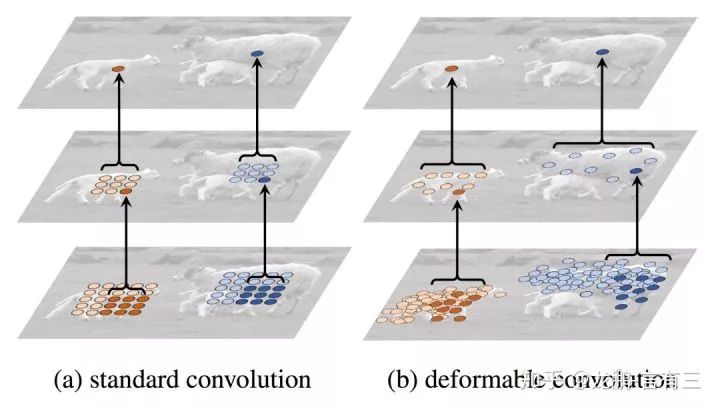
From the above figures, it can be seen that deformable convolution has a more flexible receptive field.
The implementation of deformable convolution only requires the learning of offsets, which is effectively an additional offset layer, allowing us to set the number of output channels for offsets. We can also group the output to control the types of deformations to be learned.
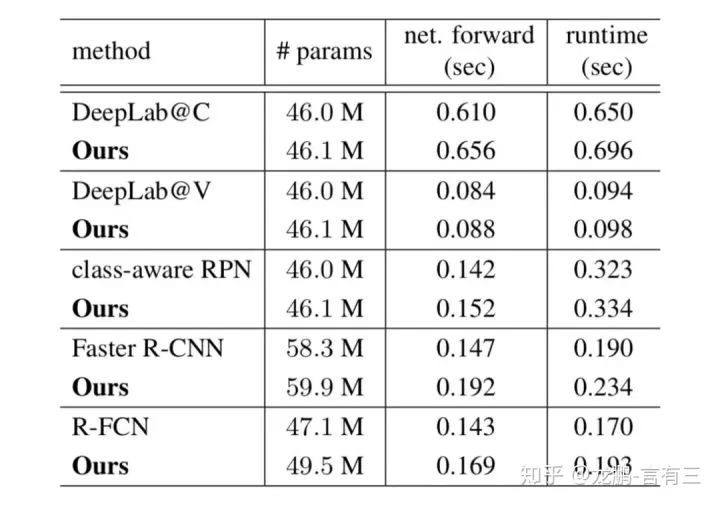
Finally, let’s look at the parameter comparisons and performance.
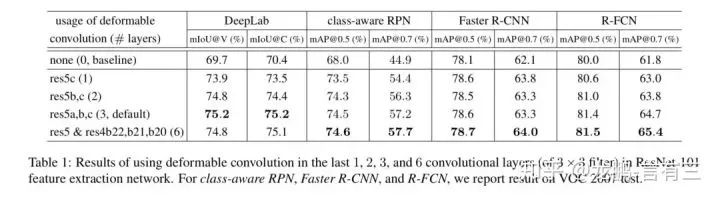
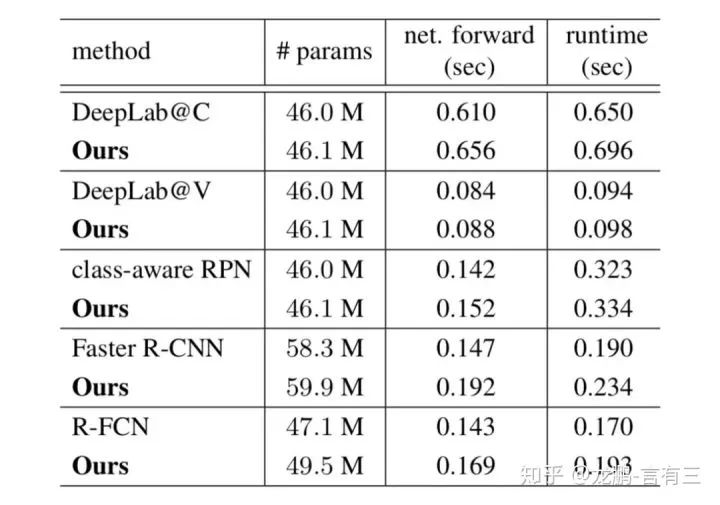
Experiments on various network layers show that the increase in parameter count is small, and performance is also improved.For specific effects, you may verify with your own experimental results.
[1] Jeon Y, Kim J. Active Convolution: Learning the Shape of Convolution for Image Classification[J]. 2017.[2] Dai J, Qi H, Xiong Y, et al. Deformable Convolutional Networks[J]. 2017.
5. Testing Variable Networks – Branching Networks
This is a network structure that dynamically changes during inference.
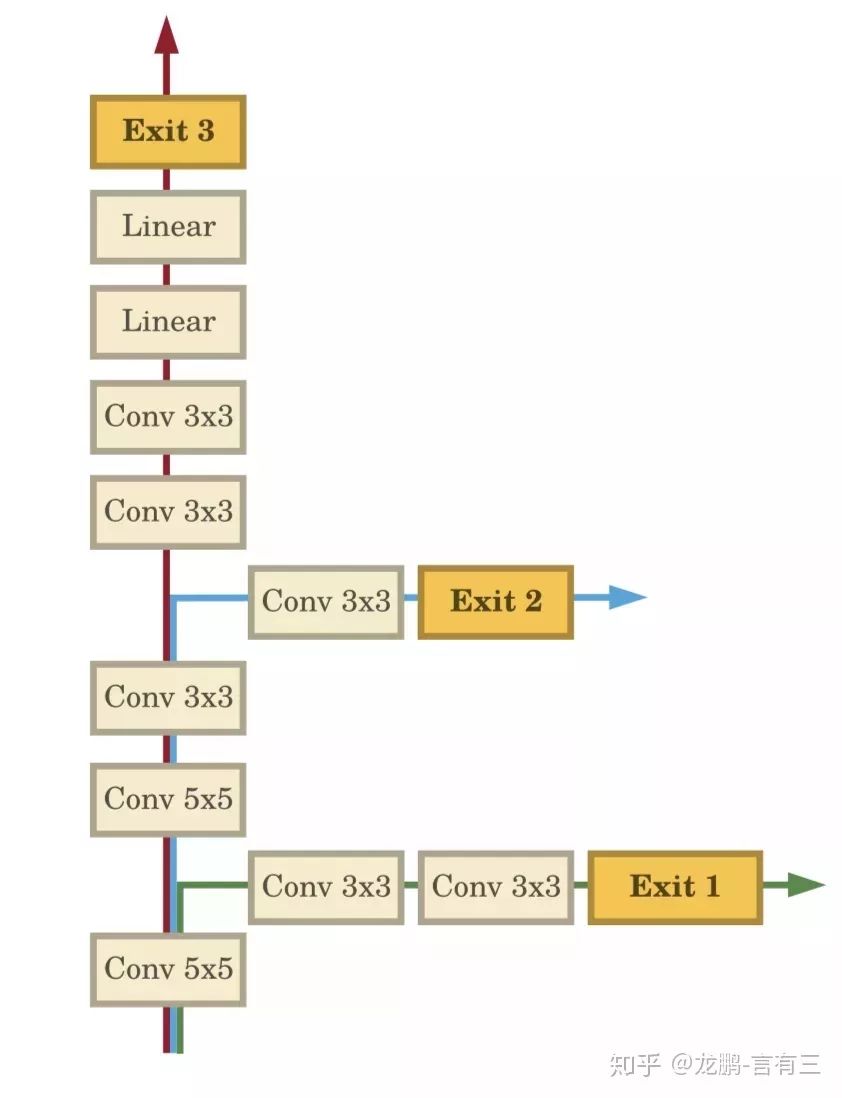
Generally speaking, after model training, the structure is fixed, and during testing, images are computed along fixed paths.However, test samples have different levels of difficulty; simple samples only require a small amount of computation to complete the task, while difficult samples require more computation.
As shown in the figure above, it contains multiple bypass branches alongside the normal network channel. This idea is based on the observation that as the network deepens, its representational power increases, and most simple images can learn sufficient features to recognize at shallower layers, such as the Exit 1 channel in the figure above.Some more difficult samples require further learning, as shown in the Exit 2 channel, while only a few samples need the entire network, as in Exit 3 channel.This idea can achieve a balance between accuracy and computation; for most samples, tasks can be completed with less computational load.
So how do we determine whether we can exit early?In the paper proposing this network, the authors used classification information entropy. Once the classification information entropy of that channel falls below a certain threshold, it indicates that a classification result has been obtained with high confidence, leading to the final channel.
During training, each channel contributes to the loss, with weights closer to shallow layers being larger.The multi-channel loss enhances gradient information and also serves to regularize to some extent.
Applying the design idea of BranchyNet to LeNet, AlexNet, and ResNet structures significantly accelerates performance while maintaining accuracy.
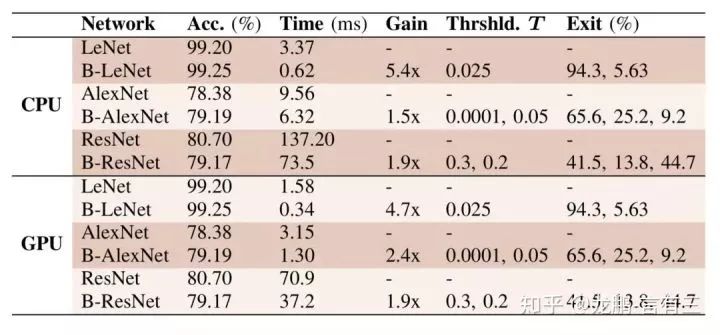
For a network with N branches, N-1 thresholds are needed, as the last branch does not require a threshold.
LeNet series networks can allow over 90% of samples to terminate early at the first branch, while AlexNet’s early termination sample ratio exceeds half, and ResNet’s early termination sample ratio exceeds 40%.
[1] Teerapittayanon S, McDanel B, Kung H T. Branchynet: Fast inference via early exiting from deep neural networks[C]//2016 23rd International Conference on Pattern Recognition (ICPR). IEEE, 2016: 2464-2469.
Author:Reading Core Technologyhttps://www.zhihu.com/question/337470480/answer/768372616
New Operations on Convolutions
Size and Number of Convolution Kernels
It is generally believed that the role of convolution kernels is to capture local features, which combine to make the model easily recognizable.Fixed-size convolution kernels will obtain features of fixed size.
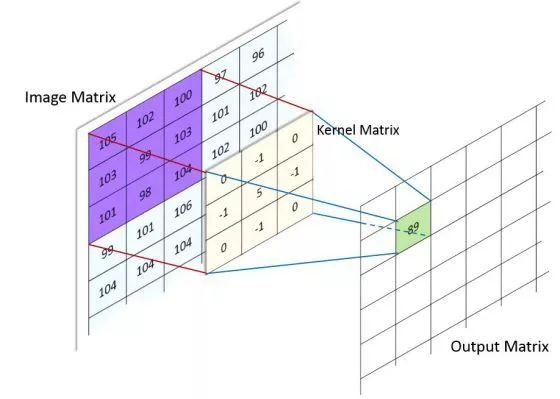
However, in practical tasks, we are unclear about the optimal size of convolution kernels. We can adjust the size of convolutions as hyperparameters, but we also need to adjust their stride and the size of the zero padding area.Additionally, the features of an image are unlikely to be the same size; for instance, the feature area of eyebrows in face recognition is smaller than that of eyes.To better address these two issues, we use convolution kernels of different sizes at the same level to achieve the effect of merging feature areas of different sizes, while also allowing the network to freely select the convolution kernels suitable for the task.
This is how we arrived at the famous Inception Net.
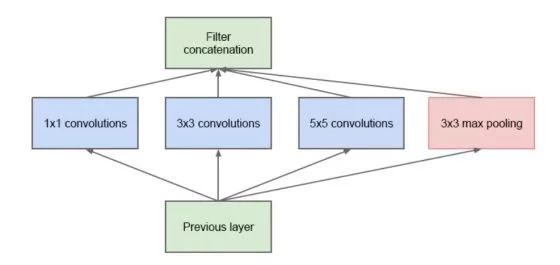
It is worth noting that the 1*1 convolution on the far left mathematically does nothing because it seems to just map to each pixel point sequentially, but its operation lies in the depth dimension because we already know that the depth of the output size depends on the number of convolution kernels. By using a 1*1 convolution kernel, we can change the depth without altering the width and height, which can be seen as a form of dimensionality reduction.
Separation of Convolution Kernels
The convolution operation applies to each channel of the image, meaning that in the same input image, different channels also share parameters. Such sharing may impose certain limitations, as some features may be more sensitive to certain channels. If we want to account for different channels needing to extract different features, we can use different convolution kernels, which is called depth-wise separable convolution.
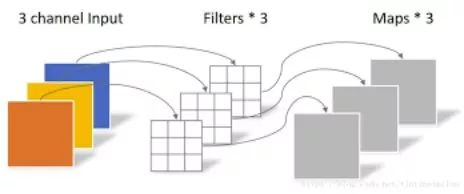
This is also what Xception does. Naturally, for each channel, we can still use multiple convolution kernels simultaneously.
Shape of Convolution Kernels
The convolution kernels we typically see are square. To effectively adapt to tasks, we can also design them as rectangular, and the convolution process remains the same, although we may need to set the strides for left-right and up-down.Even in Inception, using convolution kernels of different sizes, their shapes remain fixed. If our convolution kernels can adapt well to the shapes of features that need to be extracted from images, their efficiency may significantly improve compared to Inception.
Thus, we modify the convolution operation from one-to-one mapping to convolution kernels that no longer compute the projected area but instead have offsets for each mapping point. We call this type of convolution deformable convolution (deformable convolution).
Recommended Reading
(Clicking the title will redirect to read)
Comprehensive AI Learning Path, the most detailed resource organization!
Heavyweight | Selected historical articles from the public account
My Deep Learning Introductory Path
My Machine Learning Introductory Roadmap
Important! AI Youdao Academic Exchange Group has been established!
Scan the QR code below, add AI Youdao Assistant WeChat, and you can apply to join the Lin Xuantian Machine Learning Group (number 1), Wu Enda deeplearning.ai Learning Group (number 2). Be sure to note:Which group to join (1 or 2 or 1+2) + Location + School/Company + Nickname. For example:1+Shanghai+Fudan+Little Cow.

Long press to scan and apply to join the group
(Due to a large number of people adding, please be patient)
The latest AI heavyweight content, Iam reading 